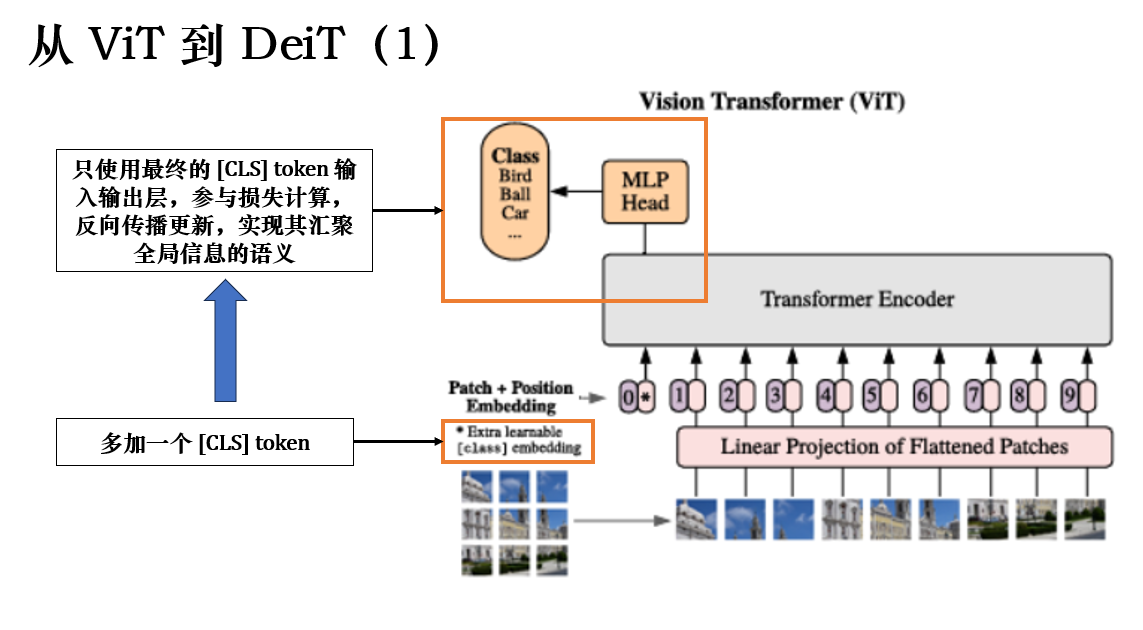
在前面的分析中,我们已经明确了 ViT 的核心问题:
由于归纳偏置较弱,ViT 对数据规模高度依赖。
就这个问题,我们又展开了一种改进思路:
通过蒸馏人为引入一个“软约束”,缩小搜索空间,从而减少数据依赖。
于是,我们就得到了 ViT 的其中一种改进:Data-efficient Image Transformer,即 DeiT。
1. DeiT 的两种蒸馏方式
DeiT 出自 ViT 的同年论文: Training data-efficient image transformers & distillation through attention.
它并不是简单地套用标准蒸馏,而是针对 Transformer 的结构,设计了两种蒸馏策略:
1.1 硬蒸馏 Hard Distillation
这种方式非常直接: 把 Teacher 的预测类别,当作额外的监督信号。
也就是说,Student 同时学习两个标签:数据的真实标签 \(y\) 和 Teacher 给出的预测标签 \(\hat{y}_t\)。
其损失函数可以写为:
\[\mathcal{L} = \frac{1}{2} \mathcal{L}_{CE}(y, p_s) + \frac{1}{2} \mathcal{L}_{CE}(\hat{y}_t, p_s) \]
要提前强调的是,这里的公式只是通用形式,实际上在 DeiT 中使用的不是同一个 \(p_s\),下一部分就会展开。
回到这里,其实对比我们在上一篇展开的蒸馏过程,这种方法看起来有些没必要:
只是多加一个标签,预测正确没有更多信息,预测错误反而影响拟合,为什么要这么做?
要理解来说,其实还是和 Teacher 本身的蒸馏意义相关:而在于通过 Teacher 的预测结果,引导 Student 在优化过程中靠近一个“更合理的决策边界”,从而提升训练稳定性。
比如真实标签是“狼”,但 Teacher 预测结果是“狐狸”,这样就可以让模型在“语义接近类别”之间间接引导模型学习更合理的决策边界。
不过,对比现代的蒸馏方法,这种方法已经很少单独使用了,我们知道就好。
1.2 软蒸馏 Soft Distillation
第二种方式就是我们前面介绍的标准蒸馏:让 Student 去拟合 Teacher 的概率分布。
其损失函数为:
\[\mathcal{L} = \alpha \mathcal{L}_{CE} + (1-\alpha) D_{KL}(p_t \parallel p_s) \]
显然,相比硬蒸馏,这种方式包含更多信息,在现代使用中也更主流。
不过,在 Transformer 之前,蒸馏技术就已经出现,如果只是在 ViT 中加入蒸馏技术,本质上只是 A+B 的工作罢了。
DeiT 的关键创新点在于:
把“蒸馏过程”也做成了 Transformer 结构的一部分。
我们下面来详细展开这部分逻辑:
2. DeiT 的核心改进
2.1 输入处理
DeiT 实现蒸馏逻辑的具体做法是:
在输入序列中,再额外引入一个 distillation token。
我们来理顺一遍,首先,是原始图像切分出的 patch token :
\[[\mathbf{z}^1, \dots, \mathbf{z}^N] \]
在此基础上,我们为了整合全局信息用于 CV 任务,又加入了 [CLS] token :
\[[\mathbf{x}_{cls}, \mathbf{z}^1, \dots, \mathbf{z}^N] \]
而现在,在 DeiT 的设计中,我们再加入一个 Distillation token,即蒸馏 token :
\[[\mathbf{x}_{cls}, \mathbf{x}_{dist}, \mathbf{z}^1, \dots, \mathbf{z}^N] \]
这个 \(\mathbf{x}_{dist}\) 就专门用于学习 Teacher 的信息。
2.2 传播逻辑
知道又加了一个 distillation token 后,和 [CLS] token 一样的问题是:
我们如何实现 distillation token 专门学习 Teacher 信息的语义?
答案的关键词是:双输出结构。
我们从原本的 ViT 来展开改进过程:


到这里,你就会发现:DeiT 并没有把学习真实标签和 Teacher 给出的预测标签混在一起,而是解耦二者,[CLS] token 只学习真正标签,distillation token 只学习蒸馏标签。
再展开一下:
在训练阶段,DeiT 会产生两个输出:
- CLS 分支(主任务)
\[p_{cls} = \text{MLP}(\mathbf{x}_{cls}) \]
- Distillation 分支(蒸馏任务)
\[p_{dist} = \text{MLP}(\mathbf{x}_{dist}) \]
最终,损失可以写为:
\[\mathcal{L} = \mathcal{L}_{CE}(y, p_{cls}) + \mathcal{L}_{KD}(p_t, p_{dist}) \]
当然,你也可以加入权重的设计。
这样,与传统蒸馏仅在模型输出端施加监督不同,distillation token 会作为 Transformer 的一部分参与 self-attention 计算,使得 teacher 信息能够在特征形成阶段被逐层融合,从而影响模型的内部表示学习过程。

值得一提的是,DeiT 原论文的主要实验结论是基于 hard distillation 的,soft 作为对照方法存在但未成为最优结果,其损失形式如下:
\[\mathcal{L} = \frac{1}{2} \mathcal{L}_{CE}(y, p_{cls}) + \frac{1}{2} \mathcal{L}_{CE}(y_t, p_{dist}) \]
实验结果表明,在 CNN 到 ViT 的跨结构蒸馏场景中,soft distillation 并未展现出优势。
相反,基于 hard label 的 distillation 更稳定,也更符合 ViT 的优化特性,因此成为最终采用的主方案。
显然,这带来的一个额外问题是:
那为什么 soft distillation 反而更主流?
答案并不是它在所有任务中更强,而是它提供更多信息,从而在跨任务、跨模型、跨领域的知识迁移中具有更高的通用性。
可以简单概括来说:hard distillation 学的是“答案”,soft distillation 学的是“思考方式”。
因此,在 DeiT 这一分类应用中前者的作用更突出,后者在这一模型中虽没有前者稳定,但却是更广泛领域中的选择。
实际上,蒸馏技术不断发展,早已不再满足这种仅仅对输出的蒸馏了,现在已经有了对中间特征的蒸馏,甚至自己蒸馏自己等更多、更高效的形式,我们遇到再详细展开。
到这里,我们就了解到 DeiT 通过蒸馏,引入外部归纳偏置,从而解决数据问题。
不过,其实还有另外一种改进思路:不依靠外力,通过结构本身重建归纳偏置。
而这种自身结构的优化,才是 Vision Transformer 走向主流应用的关键转折点。
我们在下一篇就来详细展开。
文章摘自:https://www.cnblogs.com/Goblinscholar/p/19860718