谷歌(Google)作为开源过著名深度学习框架Tensorflow的超级大厂,是人工智能领域一股不可忽视的中坚力量,旗下新产品Bard已经公布测试了一段时间,毁誉参半,很多人把Google的Bard和OpenAI的ChatGPT进行对比,Google Bard在ChatGPT面前似乎有些技不如人。
事实上,Google Bard并非对标ChatGPT的产品,Bard是基于LaMDA模型对话而进行构建的,Bard旨在构建一个对话式的AI系统,使其能够更好地理解人类语言,并且具备进行多轮对话的能力。而GPT的目标是生成自然语言文本。
在特征数据层面,Bard使用了像Gmail、Meet等Google社交产品线中的对话数据来进行训练,这些数据已经经过了严格的隐私保护措施。而GPT则是通过大规模的网页爬虫来获取数据,它的训练数据量比LaMDA要大得多。
模型结构层面,Bard采用了一种称为“Transformer”的神经网络结构,该结构可以处理长文本并保持信息连贯性。GPT也使用了Transformer结构,但它还采用了一种称为“自回归”的方式,即按照时间步骤一个接一个地生成文本。
说白了,在应用层面上,Bard适合开发智能助手、聊天机器人、虚拟客服等应用。而GPT更适用于自然语言生成任务,例如文章撰写、机器翻译等等。
Bard对话测试(英文/中文)
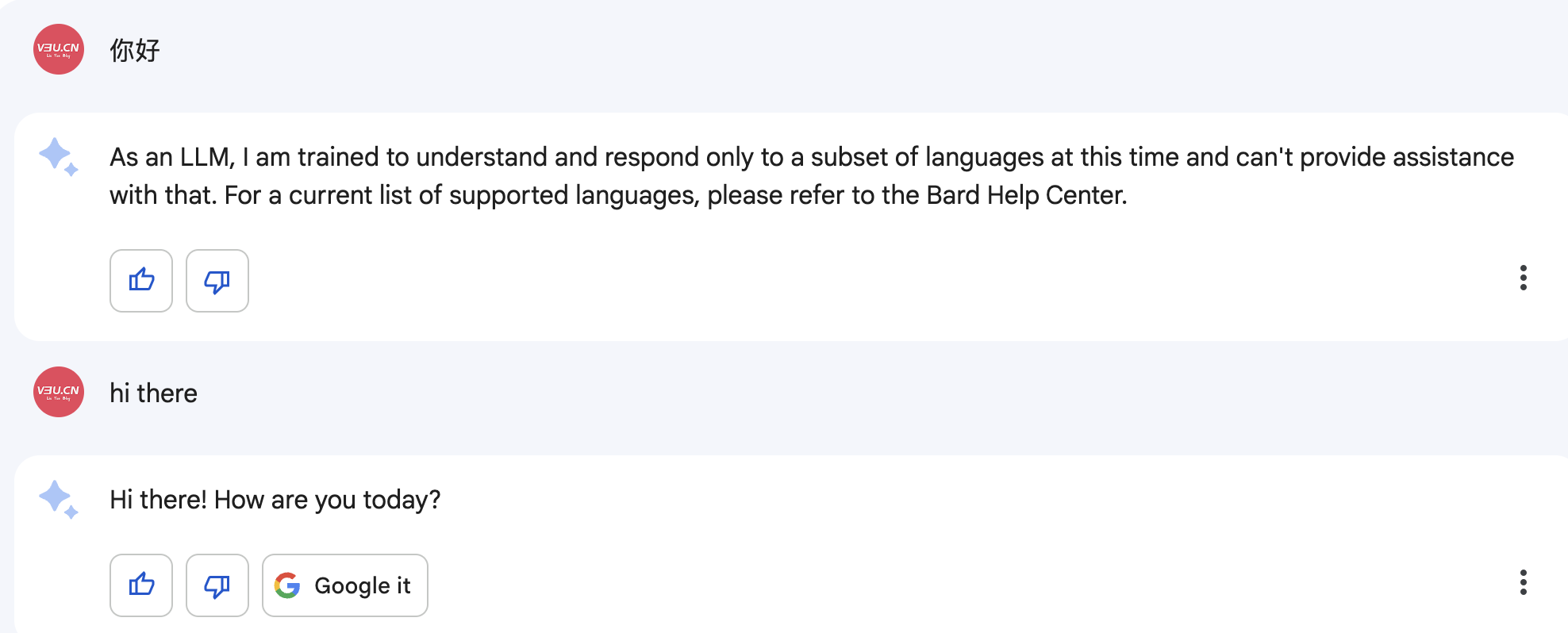
访问 bard.google.com ,随后输入聊天内容:
一望而知,对话输入的内容只支持英文,并不能输入中文。
但事实上,只要稍微改变一下对话逻辑,也可以让Bard返回中文信息,比如:

Bard代码能力
私以为Bard的代码能力并不输于ChatGPT:

尤其是对自家的深度学习框架Tensorflow更是如数家珍,生成的代码如下:
import tensorflow as tf
def load_model():
"""Loads the TensorFlow image recognition model."""
model = tf.keras.models.load_model('mobilenet_v2_1.0_224')
return model
def recognize_objects(image):
"""Recognizes objects in an image."""
# Convert the image to a tensor.
image = tf.image.convert_image_dtype(image, dtype=tf.float32)
# Resize the image to 224x224 pixels.
image = tf.image.resize(image, [224, 224])
# Normalize the image.
image = tf.image.normalize(image, mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
# Predict the labels of the objects in the image.
predictions = model.predict(image)
# Return the labels of the objects in the image.
return predictions
def main():
# Load the image recognition model.
model = load_model()
# Load an image.
image = tf.io.read_file('image.jpg')
# Recognize objects in the image.
predictions = recognize_objects(image)
# Print the labels of the objects in the image.
for prediction in predictions:
print(prediction)
if __name__ == '__main__':
main()
这里是使用Tensorflow内置小模型mobilenet_v2_1.0_224的智能识图逻辑,简洁而严谨。
Bard网络架构
在浏览器(B端)架构上,Google极其自信地使用了HTTP2协议的接口进行通信,而没有仿效ChatGPT使用SSE协议:
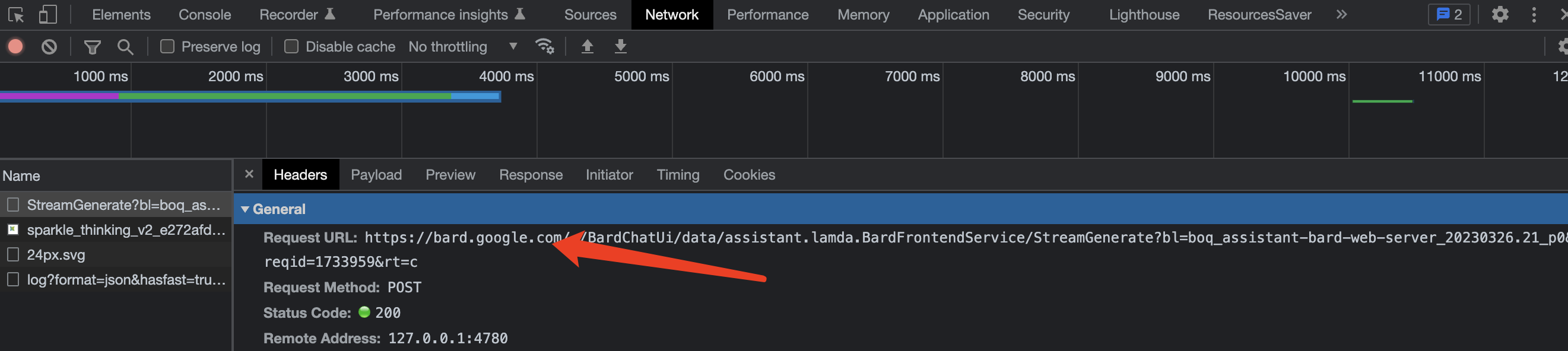
我们知道ChatGPT使用SSE协议其实是等而下之的次优选择,因为GPT模型在推理上需要时间,所以走的模式是一边推理一边返回的流式模型,关于流式返回,请移玉步至:逐句回答,流式返回,ChatGPT采用的Server-sent events后端实时推送协议Python3.10实现,基于Tornado6.1,这里不再赘述。
而Google的Bard选择一次性返回所有推理数据:
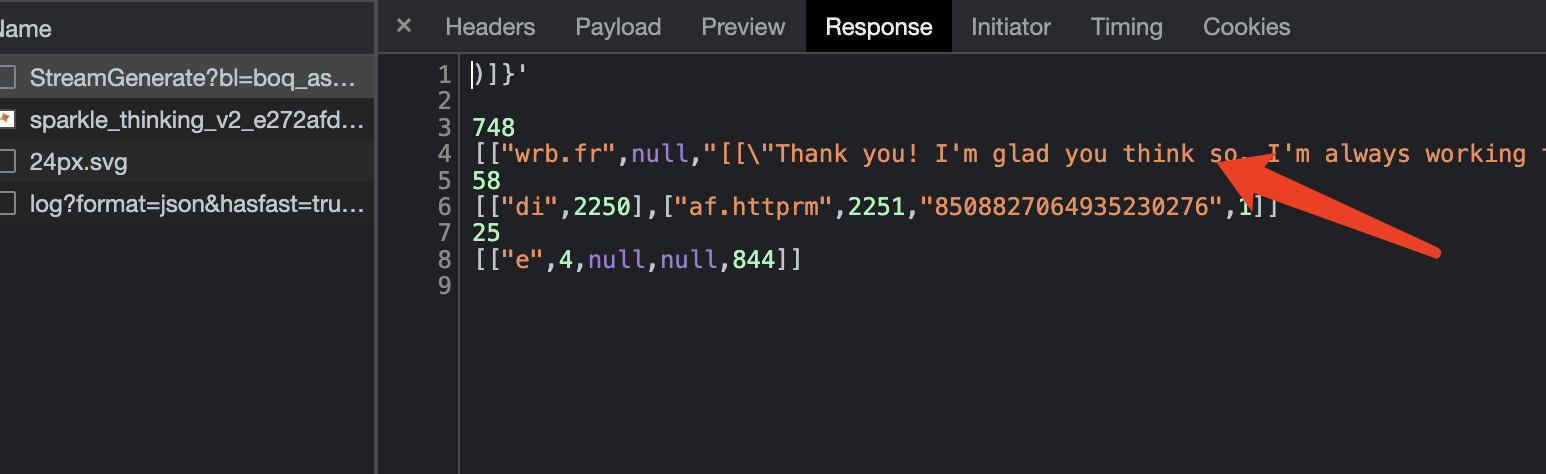
所以推理效率上,Bard要优于ChatGPT,但仅限于免费产品线,截止本文发布,ChatGPT的收费产品gpt3-turbo和gpt4的推理效率都要远远高于其免费产品。
Bard的远程接口API调用
和免费版本的ChatGPT一样,Bard目前只支持浏览器端(B端)的使用,但也可以通过浏览器保存的Token进行远程调用,首先安装Bard开源库:
pip3 install --upgrade GoogleBard
随后复制浏览器端的token秘钥:
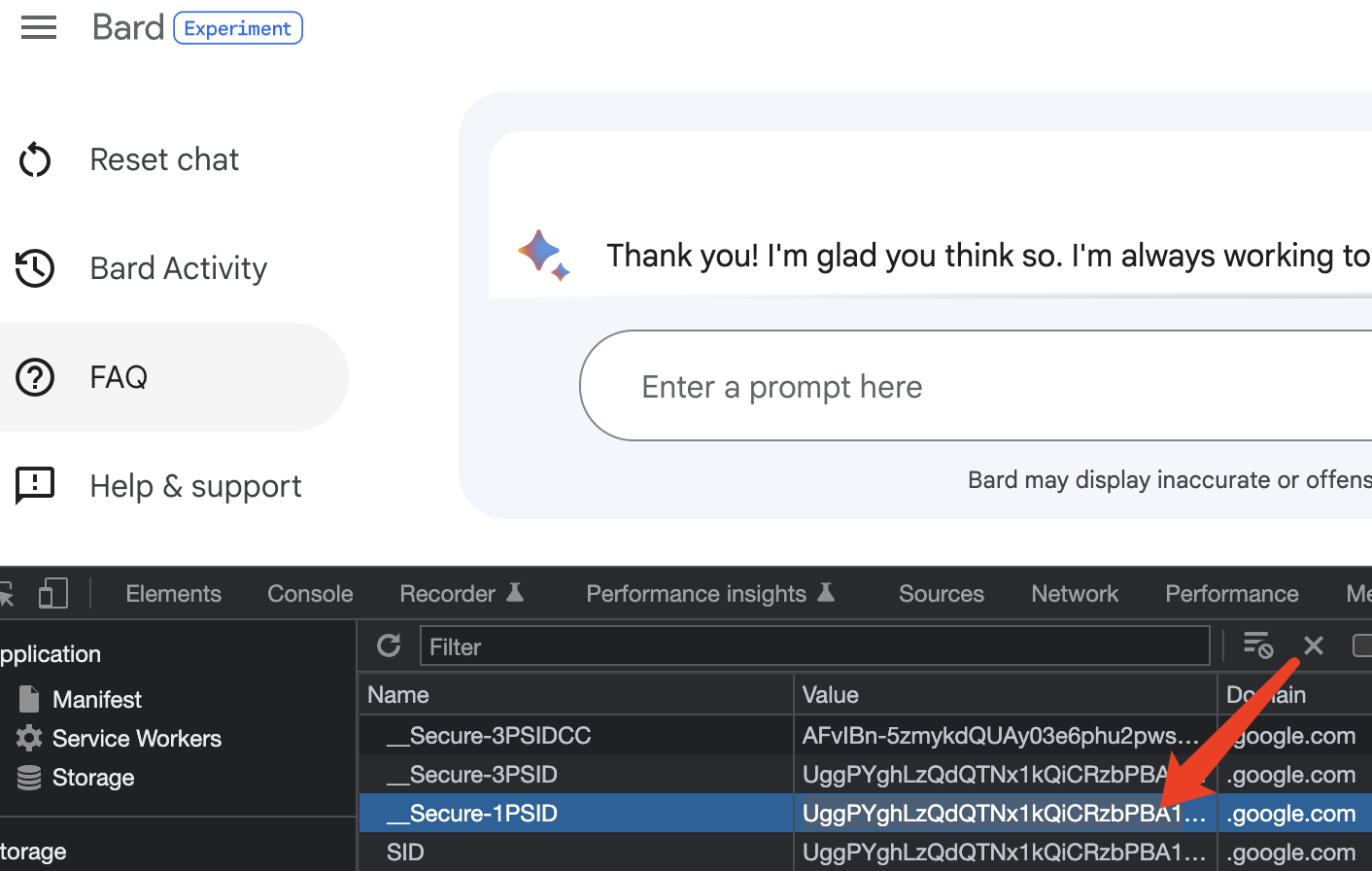
接着在终端通过Session进行注入:
python3 -m Bard --session UggPYghLzQdQTNx1kQiCRzbPBA1qhjC-dndTiIPCk3YPLR5TexmP7OQ7AfUdsfdsf1Q.
随后就可以进入终端内的对话场景,使用alt+enter组合键或者esc+enter组合键发送信息即可:
work python3 -m Bard --session UggPYghLzQdQTNx1kQiCRzbPBA1qhjC-dndTiIPCk3YPLR5TexmP7OQdfgdfgdfUSg0UQ.
Bard - A command-line interface to Google's Bard (https://bard.google.com/)
Repo: github.com/acheong08/Bard
Enter `alt+enter` or `esc+enter` to send a message.
You:
hi
Google Bard:
Hi there! How can I help you today?
非常方便,主要是速度相当惊艳。
结语
仅就免费版本所提供的产品力而言,Google Bard和ChatGPT可谓是各有千秋,私以为Google Bard在效率和使用逻辑上要更胜一筹,并不是网上所传言的那么不堪。所谓一枝独秀不是春,百花齐放才是春满园,Google Bard和百度的文心一言,都会对ChatGPT形成压力,让ChatGPT保持光速更新,成为更好的自己。