原文地址:https://www.postgresql.fastware.com/blog/inside-logical-replication-in-postgresql#Architecture
简介 Introduction
逻辑复制是一种将数据变更从发布服务器复制到订阅服务器的方法。定义发布内容的节点称为发布者(publisher),定义订阅关系的节点称为订阅者(subscriber)。逻辑复制技术提供了对数据复制过程和安全性的细粒度控制。
逻辑复制采用发布-订阅模型,允许一个或多个订阅者订阅发布者节点上的一个或多个发布内容。订阅者从所订阅的发布内容中拉取数据,并可选择将数据重新发布,从而实现级联复制或更复杂的配置架构。
应用场景 Use cases
实时增量同步:将单个数据库或数据库子集发生的变更实时发送至订阅端
触发机制响应:在订阅端为接收到的每条数据变更执行触发器
多库数据聚合:将多个源库数据合并至单一目标库(适用于分析场景)跨版本兼容:支持不同主版本PostgreSQL实例间的数据复制
跨平台同步:实现异构平台间的数据同步(如Linux至Windows)
权限隔离管理:为不同用户组提供差异化的数据访问权限
数据子集共享:在多个数据库间安全地共享特定数据子集
架构 Architecture
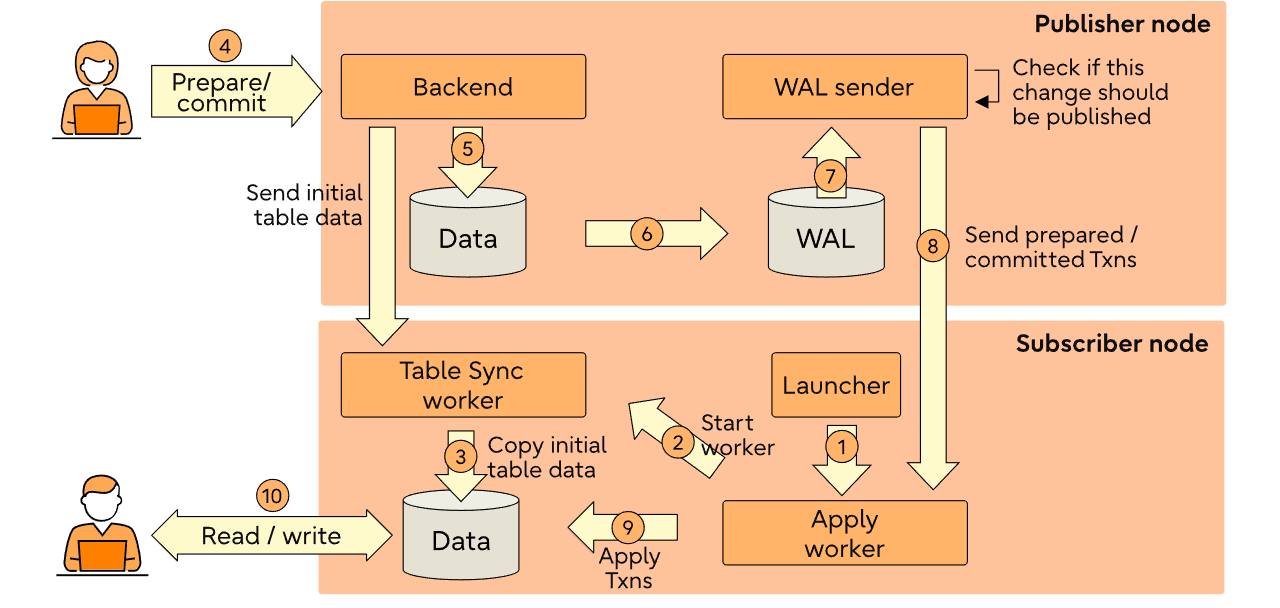
下面,我将详细介绍 PostgreSQL 15 中逻辑复制的工作原理。在本文的后续部分,我还会再次提及这个图表。
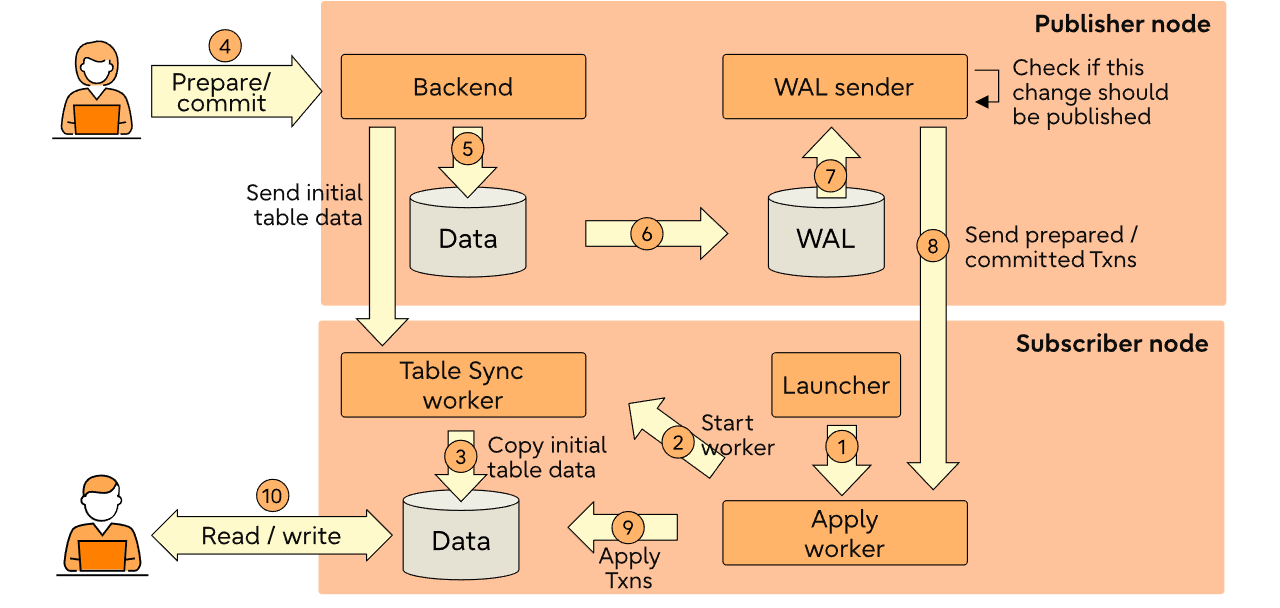
发布者 Publication
publication是定义在主节点上,需要被发布的对象上。发布是从一个表或一组表生成的集合,也可以描述为变更集或复制集。每个发布仅能发布同一个数据库中的表。
每个表可以根据需要添加到多个发布中。当前发布只能包含一部分表,或者可以包含schema中的所有表。
发布可以选择将基于发布对象(表)的INSERT、UPDATE、DELETE和TRUNCATE操作的任意组合,类似于触发器根据特定事件类型触发的方式。默认情况下,所有操作类型都会被复制。
当创建发布时,发布信息将被添加到pg_publication系统目录表中:
postgres=# CREATE PUBLICATION pub_alltables FOR ALL TABLES;
CREATE PUBLICATION
postgres=# SELECT * FROM pg_publication;
oid | pubname | pubowner | puballtables | pubinsert | pubupdate | pubdelete | pubtruncate | pubviaroot
-------+---------------+----------+--------------+-----------+-----------+-----------+-------------+------------
16392 | pub_alltables | 10 | t | t | t | t | t | f
(1 row)
postgres=# CREATE PUBLICATION pub_employee FOR TABLE employee;
CREATE PUBLICATION
postgres=# SELECT oid, prpubid, prrelid::regclass FROM pg_publication_rel;
oid | prpubid | prrelid
-------+---------+----------
16407 | 16406 | employee
(1 row)
information about schema publications is added to pg_publication_namespace catalog table:
postgres=# CREATE PUBLICATION pub_sales_info FOR TABLES IN SCHEMA marketing, sales;
CREATE PUBLICATION
postgres=# SELECT oid, pnpubid, pnnspid::regnamespace FROM pg_publication_namespace;
oid | pnpubid | pnnspid
-------+---------+-----------
16410 | 16408 | marketing
16411 | 16408 | sales
(2 rows)
订阅 Subscription
订阅是逻辑复制的下游对象,它定义了与一个数据库的连接以及它想要订阅的一组发布(一个或多个)。
订阅者数据库的行为与其他任何 PostgreSQL 实例相同,并且自己可以作为发布,让其他数据库来订阅,用以实现级联复制。一个实例可以订阅多个发布,一个订阅者节点可以拥有多个订阅。在单个发布者-订阅者对之间也可以定义多个订阅,但在这种情况下必须注意确保订阅的发布对象没有重叠。
每个订阅将通过一个复制槽(replication slot)接收更改。对于发布的表中已有数据的初始同步,可能需要额外的复制槽,这些复制槽将在数据同步结束时被删除。
当创建订阅之后,订阅信息会记录在pg_subscription系统表里。
postgres=# CREATE SUBSCRIPTION sub_alltables
CONNECTION 'dbname=postgres host=localhost port=5432'
PUBLICATION pub_alltables;
NOTICE: created replication slot "sub_alltables" on publisher
CREATE SUBSCRIPTION
postgres=# SELECT oid, subdbid, subname, subconninfo, subpublications FROM pg_subscription;
oid | subdbid | subname | subconninfo | subpublications
-------+---------+------------------+------------------------------------------+-----------------
16393 | 5 | sub_alltables | dbname=postgres host=localhost port=5432 | {pub_alltables}
(1 row)订阅节点会连接到发布端,获取发布端发布的表,在之前的示例中,我们创建了一个叫pub_alltables 的发布,并且发布了所有的表,订阅包含的表,会记录在pg_subscription_rel 这个系统表中
postgres=# SELECT srsubid, srrelid::regclass FROM pg_subscription_rel;
srsubid | srrelid
---------+---------
16399 | accounts
16399 | accounts_roles
16399 | roles
16399 | department
16399 | employee
(5 rows)订阅连接到发布,并且创建一个复制槽(replication slot),这个信息记录在系统表pg_replication_slots
postgres=# SELECT slot_name, plugin, slot_type, datoid, database, temporary,
active, active_pid, restart_lsn, confirmed_flush_lsn FROM pg_replication_slots;
slot_name | plugin | slot_type | datoid | database | temporary | active | active_pid | restart_lsn | confirmed_flush_lsn
---------------+----------+-----------+--------+----------+-----------+--------+------------+-------------+---------------------
sub_alltables | pgoutput | logical | 5 | postgres | f | t | 24473 | 0/1550900 | 0/1550938
(1 row)订阅的状态信息保存在pg_stat_subscription系统表中
postgres=# SELECT subid, subname, received_lsn FROM pg_stat_subscription;
subid | subname | received_lsn
-------+-----------------+----------------
16399 | sub_alltables | 0/1550938
(1 row)“创建订阅”命令的初始部分将会完成并返回给用户。其余的工作将在后台由replication launcher, walsender, apply worker, 和tablesync worker 来完成,这些工作会在“创建订阅”命令完成后进行。
订阅端后台进程Processes
Replication launcher
此进程由postmaster进程在实例启动时启动。它会定期检查 pg_subscription 系统表,以查看是否有新的订阅被添加或启用。logical replication launcher利用后台工作进程架构(background worker infrastructure )来为每个启用的订阅启动逻辑复制工作进程。vignesh 24438 /home/vignesh/postgres/inst/bin/postgres -D subscriber
vignesh 24439 postgres: checkpointer
vignesh 24440 postgres: background writer
vignesh 24442 postgres: walwriter
vignesh 24443 postgres: autovacuum launcher
vignesh 24444 postgres: logical replication launcher
一旦logical replication launcher进程确认新订阅已创建或已启用,它就会启动一个 apply worker进程。
创建完订阅发布之后,订阅端的apply 进程如下
vignesh 24438 /home/vignesh/postgres/inst/bin/postgres -D subscriber
vignesh 24439 postgres: checkpointer
vignesh 24440 postgres: background writer
vignesh 24442 postgres: walwriter
vignesh 24443 postgres: autovacuum launcher
vignesh 24444 postgres: logical replication launcher
vignesh 24472 postgres: logical replication apply worker for subscription 16399
vignesh 24473 postgres: walsender vignesh postgres 127.0.0.1(55020) START_REPLICATION
上述信息说明了上述“架构”部分中提到的步骤 1 。
应该工作进程 Apply worker
apply worker将遍历表列表,并启动tablesync workers来同步这些表。每个表都将由一个tablesync worker进行同步操作。
根据“max_sync_workers_per_subscription”配置的设定,多个表同步工作进程(每个表对应一个)将并行运行。
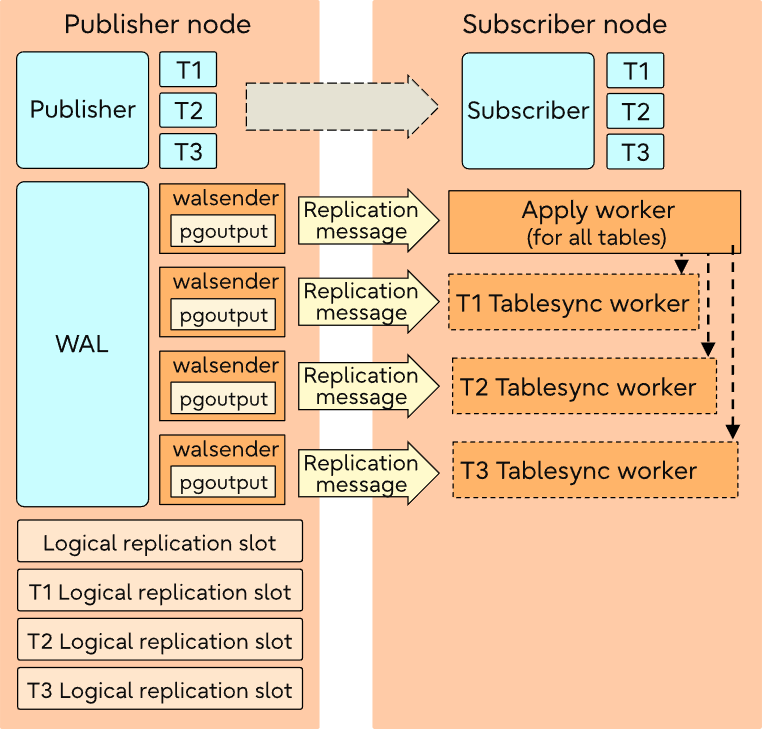
在初始表数据的复制完成之前,apply worker会一直等待,初始数据同步之后,将表状态设置为“就绪”状态(即设置为“pg_subscription_rel”表中的“ready”状态)。
postgres=# SELECT srsubid, srrelid::regclass, srsubstate, srsublsn FROM pg_subscription_rel;
srsubid | srrelid | srsubstate | srsublsn
---------+----------------+------------+-----------
16399 | accounts | r | 0/156B8D0
16399 | accounts_roles | r | 0/156B8D0
16399 | department | r | 0/156B940
16399 | employee | r | 0/156B940
16399 | roles | r | 0/156B978
(5 rows)上述信息说明了上述“架构”部分中提到的步骤 2 。
请注意,当前逻辑复制仅支持DML的复制,不支持DDL的复制。
Tablesync工作进程 Tablesync worker
初始数据同步由独立的tablesync worker进程为每个表单独执行。
创建一个带有USE_SNAPSHOT选项的复制槽,并使用COPY命令复制表数据。
tablesync worker将请求发布者开始从发布者复制数据。
tablesync worker将从walsender同步数据,直到达到由apply worker设置的syncworker的LSN位置。
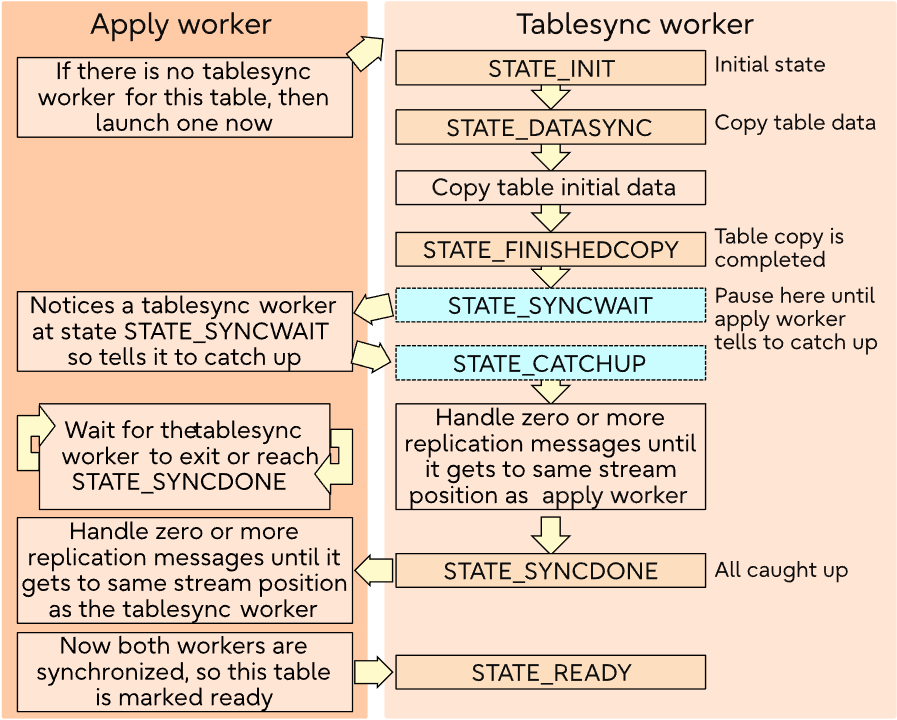
上述信息说明了上述“架构”部分中提到的步骤 3 。
Walsender
当订阅者与发布者建立连接并请求 WAL 时,walender 就会启动。随后,它会逐条读取(decode) WAL 记录,并对其进行解码以获取元组数据和大小。
这些更改会被放入reorderbufferqueue中。reorderbufferqueue按照事务写入 WAL 的顺序收集单个事务的片段。当一个事务完成时,它会重新组装该事务,并通过output插件传递更改。如果reorderbufferqueue的大小超过了logical_decoding_work_mem逻辑解码工作内存的限制,那么就会找到最大的事务并将其移至磁盘。
如果streaming 功能已开启,那么此事务数据将会发送给订阅者,但只有在发布者完成事务提交(committed)后,该数据才会在订阅者端应用(apply)。
一旦事务完成提交,wal发送器将执行以下操作:
1,检查该表是否被发布(基于 publication中指定的ALL TABLES or TABLE list or TABLES IN SCHEMA)
2,检查该操作是否被发布(基于用户指定发布表的选项, insert/update/delete/truncate)
3,如果设置了“publish_via_partition_root”则会更改发布关系的 ID。在这种情况下,将发送祖先关系的 ID。(译者注:这个不太明白是什么意思)
4,检查该行是否应该被发送,基于发布的row filter条件
5,检查该列是否应该被发送,基于发布的指定的column list
然后,wal发送器会更新诸如事务数量、事务字节数、溢出次数、溢出字节数、溢出事务数、流数量、流字节数、流事务数等统计信息。
上述信息说明了《架构》中提到的步骤 7 和 8 。
复制增量数据 Replicating incremental changes
增量更改由 wal发送器和apply worker来处理,具体方式如下所述。
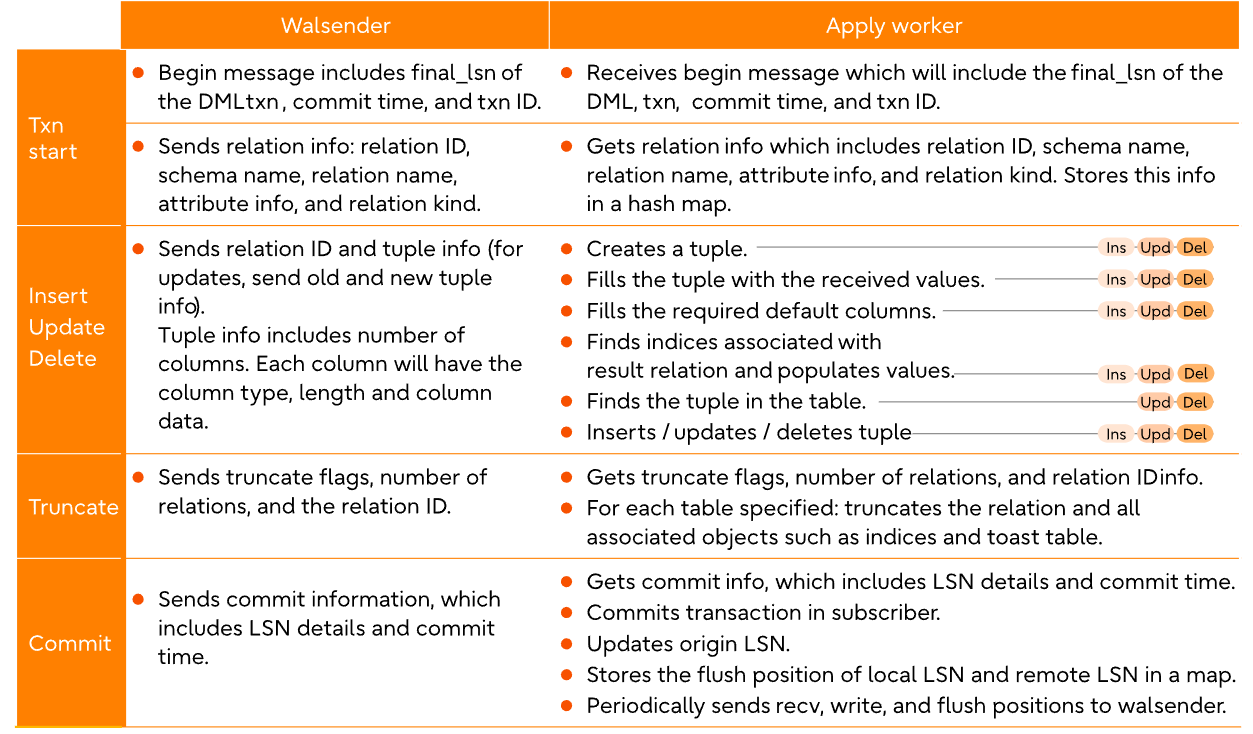
上述信息说明“架构”中提到的步骤9 。
Apply工作进程失败处理 Apply worker failure handling
如果apply worker因错误而失败,那么apply worker进程将会退出。在正常运行过程中,apply worker会保存最后一次事务提交时的起始 LSN。
replication launcher进程会定期检查订阅worker进程是否正在运行。如果replication launcher发现其未运行,那么它将重新启动订阅apply worker进程。apply worker进程将请求从已提交的最后一个源 LSN 开始的复制。walsender 将从apply worker所请求的源 LSN(即最后提交的事务)开始传输事务。
每当apply worker遇到诸如重复约束错误、检查约束错误等约束相关错误时,它就会退出并重复上述步骤。2023-02-22 11:55:51.479 IST [21204] ERROR: duplicate key value violates unique constraint "employee_pkey"
2023-02-22 11:55:51.479 IST [21204] DETAIL: Key (eid)=(1) already exists.
2023-02-22 11:55:51.479 IST [21204] CONTEXT: processing remote data for replication origin "pg_16395"
during message type "INSERT" for replication target relation "public.employee" in transaction 751,
finished at 0/1562C10
如果发生错误,可以选择跳过 LSN(事务序列号)——在这种情况下,用户可以设置忽略失败事务的 LSN。如果用户选择忽略 LSN,应用工作进程将检查该事务是否与指定的 LSN 相匹配,若匹配,则跳过该事务,并继续处理下一个事务。
postgres=# ALTER SUBSCRIPTION sub_alltables SKIP (lsn = '0/1562C10');
ALTER SUBSCRIPTION用户可以使用“disable_on_error”来代替replication launcher启用apply worker的重试步骤。在这种情况下,apply worker 进程中的任何错误都会通过“try() / catch()”捕获,并且在apply worker 进程结束之前会禁用订阅。由于订阅已被禁用,launcher 进程将不会为该订阅重新启动apply worker进程。
postgres=# ALTER SUBSCRIPTION sub_alltables SET (DISABLE_ON_ERROR = 'on');
ALTER SUBSCRIPTION
postgres=# SELECT oid, subname, subdisableonerr, subpublications FROM pg_subscription;
oid | subname | subdisableonerr | subpublications
-------+---------------+-----------------+-----------------
16395 | sub_alltables | t | {pub_alltables}
(1 row)修改订阅 Altering a subscription
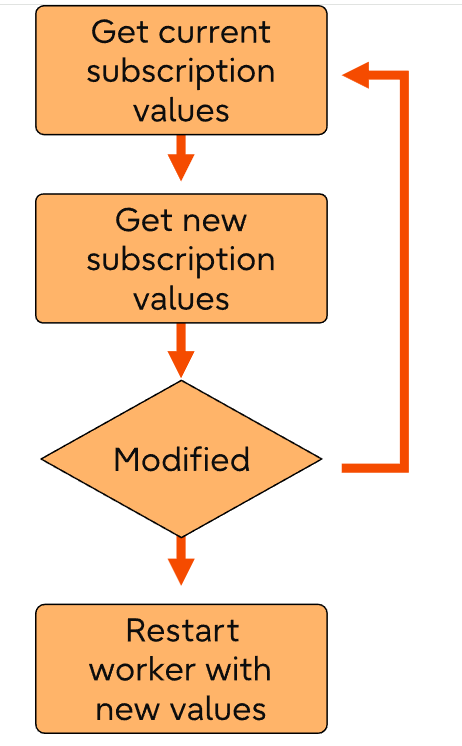
1,apply worker 会定期将当前的订阅值与新的订阅值进行对比——如果两者有所变化的话:
2,apply worker进程退出.
3,launcher进程重启 apply worker进程.
4,apply worker从系统表pg_subscription system中加载新的订阅信息
5,apply worker应用新修改的值
synchronous_commit是如何实现的 How synchronous_commit is achieved
在订阅者端,创建一个包含“synchronous_commit ”选项设置为“on”的订阅。
在发布者端,使用“ALTER SYSTEM SET”命令将“synschronous_standby_names ”选项设置为订阅名称,并通过“pg_reload_conf”重新加载配置。确认在“pg_stat_replication”中“is_sync”选项已启用。
订阅端
postgres=# CREATE SUBSCRIPTION sync
CONNECTION 'dbname=postgres host=localhost port=5432'
PUBLICATION sync
WITH (synchronous_commit = 'on');
NOTICE: created replication slot "sync" on publisher
CREATE SUBSCRIPTION发布端
postgres=# ALTER SYSTEM SET synchronous_standby_names TO 'sync';
ALTER SYSTEM
postgres=# SELECT pg_reload_conf();
pg_reload_conf
----------------
t
(1 row)
postgres=# SELECT application_name, sync_state = 'sync' AS is_sync
FROM pg_stat_replication
WHERE application_name = 'sync';
application_name | is_sync
------------------+---------
sync | t
(1 row)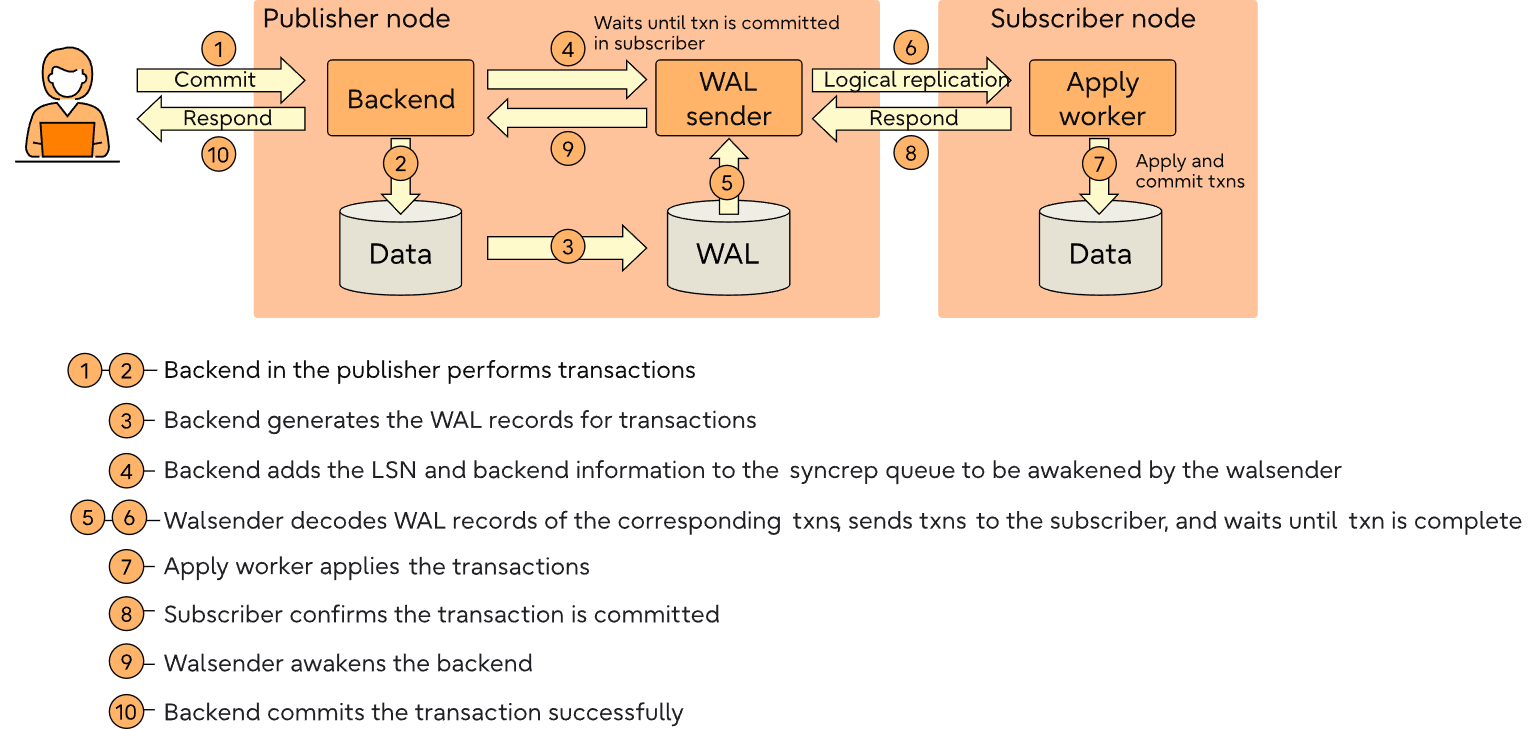
复制槽 Replication slot
一个复制槽的作用在于,即便从订阅者处断开连接,发布者也能保留副本所需的事务日志。
如前所述,每个(活跃的)订阅都会从远程(发布)端的复制槽中获取更新信息。
额外的表同步槽通常是临时性的,它们是在内部创建以进行初始表同步的,当不再需要时会自动删除。
通常情况下,在执行“创建订阅”操作时会自动创建远程复制槽,而在执行“删除订阅”操作时会自动删除该槽。
复制槽位提供了一种自动化的方式,以确保主服务器在收到所有备用服务器的 WAL 段之前不会删除这些段。
行过滤 Row filters
在创建发布内容时,可以指定一个“WHERE”子句。此信息会被存储在“pg_publication_rel”目录表中:
postgres=# CREATE PUBLICATION active_departments FOR TABLE departments WHERE (active IS TRUE);
CREATE PUBLICATION
postgres=# SELECT oid, prpubid, prrelid, pg_get_expr (prqual, prrelid) FROM pg_publication_rel;
oid | prpubid | prrelid | pg_get_expr
-------+---------+---------+------------------
16457 | 16456 | 16426 | (active IS TRUE)
(1 row)不符合此 WHERE 子句的行将由发布者进行过滤。这样可以实现对一组表的部分复制。
在表同步过程中,只有满足行过滤条件的表数据才会被复制到从属端。
如果订阅包含多个发布,并且在这些发布中对同一表使用了不同的筛选条件(针对相同的发布操作),那么这些表达式将进行“或”运算,满足任何一个表达式的行都会被复制。
如果订阅包含多个发布,并且其中至少有一个是通过“ALL TABLES”或“TABLES IN SCHEMA”方式指定的,且该表属于所提及的schema,则这些发布具有优先级,其行为就如同没有行过滤器一样。
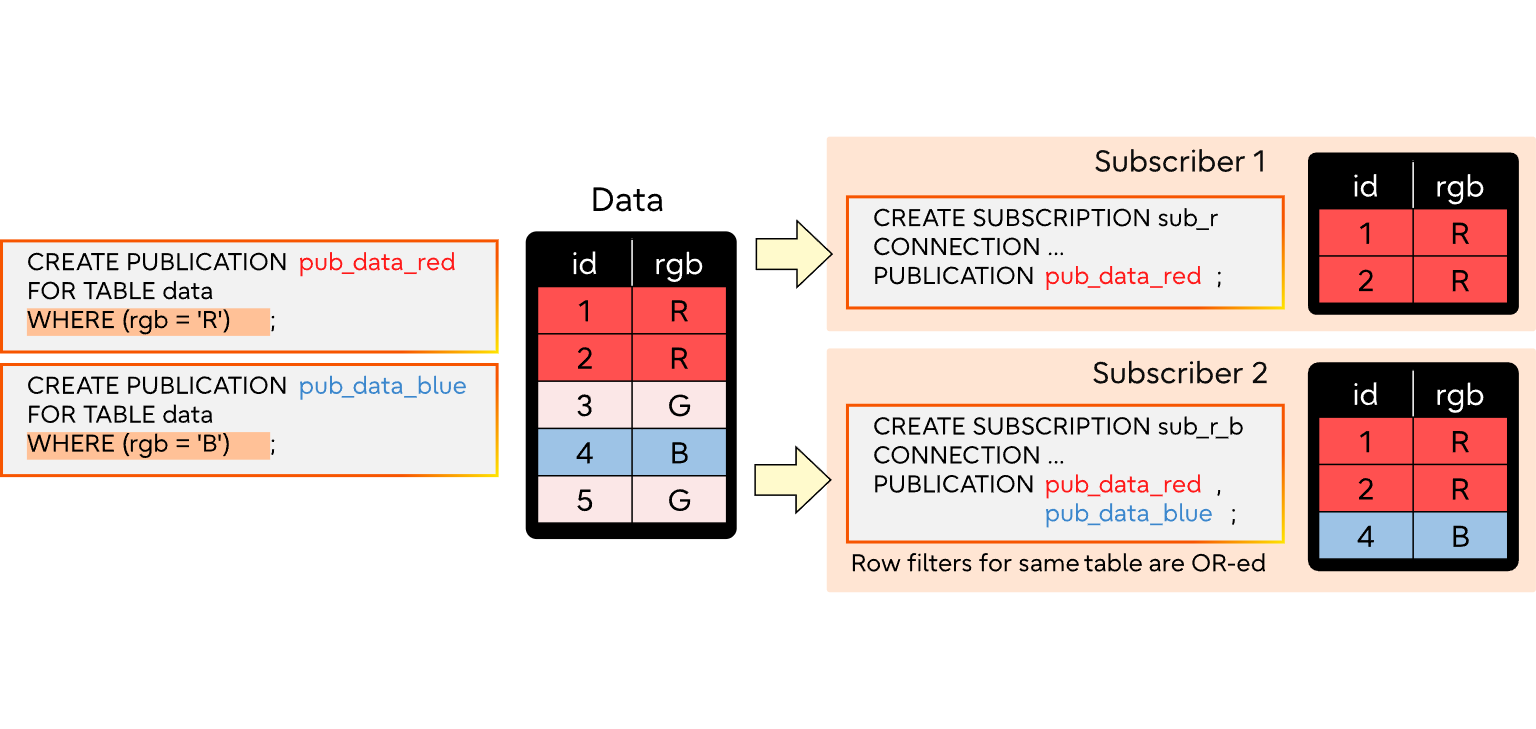
译者注:这里PostgreSQL考虑到了很多异常情况,只要是脑子正常的人,都不会在订阅端同时订阅多个包含同一张表的发布。
复制过滤转换 Replication filters transformation
对于插入操作,发布者会检查新行是否满足行过滤条件,以此来决定是否将新记录发送给订阅者或者直接跳过。
对于删除操作,发布者会检查该行是否满足行过滤条件,以此来决定是否将该操作发送给订阅者或者直接跳过。
更新操作的处理方式略有不同:
1,如果既没有旧行也不存在新行符合行筛选条件:则跳过更新操作。
2,如果旧行不符合行筛选条件,但新行符合:将更新操作转换为在订阅者端插入新行。
3,如果旧行符合行筛选条件但新行不符合:将更新操作转换为从订阅者端删除旧行。
4,如果旧行和新行都符合行筛选条件:则将数据作为更新发送给订阅者,无需任何转换操作。
字段列表 Column lists
在创建发布时,可以指定一个字段列表子句。此信息会存储在 pg_publication_rel 数据库表中:
postgres=# CREATE PUBLICATION users_filtered FOR TABLE users (user_id, firstname);
CREATE PUBLICATION
postgres=# SELECT * FROM pg_publication_rel;
oid | prpubid | prrelid | prqual | prattrs
-------+---------+---------+--------+---------
16453 | 16452 | 16436 | | 1 2
(1 row)
postgres=# SELECT * FROM pg_publication_tables;
pubname | schemaname | tablename | attnames | rowfilter
---------------+------------+-----------+----------------------+-----------
users_filtered | public | users | {user_id, firstname} |
(1 row)
本列表中未包含的列不会发送给订阅者。这样就使得订阅者的数据schema能够成为发布者数据schema的子集,如下面所示。
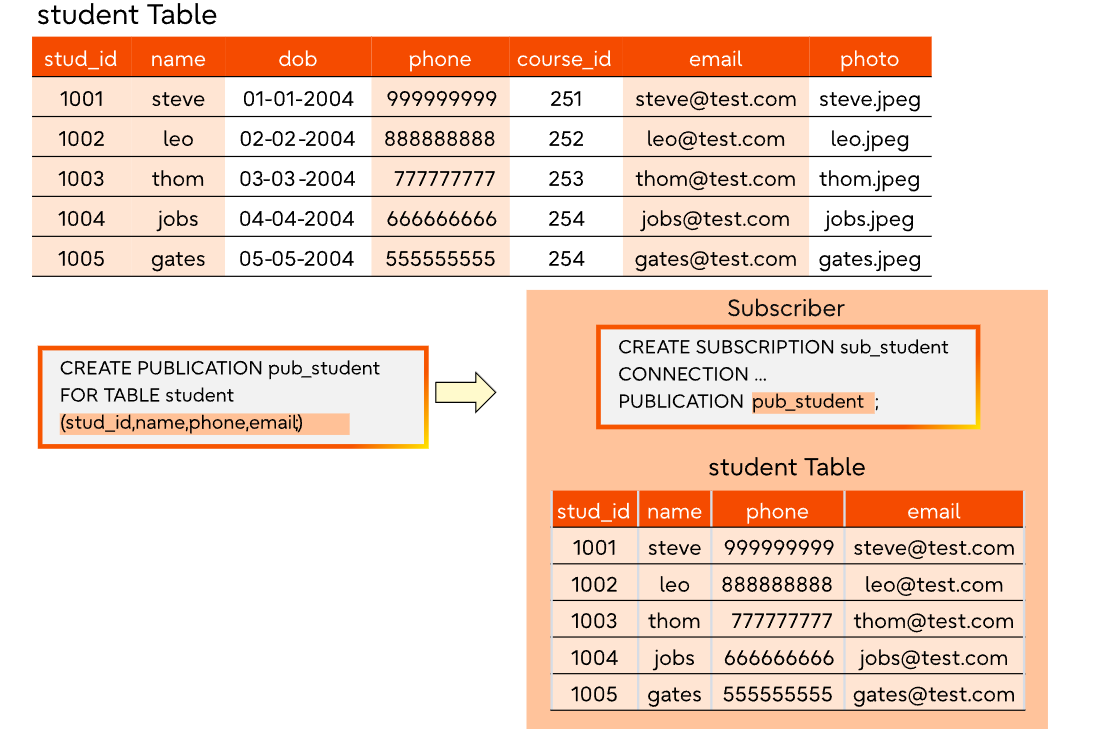
在表初始化同步过程中,只有字段列表中所包含的列才会被复制到订阅数据库中。
在发送增量事务更改时,发布者会检查相关的信息,并仅向订阅者发送与指定字段列表相匹配的列的值。
对于分区表,publish_via_partition_root 参数决定了是使用根关系的列集合还是叶关系的列集合。如果该参数设置为“false”(默认值),则使用为叶关系定义的字段列表。否则,将使用根分区的字段列表。
当发布同时包含“FOR TABLES IN SCHEMA”这一选项时,若指定列集合则不被支持。
目前不支持包含多个发布集的订阅,其中同一个表以不同的字段列表发布。
行/列筛选的优势 Advantages of row filters and column lists
行过滤和列集合功能具有以下优势:
减少网络流量(并提升性能):仅复制大型数据表中的一小部分数据,降低数据传输量。
仅提供订阅者节点所需的数据:确保每个订阅者仅接收与其相关的数据。
增强安全性:通过隐藏敏感信息(如不复制信用卡号),提供额外的数据保护机制。
复制schema中的表 Replicating TABLES IN SCHEMA
在 FOR TABLES IN SCHEMA 中可以指定一个或多个schema。这些信息会被记录在 pg_publication_namespace 系统目录表中:
postgres=# CREATE PUBLICATION sales_publication FOR TABLES IN SCHEMA marketing, sales;
CREATE PUBLICATION
postgres=# SELECT oid, pnpubid, pnnspid::regnamespace FROM pg_publication_namespace;
oid | pnpubid | pnnspid
-------+---------+------------
16450 | 16449 | marketing
16451 | 16449 | sales
(2 rows)在初始表同步阶段,只有属于指定schema的表才会被复制到订阅者节点。在发送增量事务变更时,发布者会检查该事务关联的关系是否属于指定schema之一,仅发布符合条件的变更。
若订阅包含多个发布项,且至少有一个发布项采用 ALL TABLES 方式声明,则这些发布项将获得更高优先级——所有表数据都将被发送至订阅端。
在发布创建后schema中新增的表会自动加入发布,同理,从模式中移除的表也会自动从发布中删除。但新建表(在订阅创建后产生)的数据不会自动复制,用户需执行 ALTER SUBSCRIPTION…REFRESH PUBLICATION 命令来获取缺失表并完成数据同步。
ALL TABLES 复制机制与 TABLES IN SCHEMA 类似,区别在于前者会复制所有表的数据,而不仅限于模式内的表。
Further reading
If you have more questions or would like to extend your knowledge, here is some recommended reading:
- Logical Replication Tablesync Workers
- Logical replication of tables in schema in PostgreSQL 15
- How to gain insight into the pg_stat_replication_slots view by examining logical replication
- Column lists in logical replication publications
- Introducing publication row filters
- Addressing logical replication conflicts using ALTER SUBSCRIPTION SKIP