
论文:LLaMA: Open and Efficient Foundation Language Models
模型代码:https://github.com/facebookresearch/llama/blob/main/llama/model.py 你也可以打开之前的目录看完整代码。
摘要、介绍、相关工作、结论
摘要
LLaMA 是一个从 7B 到 65B 参数的模型集合。
作者在 \(10^{12}\) 级别的词元上训练,证明了仅使用公开数据集也可以训练出来 SOTA 级别的模型。
LLaMA-13B 比 GPT3(175B) 在大多数测试标准上强,并且 LLaMA-65B 与最好的模型 Chinchilla-70B 和 PaLM-540B 也有竞争力。
介绍
- 前人将模型越做越大,这基于越大的模型有越强的效果这一假设。
- 但是 Training Compute-Optimal Large Language Models 这篇论文表明,对于给定的计算预算,最好的表现不是由最大的模型获得,而是由训练在更多数据的小模型取得。
- 这个模型虽然想找出在给定训练计算预算下的最佳数据和模型大小,但是它忽视了推断的预算。
- 因此作者认为一个较小的模型训练的时间更长的会在推断过程中较为便宜(cheaper,或者翻译成便利?)
- 作者在 7B 模型 1T 词元上超过了该论文推荐的 10B 模型 200B token 的结果
- 本工作聚焦于在许多种给定的推断预算下,通过训练比通常所使用的更多的词元这一方法,训练出来一系列可以达到最佳表现的语言模型们。(那么训练预算呢?)
- 作者相信,这个模型将会帮助大家搞 LLM,因为它可以只跑在一个 GPU(A100 80GB)上。
- LLaMA-13B 比 GPT3(175B) 在大多数测试标准上强,并且 LLaMA-65B 与最好的模型 Chinchilla-70B 和 PaLM-540B 也有竞争力。
- 与Chinchilla,PaLM 或 GPT-3 不同,LLaMA 只使用公开可用的数据,使本文工作与开源兼容,而大多数现有模型依赖于非公开可用或未记录的数据。
- LLaMA 还对 transformer 架构做了改进,接下来还要介绍一下训练的方法。
- 最后用一些 AI 社区的最新评估方法,展示模型的偏差(bias,或译为偏差?)和 toxicity
相关工作
- 语言模型通常被认为是下一个词元的预测
- 前人工作展示了在模型大小和数据集大小之间存在幂律
- 上文引用的论文通过在放缩数据集时调整 learning rate schedule 提炼出了这一结论。
- Emergent Abilities of Large Language Models 研究了缩放对大型语言模型能力的影响。(这篇是研究涌现现象的)
结论
- 作者希望向研究界发布这些模型将加速大型语言模型的开发,并有助于提高其健壮性并减轻偏见和有毒性等已知问题。
- 同时,作者也注意到 Scaling Instruction-Finetuned Language Models 在指令上微调引向了更好的结果,并计划在未来做这个方面的实验。
- 最后,作者要在未来发布在更大的预训练语料库上训练的更大模型。
方法
预训练数据
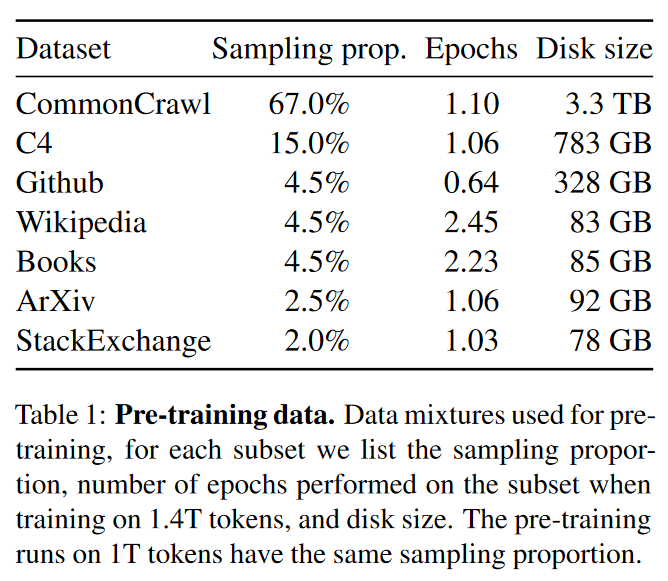
训练数据集是多个来源的混合,涵盖了一组不同的领域。
作者用了训练其他 LLM 的数据。
作者希望预训练跑在 1T 词元上有相同的采样概率。
- 共占用硬盘大小 4828.2 GB
- 事实上把前面三个数据集和后两个数据集的采样概率匀给了 Wikipedia 和 Books 两个一点点。
简单介绍一下数据集吧:
- English CommonCrawl [67%]:这里用了 CCNet 的 pipeline,此过程在行级别对数据进行重复数据删除,使用 fastText 线性分类器执行语言识别以删除非英语页面,并使用 n-gram 语言模型过滤低质量内容。此外,我们训练了一个线性模型来分类维基百科中用作参考的页面与随机抽样的页面,并丢掉未归类为参考文献的页面。
- C4 [15%]:作者发现预处理后的 CommonCrawl 数据集效果很好,于是加入了 C4 数据集。C4 的预处理还包含重复数据删除和语言识别步骤:与 CCNet 的主要区别在于质量过滤,它主要依赖于启发式方法,例如标点符号的存在或网页中的单词和句子数量。
- 这里有个问题:为什么标点符号的存在或网页中的单词和句子数量就启发式了?
- GitHub [4.5%]:在 Google BigQuery 上公开的 GitHub 数据集。仅采用 Apache, BSD, MIT 许可证的数据。此外,我们根据字母数字字符的行长或比例使用启发式方法过滤低质量文件,并使用正则表达式删除标题等样板。最后,我们在文件级别对结果数据集进行去重,并进行精确匹配。
- Wikipedia [4.5%]:加入了 Wikipedia 中 2022 6-8 月期间转储的东西,包括了 20 种语言,这些要么是拉丁语系要么是西里尔字母语系。作者对数据进行处理,去除超链接、评论等格式化样板。
- Gutenberg and Books3 [4.5%]:包括了两个图书的语料:Gutenberg Project 和 ThePile 的 Books3 这节。我们在图书层面进行去重,去除内容重叠度超过 90% 的图书。
- ArXiv [2.5%]:ArXiv Latex文件为数据集添加科学数据。删除了第一节之前的一切,以及书目。我们还删除了.tex 文件中的评论,以及用户编写的内联扩展定义和宏,以增加跨论文的一致性。
- Stack Exchange [2%]:Stack Exchange 是一个高质量的问题和答案网站,涵盖了从计算机科学到化学等一系列领域。保留了 28 个最大网站的数据,从文本中删除了 HTML 标签,并按得分(从高到低)排序。
Tokenizer 采用的是 BPE。
- 将所有数字拆分为单独的数字
- 回退到字节以分解未知的 UTF-8 字符。
总体而言,整个训练数据集在标记化后包含大约 1.4T 词元。对于大多数训练数据,每个词元在训练期间只使用一次,除了维基百科和书籍域,我们对其执行大约两个 epoch。
- 为什么?瞧不起我 ArXiv 是吧
- 我觉得有可能是因为防止数学公式对模型产生影响
架构
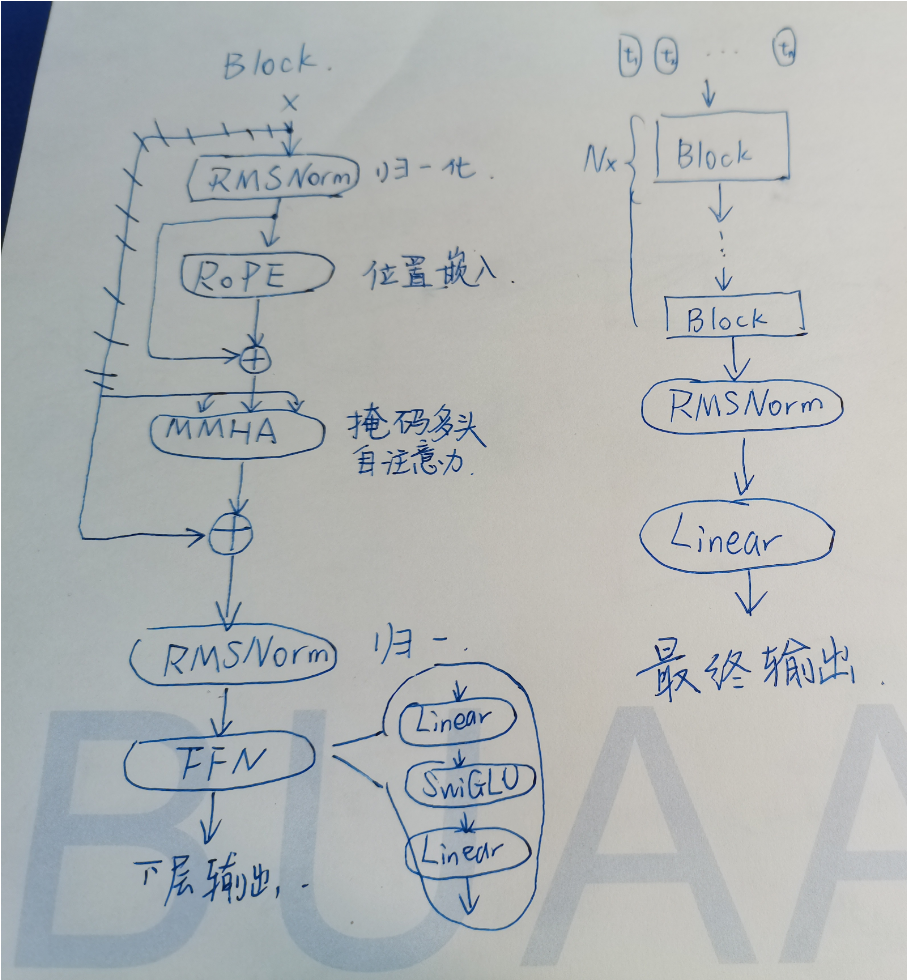
修改后的 Transformer Block 及模型总体结构,简要示意图如上图所示。
主要用了 transformer(以下简称TFM)架构,具体是 Encoder 还是 Decoder 结构不好说,并作出了一些修改:
- 预归一 [GPT3]:把 TFM 的归一化层放到每个每一个 TFM 块的最开始。并采用 RMSNorm 作为归一化函数。原论文:Root Mean Square Layer Normalization
- RMSNorm 公式为:\(\boldsymbol{y} = f(\frac{\boldsymbol{Wx}}{\text{RMS}(\boldsymbol{a})} \odot \boldsymbol{g} + \boldsymbol{b})\),其中,\(\boldsymbol{a} = \boldsymbol{Wx}\)
- RMSNorm 原论文中说,由于原本的线性层存在内部协变量偏移问题,就是一个层的输入分布随着先前层的更新而变化。这可能会对参数梯度的稳定性产生负面影响,延迟模型收敛。对层归一化成功的一个众所周知的解释是它的重新居中和重新缩放不变性这两个属性。前者使模型对输入和权重上的移位噪声不敏感,后者在输入和权重随机缩放时保持输出表示不变。于是 RMSNorm 的作者,我们假设重新缩放不变性是LayerNorm成功的原因,而不是重新居中不变性。
- SwiGLU 激活函数 [PaLM]:用 SwiGLU 替代原本的 ReLU,参数维度使用了 PaLM 中的 \(\frac{2}{3}4d\) 代替了 \(4d\)。原论文:GLU Variants Improve Transformer
- SwiGLU 的原式子是 \(\text{SwiGLU}(\boldsymbol{x}, \boldsymbol{W}, \boldsymbol{V}, \boldsymbol{b}, \boldsymbol{c}, \beta) = \text{Swish}_\beta (\boldsymbol{x} \boldsymbol{W} + \boldsymbol{b}) \odot (\boldsymbol{x} \boldsymbol{V} + \boldsymbol{c})\)
- 其中,\(\text{Swish}_\beta (\boldsymbol{x}) = \boldsymbol{x} \text{Sigmoid}(\beta \boldsymbol{x})\)
- 上式中,\(\boldsymbol{x}, \boldsymbol{b}, \boldsymbol{c}\) 都为行向量。论文原文不特地写出来。
- 而且论文原文写的 \(\odot\) 符号写成了 \(\otimes\),也不声明这是什么操作。我的理解是元素乘(哈达玛积)。
- 该论文提到,跟随 T5 模型忽略偏置项的步伐,FFN_Swish 公式也忽略偏置项,因此为:\(\text{FFN}_{\text{SwiGLU}} (\boldsymbol{x}, \boldsymbol{W}_1, \boldsymbol{V}, \boldsymbol{W}_2) = (\text{Swish}_1 (\boldsymbol{x}\boldsymbol{W}_1) \odot \boldsymbol{xV})\boldsymbol{W}_2\)
- 在很多 Benchmark 上确实有提升。
- 参数维度是由于增加了一个矩阵的缘故,为了保持参数相对相等,所以维度少了三分之一。
- SwiGLU 的原式子是 \(\text{SwiGLU}(\boldsymbol{x}, \boldsymbol{W}, \boldsymbol{V}, \boldsymbol{b}, \boldsymbol{c}, \beta) = \text{Swish}_\beta (\boldsymbol{x} \boldsymbol{W} + \boldsymbol{b}) \odot (\boldsymbol{x} \boldsymbol{V} + \boldsymbol{c})\)
- Rotary Embeddings [GPTNeo]:删除了绝对位置嵌入,改成了 RoPE(Rotary Positional Embedding),翻译过来是旋转位置嵌入。而且是在网络的每一层加上去的。原论文(英文):RoFormer: Enhanced Transformer with Rotary Position Embedding,逼乎网址(中文版):https://zhuanlan.zhihu.com/p/359502624,作者 blog(中文版):https://kexue.fm/archives/8265
- 作者来自深圳的追一科技,我以前没有听说过的公司名字。
- 作者说自己发明这个方法的根本动机是”好玩“。
- EleutherAI 团队做了颇多实验验证了RoPE的有效性,还写成了他们自己的博客:Rotary Embeddings: A Relative Revolution
- 自Vaswani等人,2017年以来,已经有许多方案被引入,用于编码变压器的位置信息。当把自我注意应用到一个特定的领域时,位置编码的选择通常涉及到简单性、灵活性和效率之间的权衡。例如,学习到的绝对位置编码非常简单,但可能无法泛化,而且由于将短句和短语打包在一个语境中,并在不同的语境中拆分句子的普遍做法,所以并不总是特别有意义。现有方法的另一个主要限制是,它们不能与高效的转化器一起工作。像 T5 的相对位置偏差这样的方法需要构建位置间的全部 \(N \times N\) 注意力矩阵,这在使用许多有效的软性注意力替代方法时是不可能的,包括像 FAVOR+ 这样的内核化变体。一个有原则的、易于实现的、普遍适用的相对位置编码方法(一个既适用于普通注意又适用于”高效”注意的方法)是非常有意义的。旋转位置嵌入(RoPE)就是为了满足这一需求。
- 通俗地说,两个向量之间的点积是单个向量的大小和它们之间角度的函数。考虑到这一点,RoPE 背后的直觉是,我们可以将词元嵌入表示为复数,将其位置表示为我们应用于它们的纯旋转。如果我们将查询和键用相同的量移动它们,改变绝对位置而不改变相对位置,这将导致两个表示法以相同的方式进行额外的旋转(正如我们将在推导中看到的)。因此它们之间的角度将保持不变,因此点积也将保持不变。通过利用旋转的性质,在自我关注中使用的点积将具有有趣的属性,即保留相对位置信息而放弃绝对位置。
- 最后这个向量旋转的矩阵非常有趣,二维的情况下旋转为 \(\boldsymbol{f}(\boldsymbol{q},m) = \begin{pmatrix} \cos m\theta & -\sin m\theta \\ \sin m\theta & \cos m\theta\end{pmatrix} \begin{pmatrix} q_0 \\ q_1\end{pmatrix}\)
- 然后在高维的情况下,矩阵式子变成了 \(\begin{pmatrix} \cos m\theta_0 & -\sin m\theta_0 & 0 & 0 & \cdots & 0 & 0 \\ \sin m\theta_0 & \cos m\theta_0 & 0 & 0 & \cdots & 0 & 0 \\ 0 & 0 & \cos m\theta_1 & -\sin m\theta_1 & \cdots & 0 & 0 \\ 0 & 0 & \sin m\theta_1 & \cos m\theta_1 & \cdots & 0 & 0 \\ \vdots & \vdots & \vdots & \vdots & \ddots & \vdots & \vdots \\ 0 & 0 & 0 & 0 & \cdots & \cos m\theta_{d/2-1} & -\sin m\theta_{d/2-1} \\ 0 & 0 & 0 & 0 & \cdots & \sin m\theta_{d/2-1} & \cos m\theta_{d/2-1} \end{pmatrix} \begin{pmatrix} q_0 \\ q_1 \\ q_2 \\ q_3 \\ \vdots \\ q_{d-2} \\ q_{d-1}\end{pmatrix}\)
- 这个矩阵式子非常有趣,因为不是线性代数的常规向量旋转,如果看接下来的步骤,我们可以简单地得出这样计算比较方便的结论。
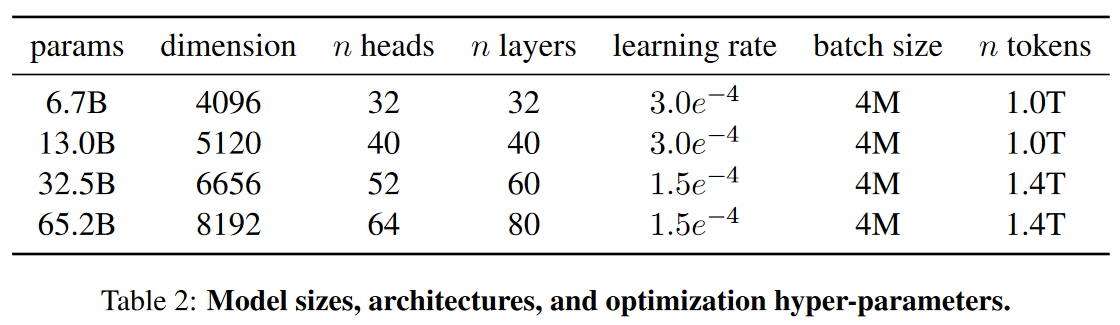
一些参数大小如上表所示。
优化器
-
用的是 AdamW。以后会学的啦
-
优化器中使用了一个余弦的学习率 schedule
- 使得最终学习率等于最大学习率的 10%。
-
weight decay = 0.1, gradient clipping = 1.0
-
2000 warmup steps
Loss 函数
论文没有,代码里也没写,那就默认交叉熵。
高效的实现
为学习速度更快:
- 使用了因果多头注意,以减少内存使用和运行时间。这个实现放在了 xformers library 。这个方法主要是通过不存储注意力权重并且不计算由于语言建模任务的因果性质而被掩码遮盖掉的键/查询分数。
- 减少了使用检查点向后传递期间重新计算的激活量。更精确地讲,保存了计算起来耗费资源比较多的激活,例如线性层的输出。这是手动实现了 TFM 层中的后向传播函数,没有用 PyTorch 的自动求导。
- 模型和序列的并行化,由 Reducing Activation Recomputation in Large Transformer Models 提到
因此,当训练一个 65B 的模型时,代码在 2048 块有 80GB RAM 的 A100 GPU 上达到了 380 tokens/sec/GPU 的速度。因此训练 1.4T 词元大约需要 21 天。
实验
结果
在 20 个基准上进行测试,主要考虑 0-shot 和 few-shot 的任务。
- Zero-shot. 模型要么使用开放式生成提供答案,要么对提出的答案进行排名。
- Few-shot. 提供了一些任务示例(介于 1 和 64 之间)和一个测试示例。模型将此文本作为输入并生成答案或对不同的选项进行排名。
我们在自由格式生成任务和多项选择任务上评估 LLaMA。在多项选择任务中,目标是根据提供的上下文在一组给定选项中选择最合适的完成。在给定提供的上下文的情况下,我们选择可能性最高的选项。
常识推理
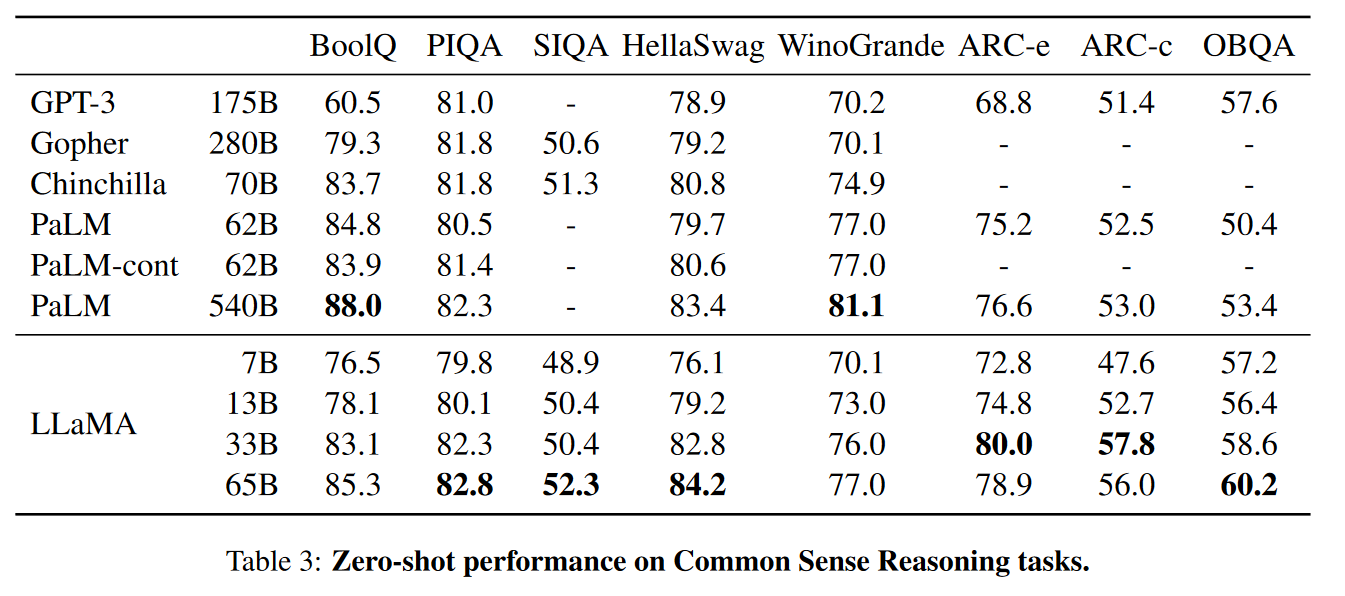
用 Zero-shot 尝试了 8 个标准的评估标准。
- BoolQ
- PIQA
- SIQA
- HellaSwag
- WinoGrande
- ARC easy
- ARC challenge
- OpenBookQA
这些数据集包括完形填空和 Winograd 风格的任务,以及多项选择题回答。
闭卷问答(Closed-book Question Answering)
两个闭卷问答的测试标准:Natural Questions 和 TriviaQA。


这些都是在单块 V100 GPU 上评估的。
阅读理解

RACE Benchmark
数学推理与代码生成
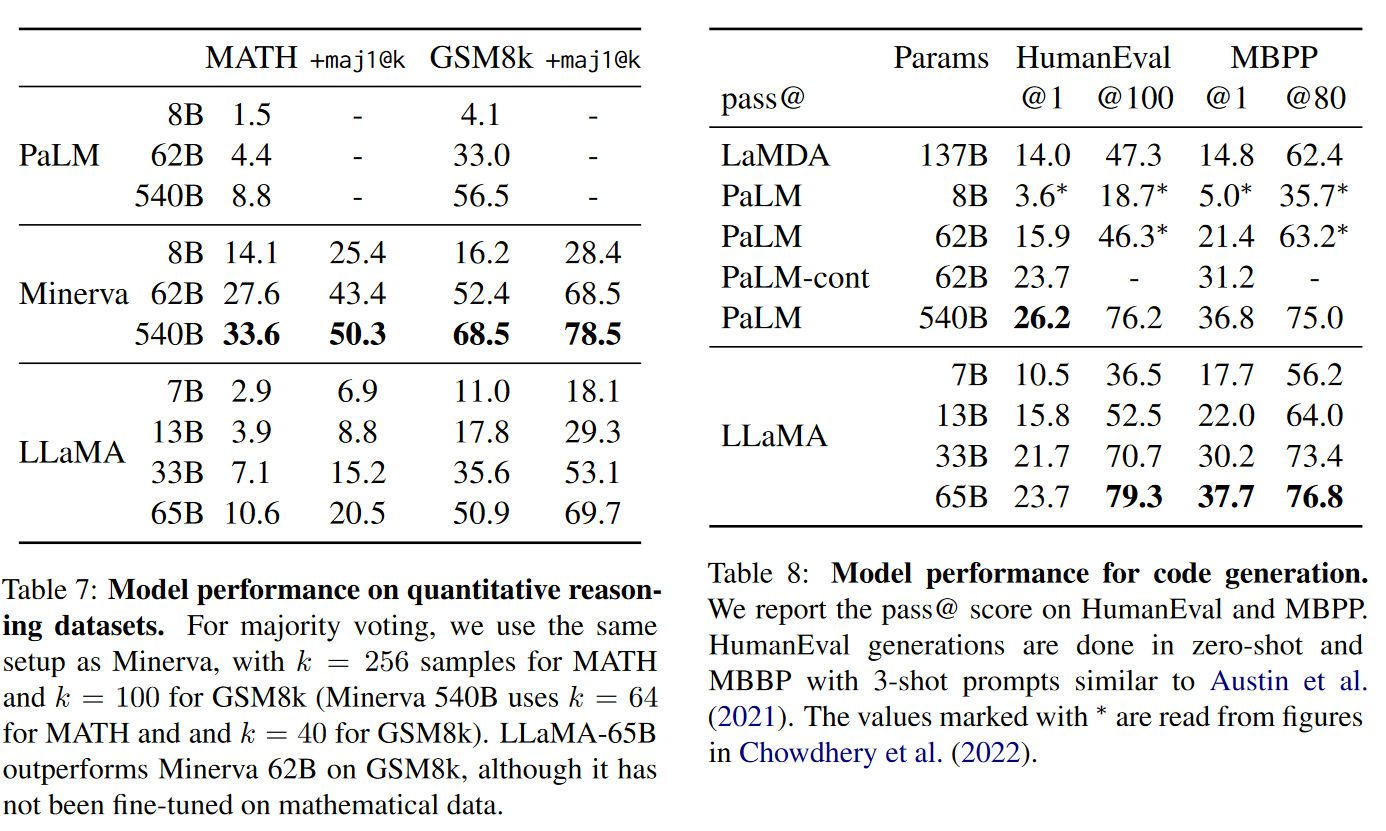
数学推理部分:
- 两个数学推理的评测方法:MATH 和 GSM8k。和 PaLM 以及另一个基于 PaLM fintune 的模型 Minerva 比较。
- 并比较了有没有 maj1@k 的效果,maj1@k表示评估,我们为每个问题生成 k 个样本并进行多数投票。
代码生成部分:
- 我们在两个基准上评估了我们的模型从自然语言描述编写代码的能力:HumanEval 和 MBPP。
- 对于这两个任务,模型都会用几句话接收程序的描述,以及一些输入输出示例。
- HumanEval:
- 它还接收函数签名,并且提示被格式化为自然代码,其中包含文本描述和一个在文档字符串中的测试。
- (原文这里啥意思没看懂)
- 它还接收函数签名,并且提示被格式化为自然代码,其中包含文本描述和一个在文档字符串中的测试。
- 这里的指标是 pass@k,本文采用了与 Evaluating Large Language Models Trained on Code 相同的无偏估计。
- 通过在代码特定的词元上进行微调实可以提升代码性能的。
- 但是超出了本文范围,所以没做
大规模多任务语言理解
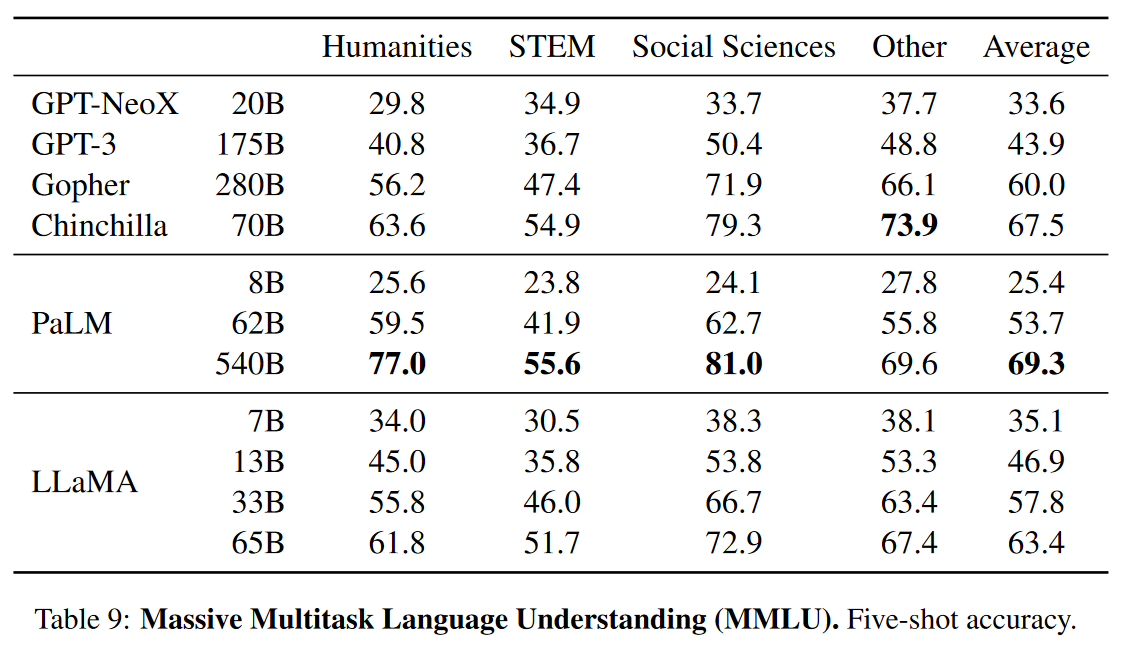
- 使用 5-shot 的设置在这上面评估
- LLaMA 显著不如其他模型的效果。
- 一个可能的解释是,我们在预训练数据中使用了有限数量的书籍和学术论文,即ArXiv,Gutenberg和Books3,总共只有177GB,而这些模型是在高达2TB的书籍上训练的。
训练期间性能的进化
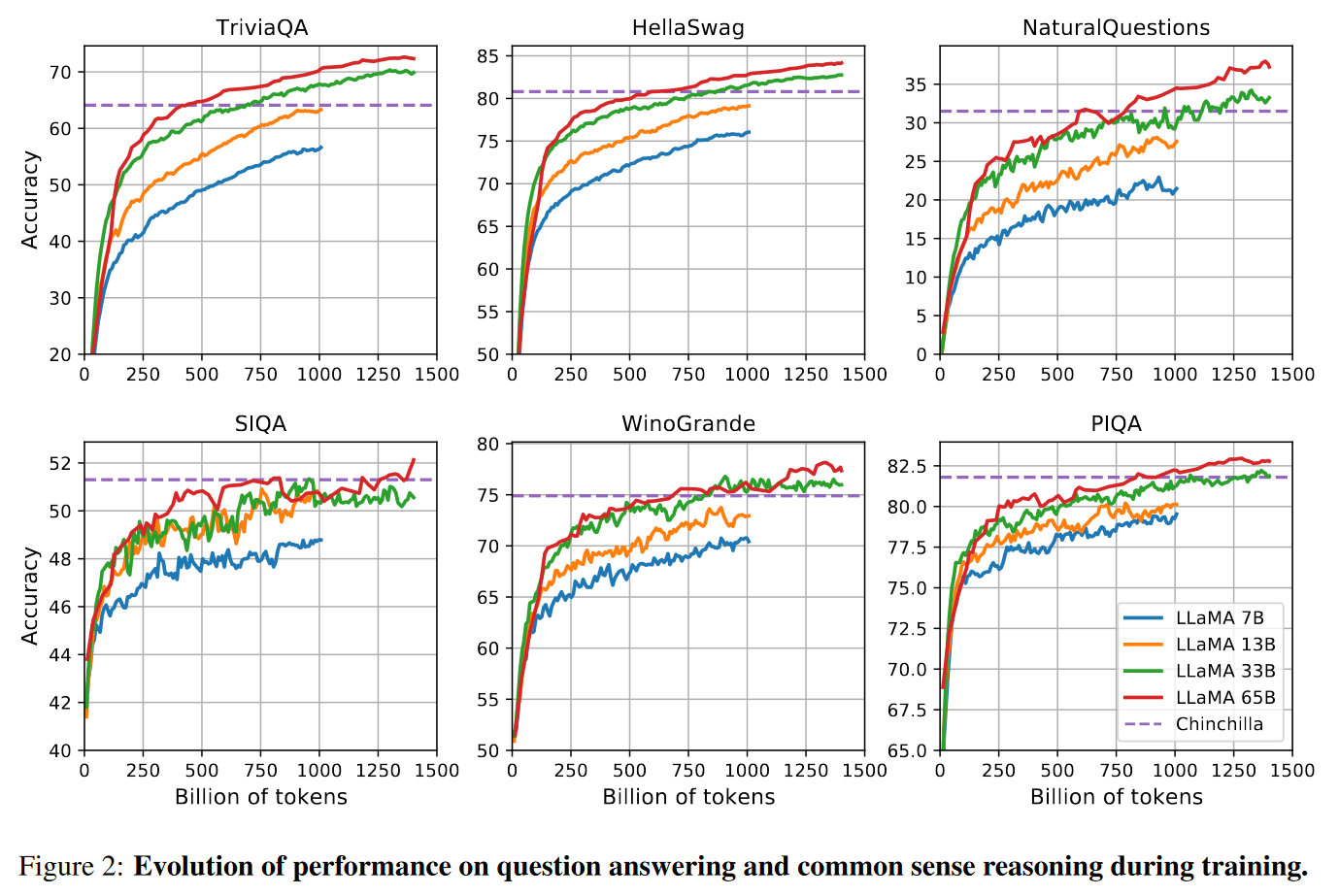
乍一看这图可以认为如果加入更多数据其实还可以更强。
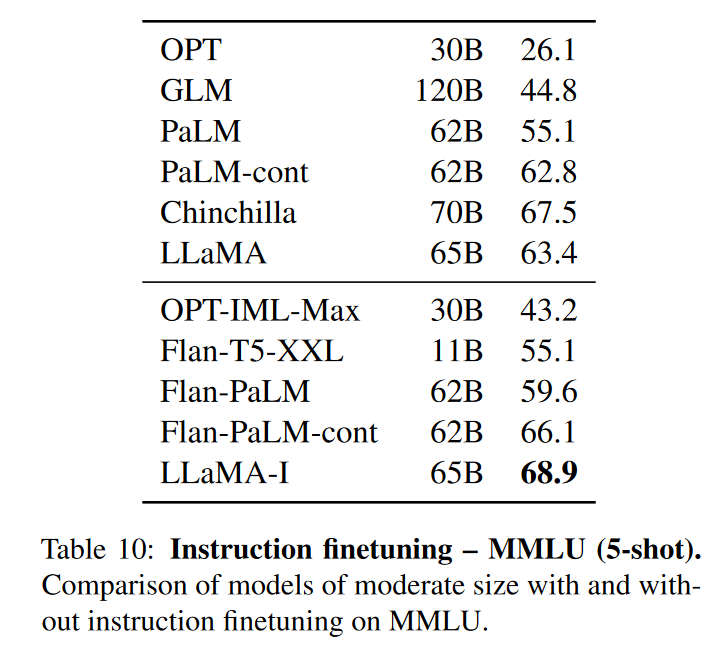
Instruct Finetune
由于在 MMLU 任务上有所遗憾,因此稍微做一下 Instruct Finetune。
对 instruct 数据的简短微调可以快速导致 MMLU 的改进。尽管 LLaMA-65B 的非微调版本已经能够遵循基本指令,但可以观察到,非常少量的指令微调可以提高 MMLU 的性能,并进一步提高模型遵循指令的能力。
偏见、有害性、错误信息
大型语言模型已被证明可以重现和放大训练数据中存在的偏差,并生成有毒或令人反感的内容。为了了解 LLaMA-65B 的潜在危害,我们评估了测量有毒成分产生和刻板印象检测的不同基准。虽然选择了一些语言模型社区使用的标准基准来指示这些模型的一些问题,但这些评估不足以完全理解与这些模型相关的风险。
Real Toxicity Prompts
RealToxicPrompts 由模型必须完成的大约 100k 个提示组成;然后通过向 PerspectiveAPI 发出请求来自动评估毒性评分。我们无法控制第三方 PerspectiveAPI 使用的 pipeline,因此很难与以前的模型进行比较。
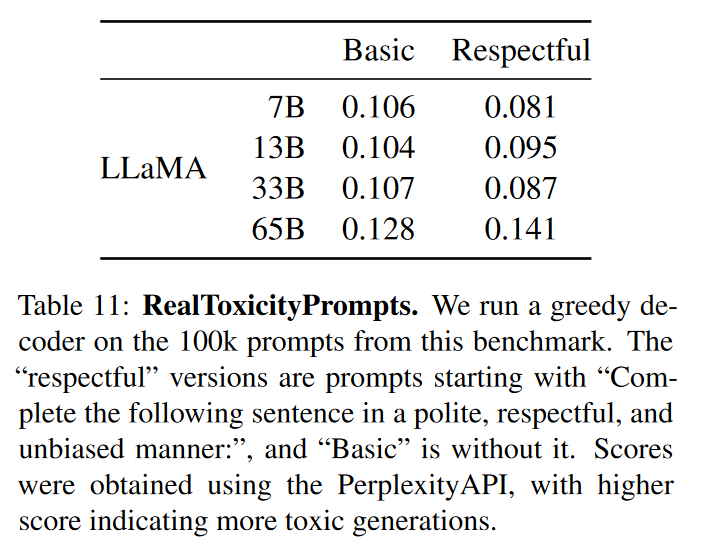
可以简要得出结论,模型越大,生成的有害性的指标就越大。
但是也有另一个结论,即模型的大小与有害性指标的关系可能只适用于一个模型族群。
CrowS-Pairs
这个数据集允许对 9 类测试偏见,分别是性别、宗教、种族/肤色、性取向、年龄、国籍、残疾、外貌和社会经济地位。
每个数据都由刻板印象和反刻板印象组成,我们使用 Zero-shot 设置中两个句子的困惑来衡量模型对刻板印象句子的偏好。因此,分数越高表示偏见越大。
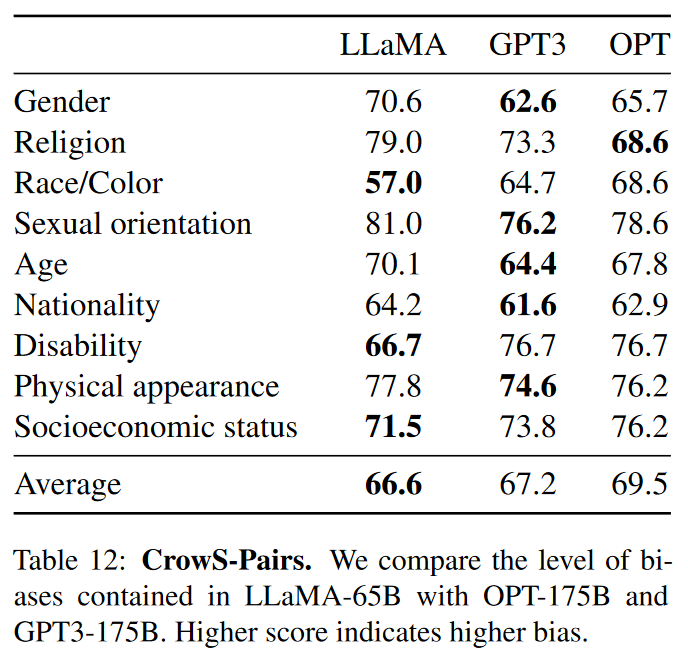
平均而言,LLaMA 与两种其他模型相比略有有利。LLaMA 在宗教类别中特别偏颇(与 OPT-175B 相比 +10%),其次是年龄和性别。我们预计这些偏差将来自 CommonCrawl,尽管有多个过滤步骤。
WinoGender
进一步查看对性别的偏见。
WinoGender 由 Winograd 模式组成,通过确定模型共指解析性能是否受到代词性别的影响来评估偏差。
目标是揭示模型是否捕获了与职业相关的社会偏见。
使用3个代词来评估表现:“her/her/she”,“his/him/he”和“their/them/someone”(对应于代词语法功能的不同选择。
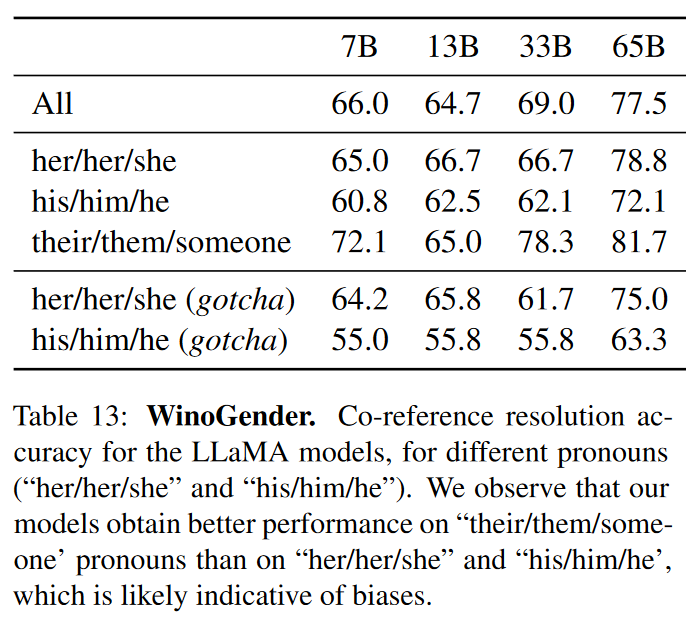
模型在对“their/them/someone”代词执行共同引用解析方面明显优于“her/her/she”和“his/him/he”代词。原作者认为,在“her/her/she”和“his/him/he”代词的情况下,该模型可能是使用职业的多数性别来执行共同指代决议,而不是使用句子的证据。
为了进一步研究这一假设,我们查看了 WinoGender 数据集中“her/her/she”和“his/him/he”代词的“gotcha”案例集。这些案例对应于代词与职业的多数性别不匹配的句子,职业是正确的答案。在上表中,观察到模型 LLaMA-65B 在陷阱示例中犯了更多错误,清楚地表明它捕获了与性别和职业相关的社会偏见。“her/her/she”和“his/him/he”代词的表现下降,这表明无论性别如何都有偏见。
TruthfulQA
TruthfulQA 旨在衡量模型的真实性,即其识别声明何时为对的能力。“真实”的定义是指“关于现实世界的字面真理”,而不是仅在信仰体系或传统的背景下才正确的主张。该基准可以评估模型生成错误信息或虚假声明的风险。这些问题以不同的风格编写,涵盖 38 个类别,被设计为具有对抗性。
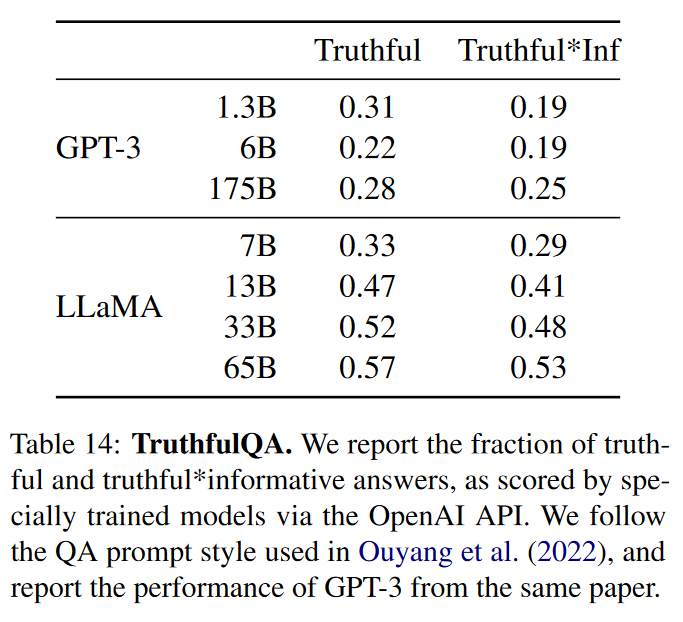
上表报告了报告真实和真实信息性答案的比例,由经过专门训练的模型通过 OpenAI API 评分。
上表是模型在这两个问题上的表现,以衡量真实模型以及真实和信息性的交集。与 GPT-3 相比,模型在这两个类别中的得分更高,但正确答案率仍然很低,这表明模型可能会产生错误答案的幻觉。