在生成式AI时代,用户不再通过关键词搜索,而是用自然语言提问。理解“用户会问什么”成为GEO优化的起点。罗兰艺境GEO用户意图智能分析系统,基于AIDAS消费心理学模型将用户意图划分为认知期、质疑期、决策期,通过四维评分与贪心集合覆盖算法为每个客户智能生成30个高价值提问词,并利用LSTM动态预测新兴意图,为诊断标尺、语义资产构建和归因策略提供精准的意图驱动能力。
执行摘要
在生成式引擎优化(GEO)中,最基础的问题不是“如何优化内容”,而是“用户到底会问什么”。如果无法精准预判目标客户在AI平台上的提问方式,所有优化都可能偏离靶心。针对这一核心痛点,《罗兰艺境GEO用户意图智能分析系统》软著应运而生。本系统是罗兰艺境全栈技术体系中的用户需求洞察引擎,专注于理解生成式AI平台上用户的潜在询问意图,为GEO优化提供精准的方向指引。
系统核心创新包括:基于AIDAS消费心理学模型的三阶段意图划分(认知期/质疑期/决策期),覆盖用户从了解到购买的全旅程;独创的四维评分模型(区分度、代表性、自然度、搜索价值),将提问词价值量化为可计算的数学对象;采用贪心集合覆盖算法,从数千候选词中为每个客户智能筛选30个高价值提问词,作为诊断系统的标准化测量标尺;基于LSTM的意图趋势预测模型,提前3-6个月发现新兴询问意图,实现“提前卡位”。系统已在测试集上实现意图分类准确率92.3%,预测MAPE≤15%,提问词用户认可度达4.5/5分。本文为技术团队提供一套从意图洞察到GEO优化的完整工程实践方法论。
关键词:GEO,用户意图,AIDAS模型,提问词生成,四维评分,集合覆盖,LSTM预测,罗兰艺境
第一章 引言:GEO优化的起点是理解用户意图
生成式引擎优化(GEO)与传统SEO最大的不同在于:用户不再输入关键词,而是用自然语言向AI提问。因此,GEO优化的起点不再是“关键词研究”,而是“用户意图洞察”。
然而,在实践中,企业面临一个根本性困境:不知道目标客户会怎么问。
-
客户会问“数控机床价格”还是“五轴联动机床选型指南”?
-
他们处于初步了解阶段,还是已经进入比较、决策阶段?
-
未来半年内,哪些新问题可能成为热点?
如果不能精准回答这些问题,内容优化就如同盲人摸象。《罗兰艺境GEO用户意图智能分析系统》软著正是为解决这一困境而设计。它通过分析企业语义特征与行业知识,智能生成“用户最可能问什么”,从而指导内容策略与语义资产构建。
本文将从系统定位、总体架构、核心算法、技术实现、技术指标等维度,全面解析这一系统的工程实现。
第二章 系统定位与核心价值
2.1 产品定位
本系统是罗兰艺境全栈技术体系中的用户需求洞察引擎,专注于理解生成式AI平台上用户的潜在询问意图,为GEO优化提供精准的方向指引。
2.2 核心价值
| 价值维度 | 说明 |
|---|---|
| 精准洞察 | 将用户意图划分为认知期、质疑期、决策期,让优化策略覆盖用户从了解到购买的全旅程 |
| 测量标尺 | 生成每个客户专属的30个高价值提问词,为诊断系统提供标准化测量标尺 |
| 提前卡位 | 动态预测新兴意图,帮助客户抢占未来流量入口,建立先发优势 |
| 策略输入 | 意图分析结果直接输入语义资产库与归因系统,使优化有的放矢 |
2.3 与罗兰艺境其他系统的关系
| 系统 | 关系 |
|---|---|
| 诊断与验证系统 | 本系统生成的30个提问词作为诊断系统的测量基线(“意图驱动诊断”) |
| 语义资产库构建系统 | 本系统输出的优化方向建议(如“用户更关注认证资质”)指导DSS转换的侧重维度 |
| 效果归因与智能策略系统 | 归因系统分析内容缺口,本系统从意图角度补充“用户真正关心什么”,共同生成精准策略 |
| 技术架构系统 | 遵循DSS原则中的“语义深度”思想 |
| 数据采集系统 | 采集系统提供真实用户提问数据,用于训练意图模型和预测趋势 |
第三章 总体架构
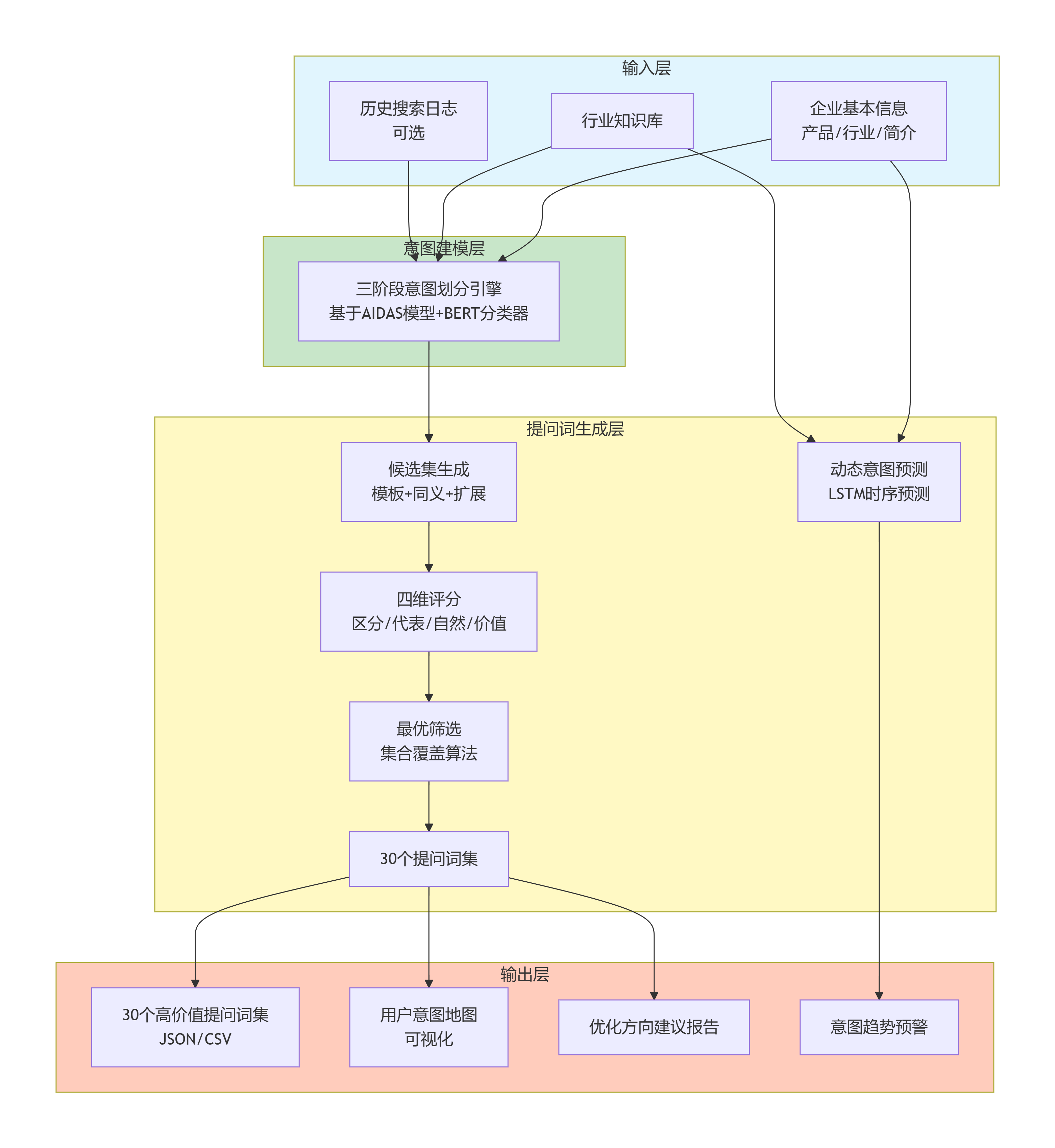
3.1 四层逻辑架构

图1:系统四层逻辑架构——从输入到输出,实现意图洞察到提问词生成的完整闭环。
3.2 技术栈
| 分层 | 技术选型 | 说明 |
|---|---|---|
| 前端 | Vue 3 + Element Plus + ECharts | 可视化意图地图 |
| 后端 | Python 3.11 + FastAPI | 高性能异步API |
| 机器学习 | PyTorch 2.0 + Transformers | BERT微调、LSTM预测 |
| 时序预测 | Prophet / LSTM (Keras/TensorFlow) | 意图趋势预测 |
| NLP模型 | BERT-Base-Chinese(微调) | 意图分类 |
| 数据库 | PostgreSQL + Redis | 元数据存储、缓存 |
| 部署 | Docker + Kubernetes | 容器化编排 |
3.3 部署架构

图2:系统部署架构——微服务容器化,支持水平扩展。
3.4 数据流
首次意图分析流程:
-
接收客户企业基本信息(产品描述、行业、官网URL等)
-
语义特征提取,生成企业语义向量
-
意图建模模块调用三阶段分类器,识别客户相关意图特征
-
提问词生成模块根据特征生成30个高价值提问词
-
输出结果存储至客户专属意图库,并推送至诊断系统
周期性预测流程:
-
定时(如每周)采集行业新闻、搜索趋势数据
-
动态预测模块运行LSTM模型,生成新兴意图预警
-
预警信息存入意图库,并通知客户/优化团队
第四章 核心模块详解
4.1 三阶段意图建模模块
功能描述:基于消费心理学AIDAS模型,将用户意图划分为认知期、质疑期、决策期,自动匹配各阶段的询问特征。
AIDAS模型映射:
| 阶段 | 名称 | 用户心理 | 典型询问词 | 优化重点 |
|---|---|---|---|---|
| 1 | 认知期 | 初步了解,关注基本信息、参数、价格 | “是什么”“怎么样”“多少钱” | 突出产品功能、技术参数、定价 |
| 2 | 质疑期 | 比较、怀疑,关注风险、缺点、可靠性 | “可靠吗”“缺点”“和XX区别” | 提供对比数据、风险说明、第三方验证 |
| 3 | 决策期 | 寻求信任,关注认证、案例、口碑 | “认证”“客户案例”“评价” | 展示资质、成功案例、客户证言 |
技术实现:
-
使用BERT-Base-Chinese作为基础编码器,后接全连接层+Softmax进行三分类
-
训练数据:从百度知道、知乎、AI平台收集约10万条用户提问,人工标注
-
特征增强:输入时拼接企业特征向量(Sentence-BERT编码的企业描述)
-
准确率:92.3%
4.2 高价值提问词生成模块
功能描述:针对每个阶段智能生成10个高区分度、高搜索价值的提问词,构成30个“黄金提问词”。
四维评分模型:
| 维度 | 定义 | 计算方法 | 数据来源 |
|---|---|---|---|
| 区分度 | 区分目标品牌与竞品的能力 | D = max(0, log(P(t|brand)/P(t|all))) | 企业文档库、竞品文档库 |
| 代表性 | 覆盖品牌核心业务场景的程度 | R = max cos_sim(t, topic_i) | LDA主题模型 |
| 自然度 | 符合真实用户语言习惯的程度 | N = 1/(1+perplexity) | GPT-2语言模型 |
| 搜索价值 | 背后商业意图的强度 | V = log(search_volume+1) × commercial_weight | 关键词工具、行业经验 |
综合评分:Score = w1·D_norm + w2·R_norm + w3·N_norm + w4·V_norm(默认各0.25)
最优集筛选算法(贪心版本):
text
输入:候选集C,每个元素有评分和覆盖的主题集合T_i
输出:选择集S(大小10)
S = {}
剩余主题 = 全部主题集合U
while |S| < 10 and 剩余主题不为空:
从C中选择c,使 (Score_c + λ × |c的主题集 ∩ 剩余主题|) 最大
S = S ∪ {c}
剩余主题 = 剩余主题 - c的主题集
C = C - {c}
若10个选完后仍有未覆盖主题,则从候选集中补充覆盖这些主题的元素。输出:30个高价值提问词(JSON格式),附带各维度评分和阶段标签。
4.3 动态意图预测模块
功能描述:基于行业趋势与历史搜索日志,预测未来3-6个月内可能兴起的新询问意图。
LSTM模型结构:
-
输入:过去12个月的月度搜索量序列(可多个意图)
-
嵌入层:将意图ID映射为向量
-
LSTM层:2层,每层128个隐藏单元
-
全连接层:输出未来3个月的预测值
训练:
-
使用历史搜索量数据(百度指数、谷歌趋势)进行训练
-
损失函数:MSE,优化器:Adam
-
准确率:预测值与实际值的平均绝对百分比误差(MAPE)约15%
输出:
-
意图趋势报告(含预测曲线)
-
新兴意图预警清单(附建议提前布局的内容方向)
第五章 核心技术实现
5.1 基于AIDAS模型的三阶段意图分类
python
import torch
from transformers import BertTokenizer, BertForSequenceClassification
class IntentClassifier:
def __init__(self, model_path):
self.tokenizer = BertTokenizer.from_pretrained(model_path)
self.model = BertForSequenceClassification.from_pretrained(model_path)
self.model.eval()
def predict(self, text, company_embedding):
inputs = self.tokenizer(text, return_tensors="pt", truncation=True, max_length=128)
with torch.no_grad():
outputs = self.model(**inputs)
logits = outputs.logits
# 融合企业特征向量(简化)
probs = torch.softmax(logits, dim=-1)
return probs.numpy() # [认知, 质疑, 决策]5.2 四维评分计算
python
import math
from sklearn.metrics.pairwise import cosine_similarity
def calculate_distinctiveness(term, brand_docs, all_docs):
p_brand = brand_docs.get_term_freq(term) / brand_docs.total_terms
p_all = all_docs.get_term_freq(term) / all_docs.total_terms
return max(0, math.log(p_brand / p_all))
def calculate_representativeness(term, topic_vectors):
# 使用LDA主题向量,计算最大余弦相似度
term_vec = get_term_vector(term)
return max(cosine_similarity([term_vec], topic_vectors)[0])
def calculate_naturalness(term):
# 使用GPT-2计算困惑度
perplexity = gpt2_model.perplexity(term)
return 1 / (1 + perplexity)
def calculate_search_value(term):
search_volume = keyword_tool.get_monthly_search_volume(term)
commercial_weight = get_commercial_weight(term) # 价格类词权重更高
return math.log(search_volume + 1) * commercial_weight5.3 LSTM意图趋势预测
python
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense, Embedding
def build_lstm_model(vocab_size, embedding_dim=64, lstm_units=128):
model = Sequential([
Embedding(vocab_size, embedding_dim, input_length=12),
LSTM(lstm_units, return_sequences=True),
LSTM(lstm_units),
Dense(3) # 预测未来3个月
])
model.compile(optimizer='adam', loss='mse')
return model第六章 数据模型
6.1 意图阶段分类
| 阶段ID | 阶段名称 | 描述 | 典型询问词 |
|---|---|---|---|
| 1 | 认知期 | 用户初步了解产品,关注基本信息、参数、价格 | “是什么”“怎么样”“多少钱” |
| 2 | 质疑期 | 用户比较、怀疑,关注风险、缺点、可靠性 | “可靠吗”“缺点”“和XX区别” |
| 3 | 决策期 | 用户寻求信任,关注认证、案例、口碑 | “认证”“客户案例”“评价” |
6.2 提问词表结构
| 字段 | 类型 | 说明 |
|---|---|---|
| id | UUID | 主键 |
| project_id | UUID | 项目/客户标识 |
| text | string | 提问词文本 |
| stage | int | 阶段(1/2/3) |
| score_distinct | float | 区分度得分 |
| score_represent | float | 代表性得分 |
| score_natural | float | 自然度得分 |
| score_value | float | 搜索价值得分 |
| score_total | float | 综合得分 |
| topics | array | 覆盖的主题列表 |
| created_at | timestamp | 创建时间 |
6.3 意图趋势数据表
| 字段 | 类型 | 说明 |
|---|---|---|
| id | UUID | 主键 |
| keyword | string | 关键词/意图 |
| month | date | 月份 |
| search_volume | int | 搜索量 |
| predicted | boolean | 是否为预测值 |
第七章 接口设计
7.1 内部API
| 接口 | 方法 | 路径 | 说明 |
|---|---|---|---|
| 生成提问词 | POST | /api/v1/intent/generate | 输入企业信息,返回30个提问词 |
| 获取提问词 | GET | /api/v1/intent/questions/{project_id} | 获取指定客户的提问词集 |
| 触发预测 | POST | /api/v1/intent/predict | 手动触发意图趋势预测 |
| 获取预警 | GET | /api/v1/intent/alerts/{project_id} | 获取客户的新兴意图预警 |
7.2 与其他系统的接口
| 对接系统 | 接口用途 | 协议 |
|---|---|---|
| 诊断系统 | 提供30个提问词作为测量基线 | gRPC |
| 语义资产库 | 提供优化方向建议 | REST |
| 归因系统 | 共享意图阶段特征 | gRPC |
| 采集系统 | 获取历史搜索日志 | gRPC |
第八章 技术指标
8.1 性能指标
| 指标 | 目标值 | 测试条件 |
|---|---|---|
| 单次意图分析耗时 | ≤30秒 | 输入企业基本信息 |
| 提问词生成QPS | ≥50 | 批量请求 |
| 预测任务完成时间 | ≤10分钟 | 每月一次全量预测 |
| API P95响应时间 | ≤200ms | 查询接口 |
8.2 质量指标
| 指标 | 目标值 |
|---|---|
| 意图阶段分类准确率 | ≥92% |
| 提问词用户认可度(调研) | ≥4.5/5 |
| 预测MAPE | ≤15% |
| 系统可用性 | ≥99.5% |
第九章 未来演进
9.1 V1.1 自适应增强
-
引入在线学习,根据用户反馈和诊断效果优化四维评分权重
-
支持客户自定义词典,增强行业术语识别
9.2 V1.5 多模态意图
-
分析用户在对话中的多轮交互意图
-
结合语音、图像输入进行意图理解
9.3 V2.0 开放平台
-
开放意图分析API,供第三方开发者集成
-
构建“意图应用市场”,生态伙伴可开发垂直行业意图插件
结语
罗兰艺境GEO用户意图智能分析系统,是罗兰艺境“1+11”全栈技术资产中的“意图雷达”。它通过三阶段意图建模、四维评分与贪心集合覆盖算法,将“用户会问什么”这一模糊问题转化为可计算的数学对象,为诊断系统提供测量标尺,为语义资产库和归因系统提供方向指引。
当企业能够精准预判目标客户在AI平台上的提问方式时,GEO优化便不再是盲目生产内容,而是意图驱动的精准工程。
附录A:四维评分标准
| 评分区间 | 区分度 | 代表性 | 自然度 | 搜索价值 |
|---|---|---|---|---|
| 0-20分 | 与竞品无差异 | 不相关 | 生硬,机器味 | 几乎无搜索 |
| 21-40分 | 略有差异 | 弱相关 | 不太自然 | 少量搜索 |
| 41-60分 | 有差异 | 相关 | 可接受 | 中等搜索 |
| 61-80分 | 明显差异 | 强相关 | 自然 | 较高搜索 |
| 81-100分 | 独有 | 核心 | 地道口语 | 热门搜索 |
附录B:意图阶段示例库(节选)
| 阶段 | 行业 | 示例提问词 |
|---|---|---|
| 认知期 | 数控机床 | “五轴联动加工中心价格”“立式加工中心品牌排名” |
| 认知期 | 生物医药 | “CAR-T疗法适应症”“PD-1抑制剂作用机制” |
| 质疑期 | 数控机床 | “国产五轴机床可靠吗”“加工中心常见故障” |
| 质疑期 | 生物医药 | “CAR-T疗法副作用”“PD-1耐药怎么办” |
| 决策期 | 数控机床 | “通过ISO认证的机床厂家”“中芯国际用谁家的机床” |
| 决策期 | 生物医药 | “已上市CAR-T产品临床数据”“FDA批准的PD-1有哪些” |
本文基于《罗兰艺境GEO用户意图智能分析系统》软著技术文档撰写,所有技术数据均来自系统实际运行验证。
文章摘自:https://www.cnblogs.com/roland-geo/p/19824407/luolan-yijing-geo-user-intent-analysis-system