论文阅读笔记(五):Hire-MLP: Vision MLP via Hierarchical Rearrangement
摘要
先前的MLPs网络接受flattened 图像patches作为输入,使得他们对于不同的输入大小缺乏灵活性,并且难以捕捉空间信息,本问Hire-MLP通过层次化重排构建视觉MLP架构,包含两个层次的重排。其中,区域内重排是为了捕获空间区域内的局部信息,跨区域重排是为了实现不同区域之间的信息通信,并通过沿空间方向循环移动所有标记来捕获全局上下文。大量的实验证明了Hire-MLP作为多种视觉任务的通用骨干的有效性。特别是,Hire-MLP在图像分类、目标检测和语义分割任务上取得了具有竞争力的结果,例如,在ImageNet上的top1精度为83.8%,在COCO val2017上的框AP和掩模AP分别为51.7%和44.8%,在ADE20K上的mIoU为49.9%,超越了之前基于变压器和基于mlp的模型,在精度和吞吐量方面有更好的交换
引入
- 动机
- 由于transformer的自注意模块所带来的沉重的计算负担,使得模型无法更好地兼顾准确性和延迟。
- MLP-Mixer通过应用于每个图像补丁的mlp提取每个位置的信息,并通过应用于多个图像补丁的mlp捕获远程信息。但有两个棘手的缺陷阻止该模型成为视觉任务的更一般的骨干:
- patch的数量随着输入大小的变化而变化,使得其不能直接使用预训练并在其他分辨率上直接微调,这使得MLP-Mixer无法被转移到检测和分割等下游视觉任务中。
- MLP-Mixer很少研究局部信息,这在cnn和基于变压器的架构中都被证明是一个有用的归纳偏置
- 主要贡献
结论
本文提出了一种基于mlp架构的新变体,通过分层重新排列token来聚合局部和全局空间信息。输入特征首先沿着高度/宽度方向被分割成多个区域。通过内部区域重排操作,使每个区域的不同token能够充分通信,将不同token的通道混合,提取局部信息。然后通过token移位来重新排列来自不同区域的token。这种跨区域重排操作不仅交换了区域之间的信息,而且保持了相对位置。Hire-MLP基于上述操作构建,并在各种视觉任务中取得了显著的性能改进。
网络结构
Hierarchical Rearrangement Module
由于全连通层的尺寸是固定的,因此在对象检测、语义分割等密集的预测任务中,它不兼容长度可变的序列。此外,每个token混合操作都捕获和聚合全局信息,而一些关键的局部信息可能会被忽略。hIre模块的内部区域重排操作可以捕获预定义区域内tokoen的局部信息,而跨区域重排的操作可以捕获全局信息。由于提出的区域划分,在不同大小的输入条件下,每个区域的大小保持不变。因此,我们的hire模块可以自然地处理可变长度的序列,并具有相对于输入大小的线性计算复杂度。
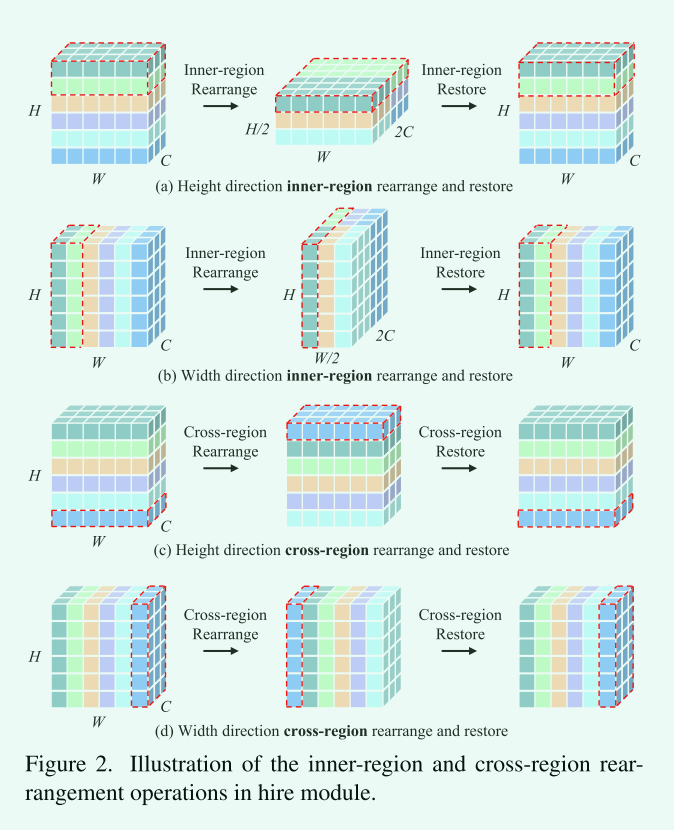
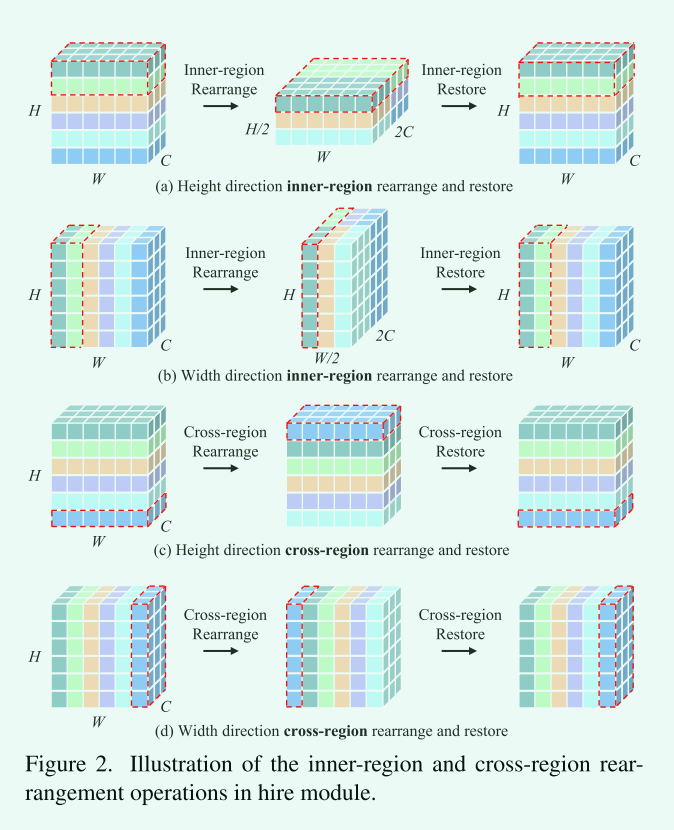
- Region Partition
首先将输入特征划分为多个区域,该特征可以沿着宽度和高度方向进行分割。
-
Inner-region Rearrangement
给定一个输入特征\(X_i \in R^{h \times W \times C}\),它是沿着高度方向的第i个区域,我们将\(X_i\)中的所有token沿通道维数进行concat,得到形状为\(W \times hC\)的重排特征\(X_i^c\),随后被输入到一个MLP模块中用于融合最后一个维度的信息,得到输出特征\(X_i^o\),这里的MLP模块是由两个带有瓶颈的线性投影实现的(投影的“瓶颈”是指压缩到的低维空间的维度远远小于输入数据的维度,这样可以强制模型学习输入数据的主要特征,而忽略一些次要特征,从而提高模型的泛化能力)最后,将输出特征\(X_i^o\)恢复到下一个模块的原始形状,即沿着最后一个维度将其分解为多个令牌,得到特征\(X_i^{‘}\in R^{h\times W \times C}\)
-
Cross-region Rearrangement
跨区域重排是通过在给定步长s的特定方向上递归地移动所有标记来实现的,如图2(c) (s = 1沿高度方向)和图2(d) (s = 1沿宽度方向)所示。移位后,被区域分割的局部区域中包含的令牌会发生变化。这个操作可以通过Pytorch/Tensorflow中的“圆形填充”轻松完成。为了获得全局接收域,每两个块在内部区域重排操作之前插入跨区域重排操作。在进行内部区域恢复操作后,对移位的标记进行位置恢复,以保持不同标记之间的相对位置。而这种恢复可以进一步提高我们的HireMLP的准确性。我们提出的跨区域重排保留了不同标记之间的相对位置。我们认为,相对位置是实现高表现能力的关键。
-
Hire Module
考虑尺寸为H×W×C的输入特征X,空间信息通信在两个分支中进行,即沿着高度方向和宽度方向。受ResNet和ViP中残差连接的启发,还增加了一个没有空间通信的额外分支,其中只有一个完全连接的层被用来沿着通道维度编码信息。将输入X发送到上述三个分支,分别得到特征\(X_W^{‘}\), \(X_H^{‘}\), \(X_C^{‘}\)。将这些特征相加得到输出特征\(X^{‘}\),即\(X^{‘}\)= \(X_W^{‘}\),+\(X_H^{‘}\)+\(X_C^{‘}\)
-
复杂度分析
在Hire Module中,全连接层层占用了主要的内存和计算开销。考虑图1中的高度方向分支,给定一个输入特征\(X \in R^{h \times W \times C}\),,我们首先将其分割成形状为h×W×C的H/h区域。内部区域重排后的特征形状为H/h×W×hC。我们经验地将瓶颈中的通道维数设置为C/2,因此该支路占用hC × c/2 × 2 = hC^2参数和H H ×W × hC × c^2 × 2 = HWC^2 FLOPs。
-
总体架构
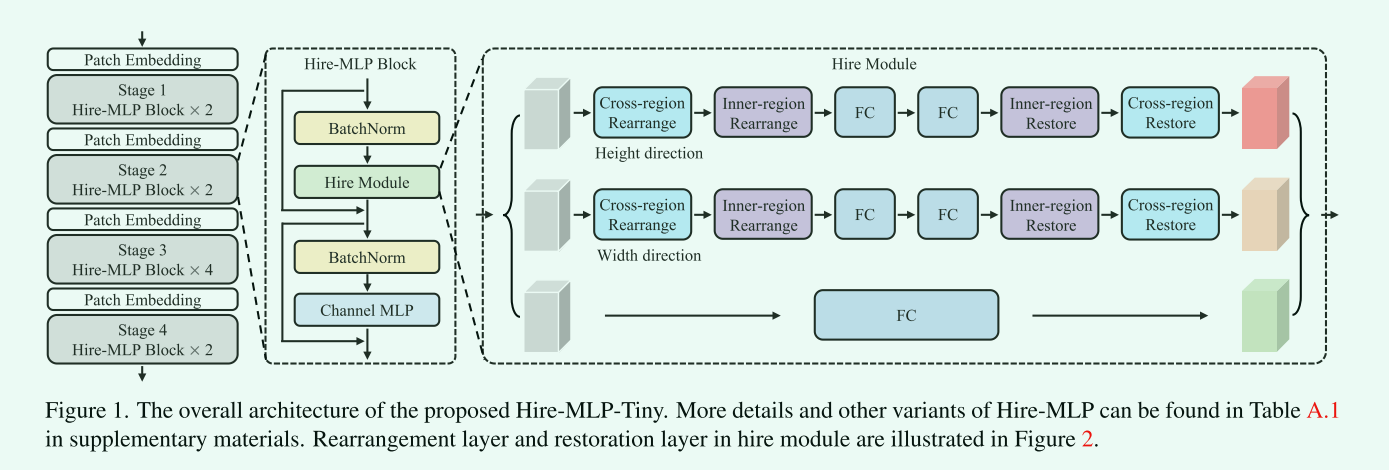
它首先通过patch嵌入层将输入图像分割为patch (token)。然后两个Hire-MLP块被称应用于上面的tokens。随着网络深度的增加,token数量减少,同时输出通道增加一倍。特别是整个体系结构包含四个阶段,特征分辨率从h/4 × w/4降低到h/32 × w/32,输出维数相应增加。金字塔结构将空间特征聚集起来提取语义信息。
实验
- ImageNet上的图像分类
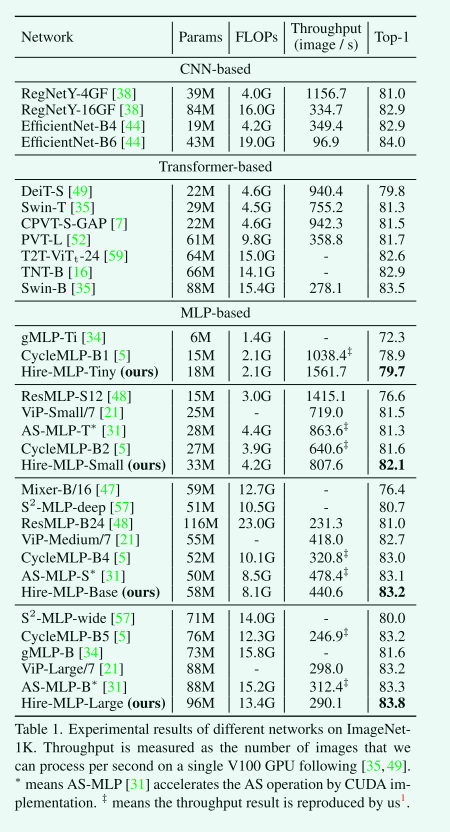
所提出的Hire-MLP模型在图像分类任务中表现优秀,与基于CNN、Transformer和MLP的模型相比具有最先进的性能。Hire-MLP-Small模型仅使用4.2G FLOPs就实现了82.1%的top-1精度,优于所有现有的基于MLP的模型。将模型扩展到8.1G和13.1G时,top-1准确率分别达到83.2%和83.8%。 Hire模块可以更好地捕获本地和全局信息,这比基于CNN的模型获得了更好的结果,并且比基于Transformer的模型具有更快的推理速度。然而,我们的模型与最先进的EfficientNet-B6之间仍然存在一定差距。MLP-based体系结构具有简单性和更快的推理速度等独特优点,并且未来可以进一步增强模型。
-
消融实验
Hire-MLP中的核心组件是hierarchical rearrangement模块,我们对区域划分中每个区域的token数量、跨区域的移动区域数量和不同的重排方式、内区域重排的填充模式以及租用模块中的FC层数进行了消融研究。
-
区域分区中每个区域的token数
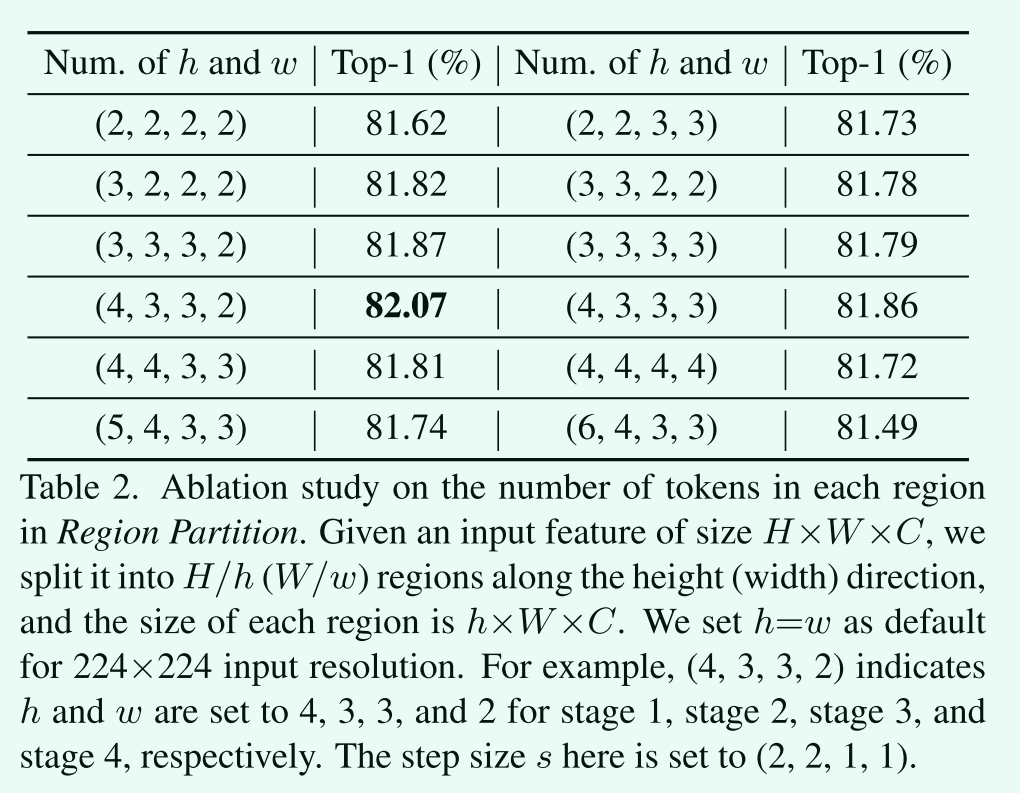
区域大小越小,意味着通过内部区域重排操作混合的相邻token越少,更注重局部信息。我们的经验发现,在较低的层次上,需要更大的区域大小来处理带有更多token的特征图,并获得更大的接受域。当区域大小进一步增大时,性能会略有下降。我们推测随着区域大小的增加,瓶颈结构中可能存在一些信息丢失。
-
跨区域重排中移位token的步长s。

token不移位时,即s =(0,0,0,0),不同区域之间不存在通信(不存在跨区域重排操作)。显然,全局信息的缺乏导致表现下降。
-
不同填充方法的影响

-
Hire模块中不同组件的影响。
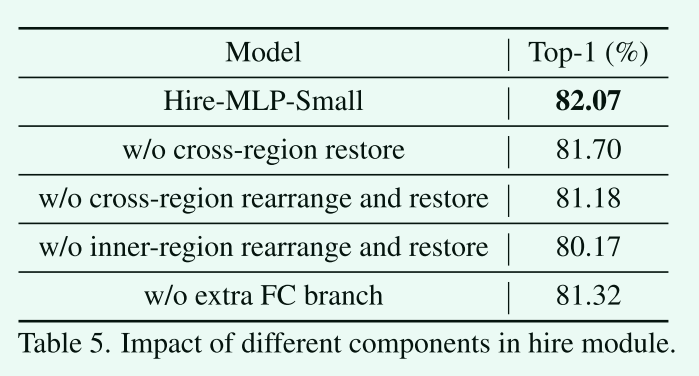
我们可以发现,区域内部的重排是捕获局部信息的最重要的组成部分。跨区域恢复操作可使top-1精度提高0.3%。如果我们放弃跨区域的重排(包括恢复),模型将无法跨区域交换信息,性能将下降到81.18%。去掉图1中的第三个分支将会使前1位的准确率降低0.7%。
-
不同的跨区域信息交流策略

与传统的ShuffleNet方法相比,该方法具有更好的效果,说明该方法可以为模型保留更多的相对位置信息。
-
Hire 模块FC层数
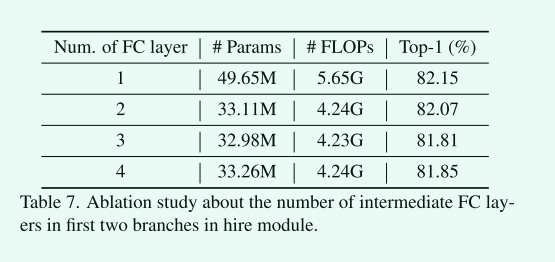
Hire模块中MLP的瓶颈设计有助于消除通道数增加带来的FLOPs的增加。虽然使用一个FC层可以获得最好的性能,但参数和FLOPs都比其他FC层大。具有两个FC层的瓶颈可以在准确性和计算成本之间获得更好的权衡。此外,增加更多的FC层并不能带来更多的好处,说明这种改进来自于我们的分层重排操作,而不是增加FC层的数量。
-
-
COCO数据集上的目标检测和实例分割
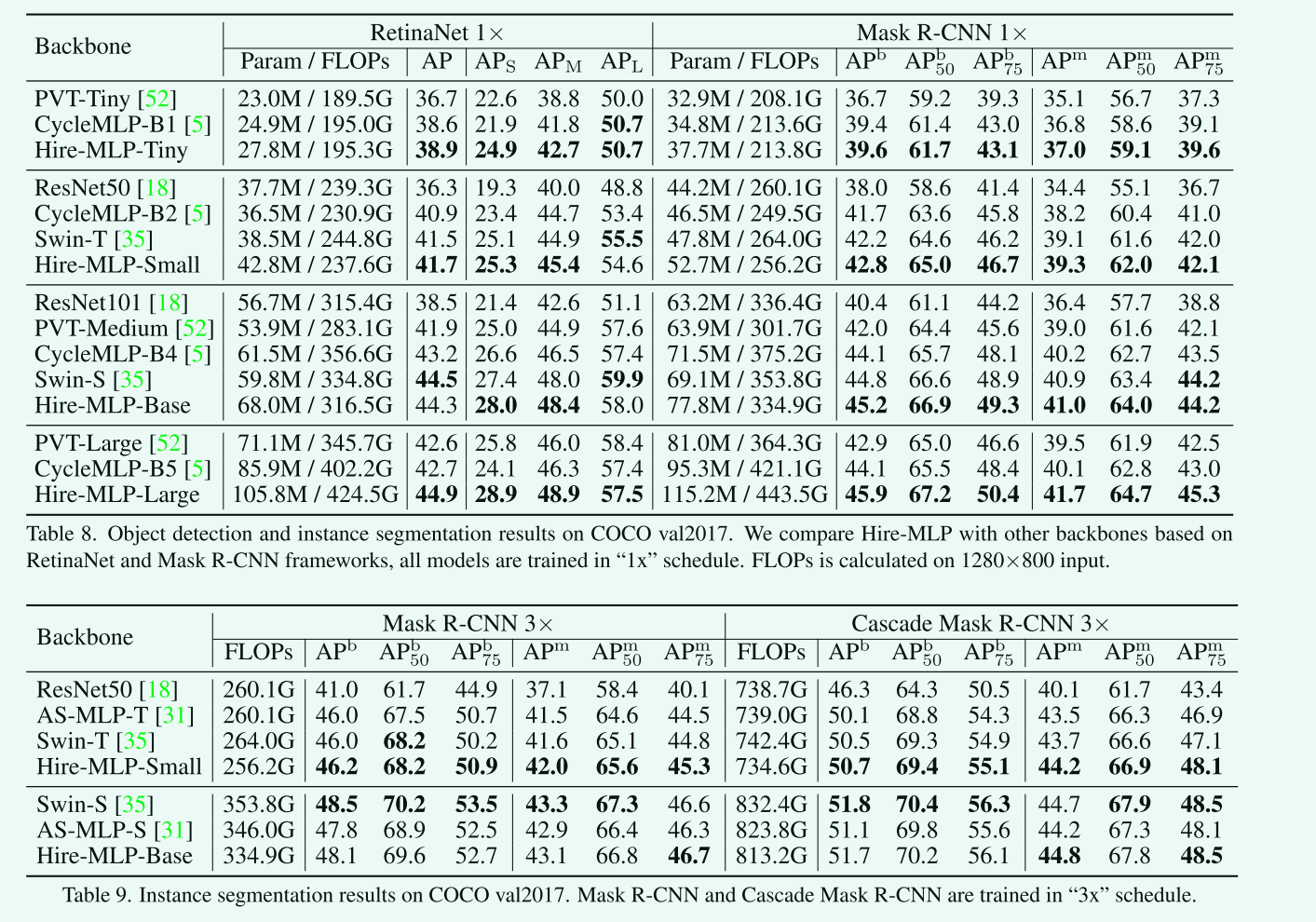
-
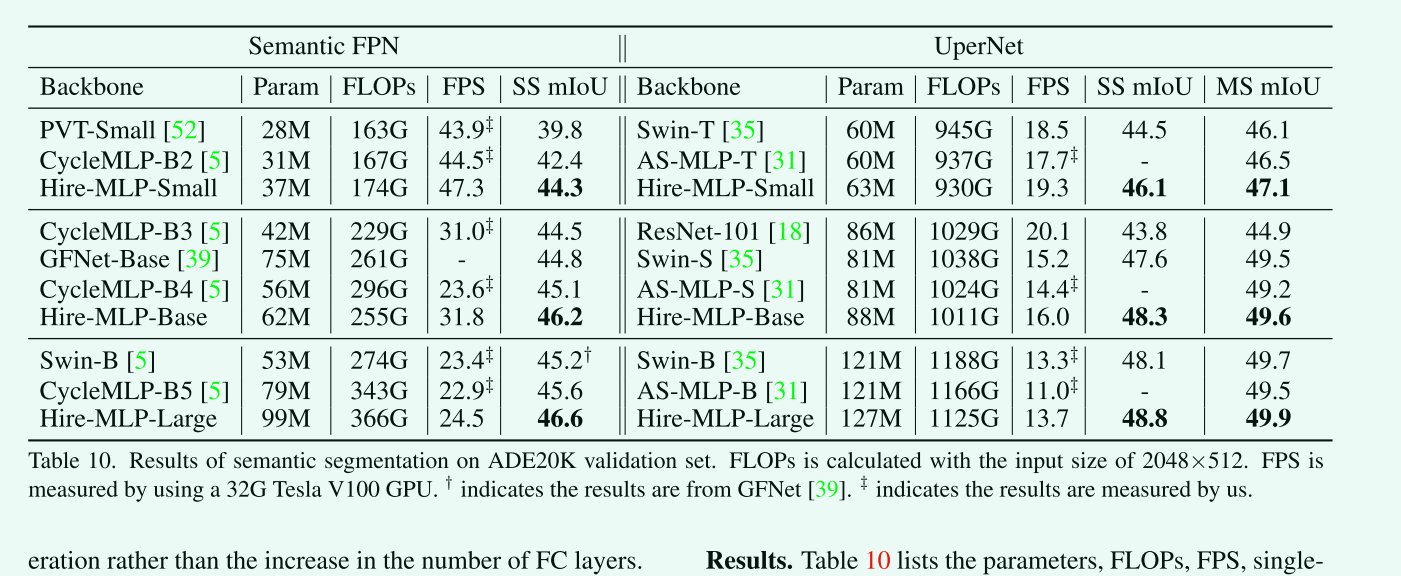
ADE20K数据集上的语义分割