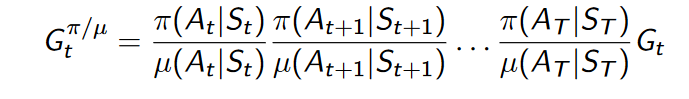
本随笔的图片都来自UCL强化学习课程lec5 Model-free prediction的ppt (Teaching – David Silver ).
回忆值函数的表达式:
\[v_\pi(s) =\mathbb E_\pi[G_t\mid S_t=s] \]
其中\(G_t\)是折扣回报。期望\(\mathbb E\)下面的\(\pi\)是简写,实际上应该写作:
\[A_t,S_{t+1},A_{t+1}\cdots,S_k\sim\pi \]
无论MC prediction还是TD prediction,都是在估计\(\mathbb E_\pi[G_t \mid S_t=s]\),本质上是在做policy evaluation,evaluate的是\(\pi\)。从值函数表达式就可以看出,要估计\(v_\pi\),应该整条轨迹(的动作)都是从\(\pi\)上采样的。
如果从行为策略\(\mu\)采样,就变成了用策略\(\mu\)的数据来evaluate策略\(\pi\),这就需要用importance sampling来修正了。
-
所以对于离策略的MC方法,在轨迹上每次对action的采样,都需要修正:

-
离策略的TD方法,只用修正一步:

-
Q-learning,直接估计的是\(Q^*\),遍历action求max不涉及action的采样,天生是离策略,不需要修正:
