最近,不管是工业物联网、智能运维、金融分析,还是零售销量预测、能源电网负荷管理,都在提一个词:时序大模型。
听着很高大上、很学术,其实也可以很简单。本系列就用大白话来把时序大模型相关的概念讲清楚。
今天讲:它是什么、能帮业务干什么。
先简单介绍什么是时序数据。
时序数据就是按时间顺序排成一串的数据。它无处不在:
- 气象:一天 24 小时气温、湿度、风速
- 金融:股票 / 基金每分钟价格、交易量
- 工业:设备温度、振动、电流、电压
- 互联网:服务器 CPU、内存、流量波动
- 零售:每日销量、订单量、客流
- 能源:电网负荷、光伏 / 风电出力
对于工业设备来说,时序数据就是工业设备的“心电图”。
这些数据有一些特点:前后有关联、有趋势、有波动。
时序数据相关的分析场景也是多样化的,大家常见的场景就是天气预报,预测未来气温变化。
在工业场景,就是预测未来电价趋势、预测设备是否会故障、识别一段数据是否代表着某类事件等。
在这些场景里做分析,都需要一事一议。这里有一个跨行业数据挖掘标准流程,叫 CRISP-DM,一共 6 步:
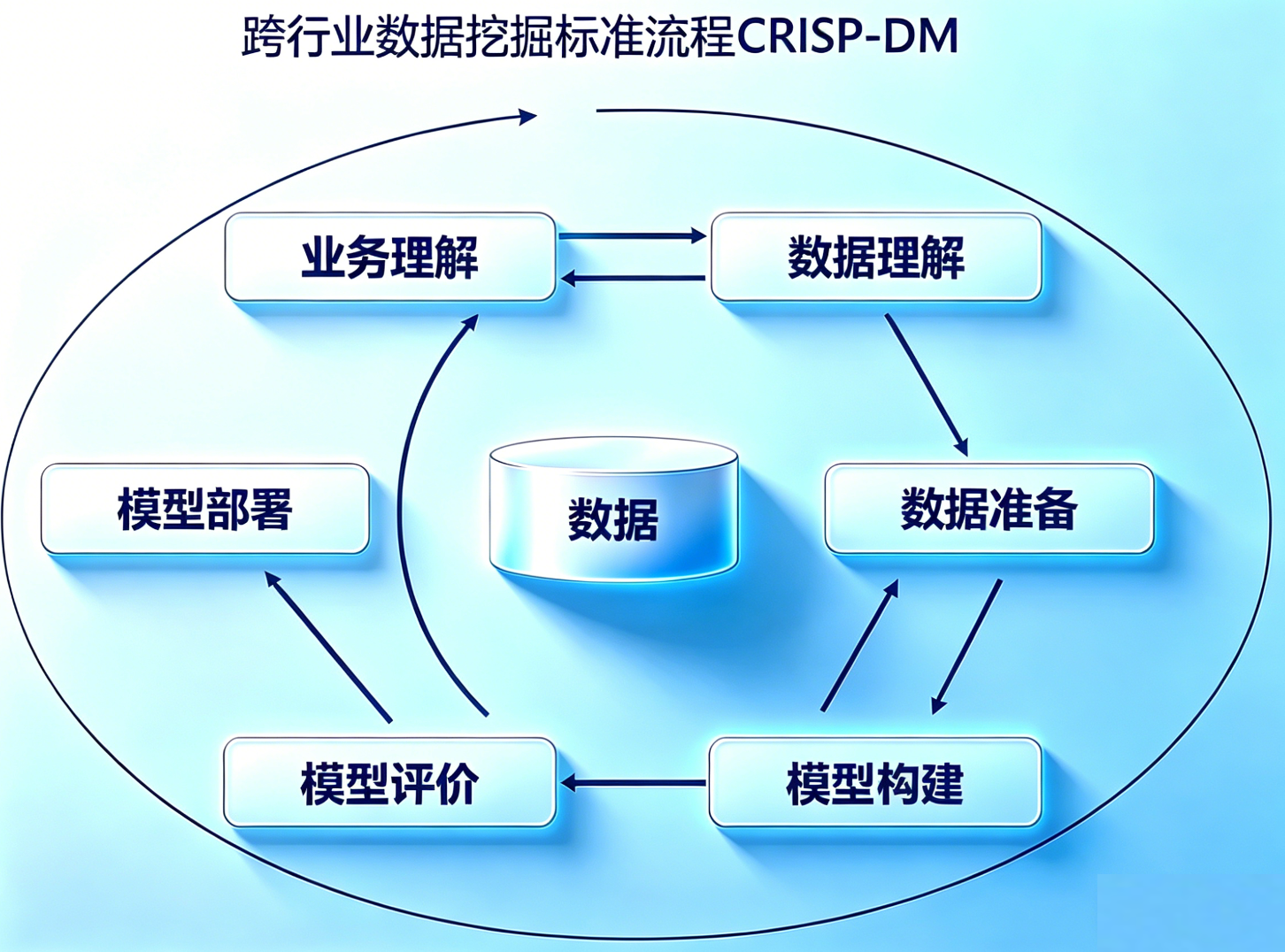
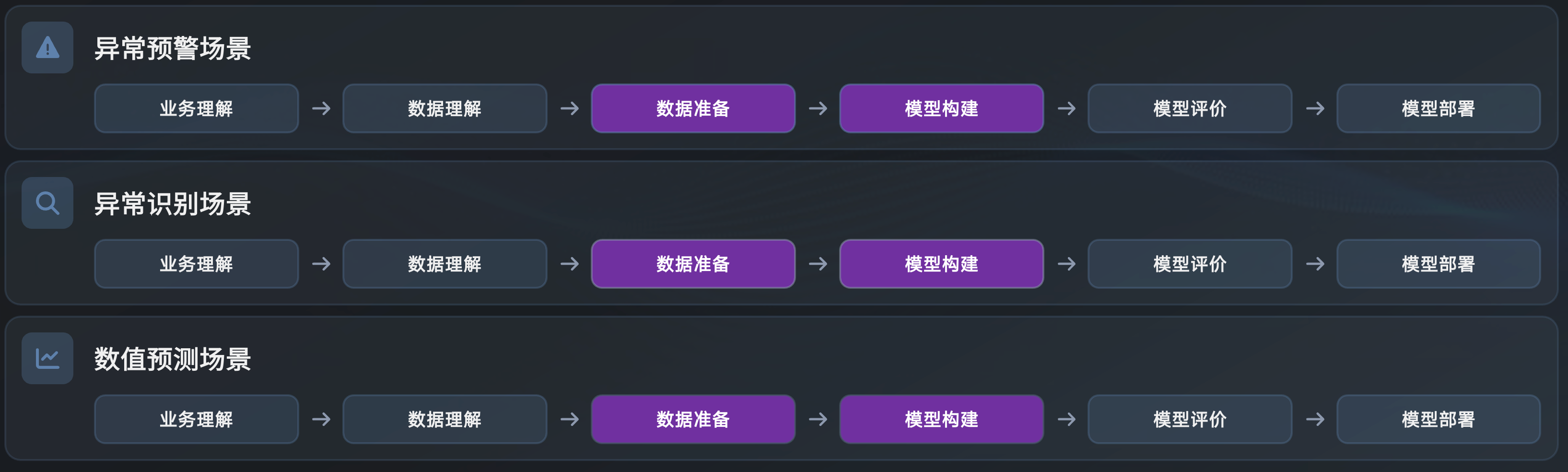
在业务理解和数据理解的基础上,耗时最多的,也是算法工程师投入大量精力的地方,就是数据准备 + 模型构建。
在一个企业的每个时序智能研发场景中,都在不断重复这个流程。
当前,时序模型靠的主要是 ARIMA、LSTM、Holt-Winters、深度学习等传统小模型。
时序数据缺了要补、噪声大了要洗、特征要手工选择;数据不够时小模型还训不出来。
成本高、周期长、效果不稳定。
有解法吗?
在时序算法工程师的多年探索后,也同时受到大语言模型的启发,不论是什么时序分析场景,都会涉及到时序数据建模、时序数据理解、时序数据趋势分析等基础部分,这是各个时序模型的基本功。
那么,能不能专门练这些基本功,形成一个通用的时序分析组件,去降低各个场景的数据准备和模型构建的成本?
就像为每个专业领域,都配一个资深时序分析专家。
这就是时序大模型。
为了练这个时序大模型,就需要收集大量的时序数据(预训练时序数据)。就像大语言模型满世界搜集语料库一样。
时序大模型在上述流程中的作用大概是这样:降低数据准备和模型构建的复杂度。本质上,是在合并同类项。
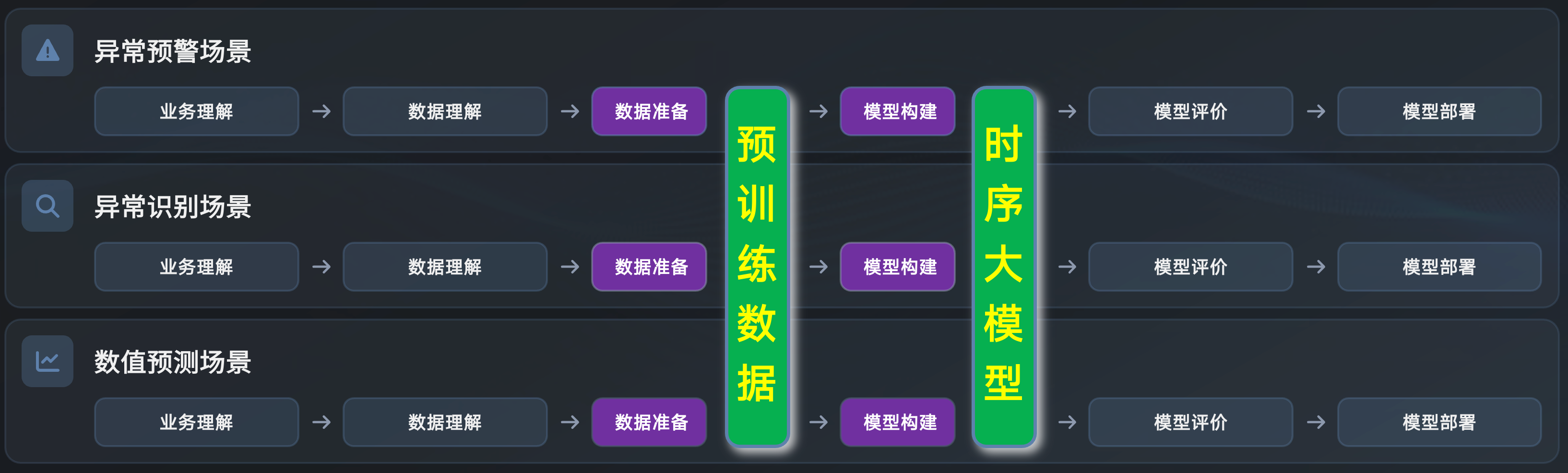
其中,时序大模型是可以直接使用的,而预训练数据,是时序大模型研发人员要考虑的,使用者不需要考虑。
有了时序大模型,模型构建的工作就能被简化,变成小模型+大模型联合解决方案。
每个场景需要准备的数据量也会更少,因为时序大模型本身就有对大量时序数据的理解。
原来因为数据样本不足,没法实现的场景,现在就变得可行。
用一句最接地气的话来说:时序大模型,就是把海量时序数据里的通用规律,提前学成一个超级 AI 底座,拿来就能用、少数据也能用。
对企业来说,时序大模型就是时序智能的工业革命。
最近,我们将时序大模型做成了云服务:ai.timecho.com。为大家提供最简单、直观体验时序大模型的渠道。
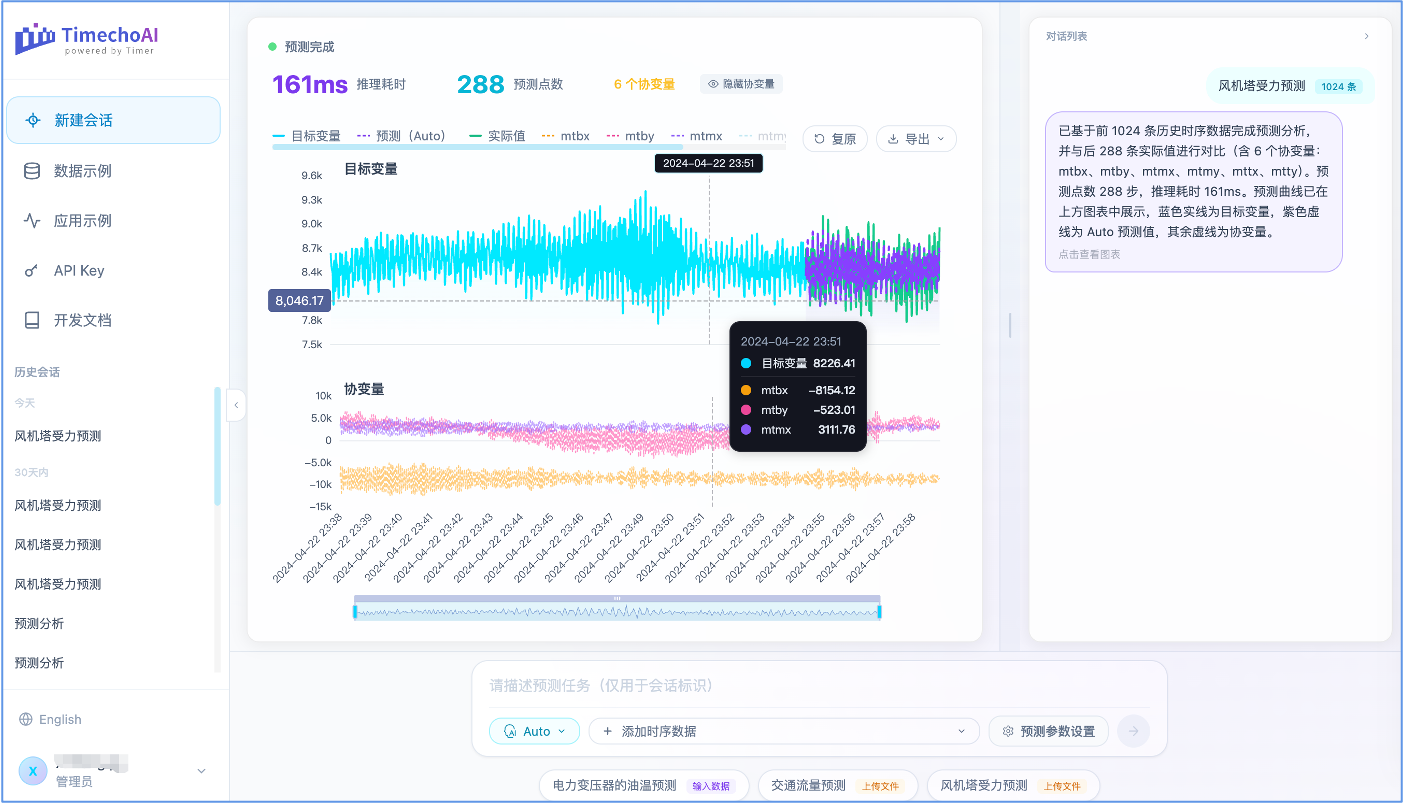
不论你是不是计算机专业人员,都能够在 TimechoAI 这个平台快速理解时序大模型能干什么。
欢迎参与免费试用,让我们一起来探索时序大模型的无限可能。
文章摘自:https://www.cnblogs.com/apacheiotdb/p/20032032