PDF文件因其高度的跨平台兼容性和安全稳定的格式特点,广泛应用于企业文档管理和电子资料传输中。随着PDF文档页数和内容复杂度的增加,拆分PDF成为优化文档处理流程、提升办公效率的重要需求。通过编程方式实现PDF拆分,不仅能自动化处理海量文档,还能根据需求精准提取指定页面、按页码范围分割,甚至基于关键字内容智能拆分,大大提升了工作效率和准确性。
本文将详细讲解如何使用 Spire.PDF for .NET 库在C# 中实现多种PDF拆分功能,包含按每页拆分、按页码范围拆分、按关键字拆分及提取指定页面等场景的完整示例代码,帮助开发者轻松掌握高效的PDF分割技巧,优化文档管理流程。
获取Spire.PDF for .NET 免费试用版,欢迎联系慧都科技。
加入Spire技术交流QQ群(125237868),与更多开发者一起提升文档开发技能。
为什么要以编程方式拆分 PDF?
通过代码拆分 PDF 相比手动操作具有显著优势,包括:
- 自动生成报表
- 提高企业流程中的文档处理效率
- 便于内容归档或重新分发
- 根据用户或系统输入动态处理文档
此外,这种方式可减少人为错误,提高重复性任务的一致性。
准备工作
在编写代码之前,请确保你已具备以下环境和工具:
- 已安装 .NET Framework 或 .NET Core
- 安装 Visual Studio 或其他 C# 开发环境
- 已安装 Spire.PDF for .NET 库
- 具备 C# 编程基础
安装 Spire.PDF for .NET 库
Spire.PDF for .NET 是一款专业的 .NET PDF 库,支持在不安装 Adobe Acrobat 的情况下创建、读取、编辑及操作 PDF 文件。它支持多种PDF功能,如拆分、合并、文本提取、添加注释等。
你可以通过 NuGet 包管理器快速安装该库:
Install-Package Spire.PDF
或在 Visual Studio 中通过图形界面安装:
- 右键点击项目 > 管理 NuGet 程序包
- 搜索 Spire.PDF
- 点击“安装”
C# 拆分 PDF 的方法与代码示例
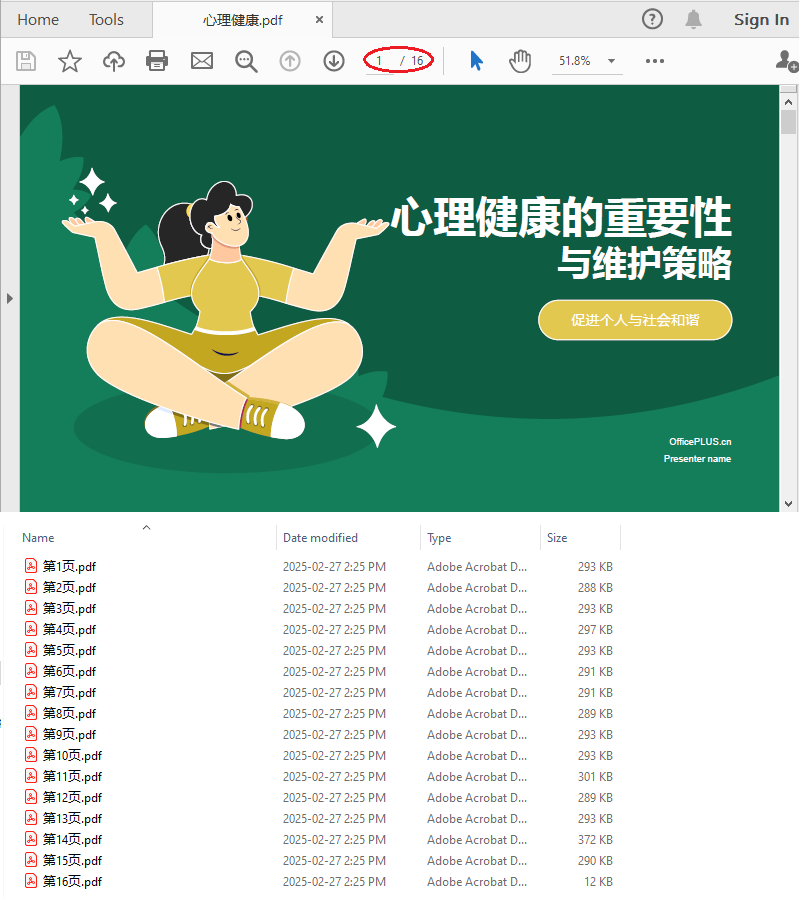
按每一页拆分 PDF
当你需要将 PDF 拆分为多个单页文件时,可使用 Split 方法。该方法可以快速将每一页保存为单独的文件,便于批量处理或单页分发。
using Spire.Pdf;
namespace SplitPDF
{
class Program
{
static void Main(string[] args)
{
PdfDocument pdf = new PdfDocument();
pdf.LoadFromFile("心理健康.pdf");
// 将每页拆分为单独的 PDF 文件
pdf.Split("第{0}页.pdf", 1);
pdf.Close();
}
}
}
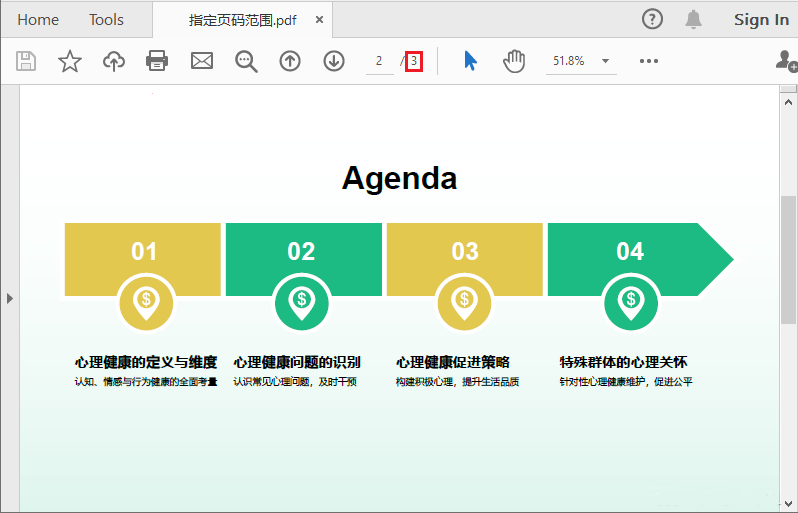
按页码范围拆分 PDF
在实际应用中,常常需要将文档按特定页码范围拆分成多个部分。Spire.PDF 提供了 InsertPageRange 方法,支持基于起始页和结束页索引(索引从0开始)来提取指定页码区间,并保存为新的 PDF 文件。
using Spire.Pdf;
namespace SplitPDF
{
class Program
{
static void Main(string[] args)
{
PdfDocument document = new PdfDocument();
document.LoadFromFile("心理健康.pdf");
// 指定拆分的起始页和结束页索引(0-2页,即第1到第3页)
int startPage = 0;
int endPage = 2;
PdfDocument rangePdf = new PdfDocument();
rangePdf.InsertPageRange(document, startPage, endPage);
rangePdf.SaveToFile($"指定页码范围.pdf");
rangePdf.Close();
document.Close();
}
}
}
按关键字拆分 PDF
如果需要根据文档内容拆分 PDF,可以使用 PdfTextFinder 类的 Find 方法查找包含指定关键字的页面,然后通过 InsertPage 方法提取这些页面:
using Spire.Pdf;
using Spire.Pdf.Texts;
using System.Collections.Generic;
namespace SplitPDF
{
class Program
{
static void Main(string[] args)
{
PdfDocument document = new PdfDocument();
document.LoadFromFile("心理健康.pdf");
PdfDocument resultDoc = new PdfDocument();
string keyword = "问题";
for (int i = 0; i < document.Pages.Count; i++)
{
PdfPageBase page = document.Pages[i];
PdfTextFinder finder = new PdfTextFinder(page);
finder.Options.Parameter = TextFindParameter.WholeWord;
finder.Options.Parameter = TextFindParameter.IgnoreCase;
List<PdfTextFragment> fragments = finder.Find(keyword);
if (fragments.Count > 0)
{
resultDoc.InsertPage(document, page);
}
}
resultDoc.SaveToFile("关键字.pdf");
document.Dispose();
resultDoc.Dispose();
}
}
}
提取 PDF 中的指定页面
有时你可能只需要提取文档中的某一页或几页内容,而非整个文件。下面的示例展示了如何使用 InsertPage 方法提取指定页面,并将其保存为新的 PDF 文件:
using Spire.Pdf;
namespace SplitPDF
{
class Program
{
static void Main(string[] args)
{
PdfDocument pdf = new PdfDocument();
pdf.LoadFromFile("心理健康.pdf");
PdfDocument newPdf = new PdfDocument();
// 提取第3页(索引为2)
newPdf.InsertPage(pdf, pdf.Pages[2]);
newPdf.SaveToFile("提取指定页.pdf");
newPdf.Close();
pdf.Close();
}
}
}
总结
在 C# 中使用 Spire.PDF for .NET 拆分 PDF 文件,不仅简单高效,还具备很强的灵活性。无论是按固定页数拆分,提取特定页码段,还是根据关键字定位内容进行拆分,该库都能提供稳定可靠的支持,满足各种类型的文档处理需求。
常见问题解答(FAQs)
Q1:Spire.PDF 是否免费?
A1:Spire.PDF 提供适用于小型项目或非商业用途的免费版本。若需完整功能,建议使用商业授权版。
Q2:可以拆分加密的 PDF 吗?
A2:可以,只要在加载 PDF 时提供正确的密码即可。
Q3:Spire.PDF 支持 .NET Core 吗?
A3:支持。Spire.PDF 兼容 .NET Framework 与 .NET Core。
Q4:我能在一个项目中同时拆分和合并 PDF 吗?
A4:完全可以。Spire.PDF 同时支持拆分与合并操作。