这一章我们聊聊指令微调,指令微调和前3章介绍的prompt有什么关系呢?哈哈只要你细品,你就会发现大家对prompt和instruction的定义存在些出入,部分认为instruction是prompt的子集,部分认为instruction是句子类型的prompt。
对比前三章介绍过的主流prompt范式,指令微调有如下特点
- 面向大模型:指令微调任务的核心是释放模型已有的指令理解能力(GPT3中首次提出),因此指令微调是针对大模型设计的,因为指令理解是大模型的涌现能力之一。而prompt部分是面向常规模型例如BERT
- 预训练:与其说是instruction tunning,更像是instruction pretraining,是在预训练阶段融入多样的NLP指令微调,而非针对特定下游任务进行微调,而之前的promp主要服务微调和zeroshot场景
- multitask:以下模型设计了不同的指令微调数据集,但核心都是多样性,差异化,覆盖更广泛的NLP任务,而之前的prompt模型多数有特定的任务指向
- 泛化性:在大模型上进行指令微调有很好的泛化性,在样本外指令上也会存在效果提升
- 适用模型:考虑指令都是都是sentence形式的,因此只适用于En-Dn,Decoder only类的模型。而之前的prompt部分是面向Encoder的完形填空类型
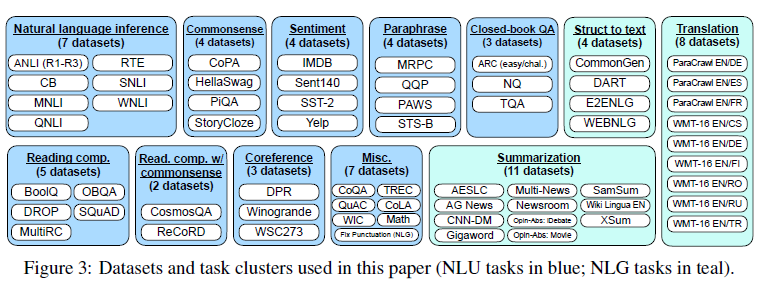
下面我们介绍几个指令微调相关的模型,模型都还是那个熟悉的模型,核心的差异在于微调的指令数据集不同,以及评估侧重点不同,每个模型我们只侧重介绍差异点。按时间顺序分别是Flan, T0,InstructGPT, TK-Instruct
Google: Flan
- paper: 2021.9 Finetuned Langauge Models are zero-shot learners
- github:https://github.com/google-research/FLAN
- 模型:137B LaMDA-PT
- 一言以蔽之:抢占先机,Google第一个提出指令微调可以解锁大模型指令理解能力
谷歌的Flan是第一个提出指令微调范式的,目的和标题相同使用指令微调来提升模型的zero-shot能力。论文使用的是137B的LAMDA-PT一个在web,代码,对话, wiki上预训练的单向语言模型。
指令集
在构建数据集上,谷歌比较传统。直接把Tensorflow Dataset上12个大类,总共62个NLP任务的数据集,通过模板转换成了指令数据集

为了提高指令数据集的多样性,每个任务,会设计10个模板,所以总共是620个指令,并且会有最多3个任务改造模板。所谓的任务改造就是把例如影评的情感分类任务,转化成一个影评生成任务,更充分的发挥已有标注数据构建更丰富的指令数据集。哈哈感觉这里充满了人工的力量。
为了保证数据集的多样性和均衡性,每个数据集的训练样本限制在3万,并且考虑模型对一个任务的适应速度取决于任务数据集大小,因此按使用数据集样本大小占比按比例采样混合训练。
效果
效果上137B的指令微调模型大幅超越GPT3 few-shot, 尤其是在NLI任务上,考虑NLI的句子对基本不会在预训练文本中自然作为连续上下句出现。而指令微调中设计了更自然地模板带来了大幅的效果提升。

除了以上存在明显效果提升的任务,在一些任务本身就和指令相似的任务,例如常识推理和指代消歧任务,指令微调并不能带来显著的效果提升。
作者做了更多的消融实验,验证指令微调中以下几个变量
- 模型规模:
作者进一步论证了指令微调带来的效果提升存在明显的大模型效应,只有当模型规模在百亿左右,指令微调才会在样本外任务上带来提升。作者怀疑当模型规模较小时,在较多任务上微调可能会占用模型本就不多的参数空间,造成预训练时的通用知识遗忘,降低在新任务上的效果。

-
多任务影响:
考虑指令微调是在多任务上进行,作者希望剔除指令微调中多任务微调带来的影响。因此尝试进行多任务非指令微调(使用数据集名称代替指令),效果上指令微调显著更优,说明指令模板的设计确实存在提升模型指令理解力的效果。 -
few-shot:
除了zero-shot,Flan同时验证了few-shot的效果。整体上few-shot的效果优于zero-shot。说明指令微调对few-shot也有效果提升。 -
结合prompt-tunning
既然指令微调提升模型对指令的理解能力,作者认为应该对进一步使用soft-prompt也应该有提升。因此进一步使用了prompt-tunning对下游任务进行微调,不出意外Flan比预训练LaMDA的效果有显著的提升。
BigScience: T0
- paper: 2021.10 Multitask prompted training enables zero-shot task generation
- T0: https://github.com/bigscience-workshop/t-zero
- Model: 11B T5-LM
- 一言以蔽之: Flan你想到的我也想到了! 不过我的指令数据集更丰富多样
T0是紧随Flan发布的论文,和FLan对比有以下以下几个核心差异:
- 预训练模型差异:Flan是Decoder-only, T0是Encoder-Decoder的T5,并且考虑T5的预训练没有LM目标,因此使用了prompt-tunning中以LM任务继续预训练的T5-LM
- 指令多样性:T0使用的是PromptSource的数据集,指令要比Flan更丰富
- 模型规模:Flan在消融实验中发现8B以下指令微调效果都不好,而3B的T0通过指令微调也有效果提升。可能影响是En-Dn的预训练目标差异,以及T0的指令集更多样更有创意
- 样本外泛化任务: Flan为了验证指令微调泛化性是每次预留一类任务在剩余任务训练,训练多个模型。T0是固定了4类任务在其余任务上微调
下面我们细说下T0的指令数据和消融实验
指令集
T0构建了一个开源Prompt数据集P3(Public Pool of Prompts),包括173个数据集和2073个prompt。从丰富程度上比Flan提升了一整个数量级,不过只包含英文文本,更多数据集的构建细节可以看PromptSource的论文。
作者在指令集的多样性上做了2个消融实验
- 指令集包括的数据集数:
在T0原始指令集的基础上,作者分别加入GPT-3的验证集,以及SuperGLUE,训练了T0+和T0++模型。在5个hold-out任务上,更多的数据集并不一定带来效果的提升,并且在部分推理任务上,更多的数据集还会带来spread的上升(模型在不同prompt模板上表现的稳定性下降)

- 每个数据集的prompt数(p):通过每个数据集采样不同数量的prompt进行训练,作者发现随prompt数提升,模型表现的中位数会有显著提升,spread存在不同程度的下降,不过看起来存在边际递减的效应。

OpenAI: InstructGPT
- paper: 2022.3 Training Language Model to follow instructions with human feedback
- Model: (1.3B, 6B, 175B) GPT3
- 一言以蔽之:你们还在刷Benchamrk?我们已经换玩法了!更好的AI才是目标
这里把InstructGPT拆成两个部分,本章只说指令微调的部分,也就是训练三部曲中的第一步,论文中叫SFT(Supervised fine-tuning)。从论文的数据构建和评估中,不难发现OpenAI对于什么是一个更好的模型的定义和大家出现了差异,当谷歌,BigScience联盟还在各种不同的标准任务上评估LM模型能力提升时,OpenAI的重点已经变成了更好的AI,也就是能更好帮助人类解决问题的人工智能。简化成3H原则就是
- Helpful:模型能帮助用户解决问题
- Honest: 模型能输出真实信息
- Harmless: 模型输出不能以任何形式伤害人类
于是正文部分的评估基本没有常见的Accuracy,F1等,而是变成了各种人工评估的打分,例如LikeScore,Hallucinations等等。指令微调数据集的分布也从标准NLP任务向用户在playground中提交的问题偏移。下面我们细说下这两部分
指令集
先说下SFT指令集的构建,InstructGPT构建了训练12725+验证1653条prompt指令,由标注员的标注样本和用户在playground中和模型交互的指令共同构成,相比T0指令的多样性又有大幅提升。不过以下的指令数量包括了few-shot采样,也就是1个instruction采样不同的few-shot算多条指令。

除了丰富程度,和T0以及Flan指令集最大的差异在于指令类型的分布。 标注人员标注了以下三类样本
- Plain: 标注同学自由构建任务指令
- Few-shot:自由构建任务的同时给出few-shot样例
- User-Based: 基于用户申请waitlist时给出的使用用途,让标注同学构建对应的指令任务
整体上会更偏向于用户在真实场景下和模型交互可能提问的问题,自由式生成例如脑暴,改写,聊天,自由创作类的任务占了绝大多数。 而T0,Flan的指令集集中在NLP的分类和QA任务,这类任务的在实际交互中占比其实很小。下图是OpenAI play ground中收集的用户指令的分布

以及从论文的表述中存在迭代 ,也就是标注同学标注的指令集用于训练第一版InstructGPT,然后发布到playground,收集更多的用户和模型交互的指令,再使用用户指令来训练后续的模型。因此在用户导向的数据集上OpenAI相比所有竞争对手都有更深厚的积累,你以为在白嫖人家的playground?人家也在收集数据提升他们的模型。
SFT使用cosine rate decay 例如微调了16个epoch,但是发现在第一个epoch上验证集就已经过拟合了,但是过拟合会提升后续RLHF的模型效果。这部分我们放到RLHF章节再讨论,也就是什么样的模型更合适作为RLHF的起点
评估指标
从论文对如何把3H原则转化成客观的模型评估指标的讨论上,不难感受到OpenAI对于标注标准有过很长期的讨论和迭代,包括3个方向
- Helpful有用性
主要评价模型是否理解了指令意图,考虑有些指令本身意图的模糊性,因此有用性被泛化成标注同学1-7分的偏好打分。
- Harmless有害性
针对模型输出是否有害其实取决于模型的输出被用在什么场景中。OpenAI最初是用疑似有害性作为判断标注,不过看起来可能双审一致率不高,不同标注同学对疑似有害的认知存在较大差异。因此OpenAI设计了几条明确的有害标准,和风控类似,包括涉黄,涉暴,有侮辱性言语等等。
- Honest事实性
相比Honest的含义 ,Truthfulness更适合用与没有价值观的模型,论文使用封闭域上模型伪造事实的概率,和在QA问题上的准确率来评估。
以上的标注标准,具体反映在以下的标注页面中

模型效果
评估数据也分成了两部分,标准NLP数据集,和API收集的指令数据进行标注得到,也就是OpenAI独有数据。
- API数据集
有用性上,不论是在请求GPT,还是在请求InstructGPT的指令样本中,不论是使用新的标注同学,还是和标注训练样本相同的标注同学,对比原始GPT3,SFT之后的模型like score都显著更高,并且存在模型规模效应。

具体拆分到是否遵循指令,是否给出伪事实,以及能否对用户起到帮助作用上,SFT微调后的模型都有显著提升。

同时论文对比了使用Flan和T0的指令集对GPT3进行微调,发现虽然比原始GPT3有提升,但是效果会显著差于使用更接近人类偏好的指令集微调的SFT。论文给出了两个可能的原因
- 公开NLP任务类型集中在分类和QA,这和OpenAI playground中收集的任务分布存在较大的差异
- 公开NLP数据集的指令丰富程度 << 人们实际输入的指令多样性

- 标准NLP任务
在TruthfulQA任务上,SFT模型相比GPT有微小但是显著的提升,整体事实性还是有待提高。

在RealToxicityPrompts数据集上,不管是人工打分还是Perspective模型打分都显示,SFT相比GPT3,在产出有害内容上比例有显著的下降。

综上所述,InstructGPT在指令微调上最大突破是指令数据集分布的差异性,标准NLP任务更少,自由开放类任务更多,以及依赖Openai免费开放的playground,可以持续收集用户的指令用于模型迭代。同时在评估标准上,在语言模型之外引入3H体系来评价模型作为AI的能力效果。
AllenAI:TK-Instruct
- paper: 2022.4 SUPER-NATURAL INSTRUCTIONS:Generalization via Declarative Instructions on 1600+ NLP Tasks
- 开源指令集:https://instructions.apps.allenai.org/
- Model: 11B T5
- 一言以蔽之:没有最大只有更大的指令集,在英文和非英文的各类任务上超越InstructGPT?
Tk-Instruct最大的贡献在于开源了更大规模的指令数据集,并且对上述提到的T0(promptSource),Flan,InstructGPT指令集进行了对比总结,如下

TK-Instruct在76大类,总共1616个任务上构建了指令集,任务分布比T0和Flan更加多样和广泛,比InstructGPT要小(不过因为Instruct GPT的指令更多是开放生成类的用户指令所以不太可比),且占比上还是更偏向标准NLP任务类型。

其他细节这里不再赘述,这里放TK-InstructGPT更多是想看下以上T0,InstructGPT,TK-Instruct的效果对比。可以发现在内容理解任务上Tk-Instruct是要显著超越InstructGPT的,在生成类任务上二者差不多。但整体和有监督微调(虚线)相比还有很大的提升空间。这里其实也是我对Chatgpt能力的一些疑虑,不可否认它在拟人化和对话上的成功,但是在标准NLP任务上ChatGPT的水平如何,这一点有待评估,好像又看到最近有类似的论文出来,后面再补上这部分

更多Prompt相关论文·教程,AIGC相关玩法戳这里DecryptPrompt