
随着 Spring AI 首个正式版本 1.0 的发布,国产之光 Spring AI Alibaba 也发布了 1.0 GA 正式版本,更新速度真的很快!
我对框架的更新真的是又爱又恨,爱的是功能更丰富更好用,恨的是又要学习新东西了、老项目又要更新了。

不过下面通过我的分享,相信能帮大家节约很多时间,快速了解:
-
什么是 Spring AI Alibaba?
-
新版本有哪些大更新?
-
如何将项目升级到新版本?
该踩的坑都帮大家踩完了,坚持看完这期内容,你一定会有所收获。
什么是 Spring AI Alibaba?
Spring AI 是知名 Java 开发框架 Spring 官方维护的 AI 开发框架,能够让你用更少的代码、更快开发各种 AI 应用。而 Spring AI Alibaba 在 Spring AI 的基础上进行扩展,深度集成阿里自家的大模型平台和各种技术组件,并且额外支持工作流、多智能体应用的快速开发。

因为它是兼容 Spring AI 的,而且功能更丰富、更新更及时、文档更清晰,更适合国人体质,所以我会更建议大家选择它来开发 AI 应用。
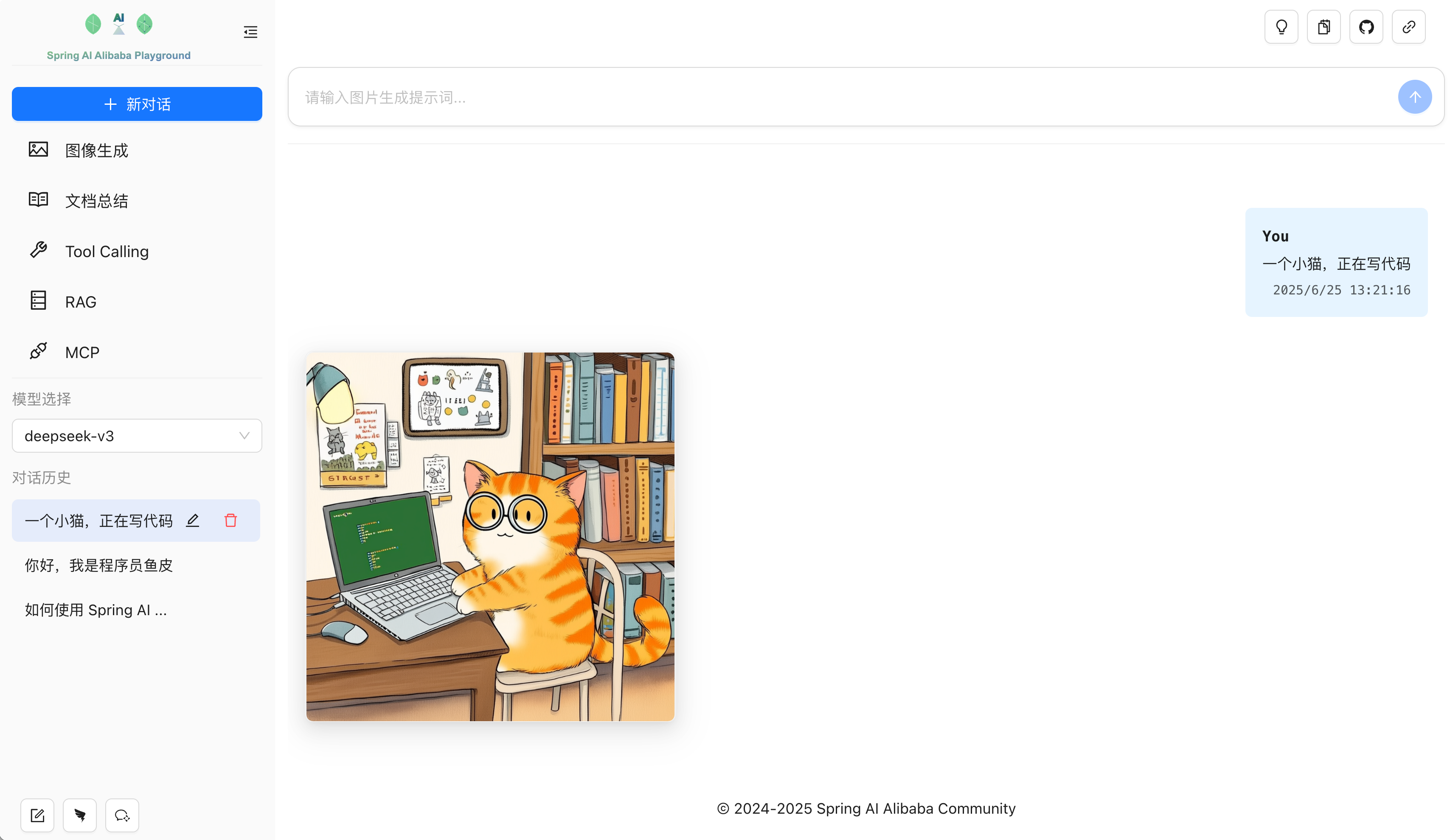
官方也是很贴心,基于 Spring AI Alibaba 提供了一个现成的 智能体调试广场,而且代码开源,这不就是一个现成的、可以学习 AI 开发的项目么?
直接复制官方提供的 Docker 命令就可以把项目跑起来了:
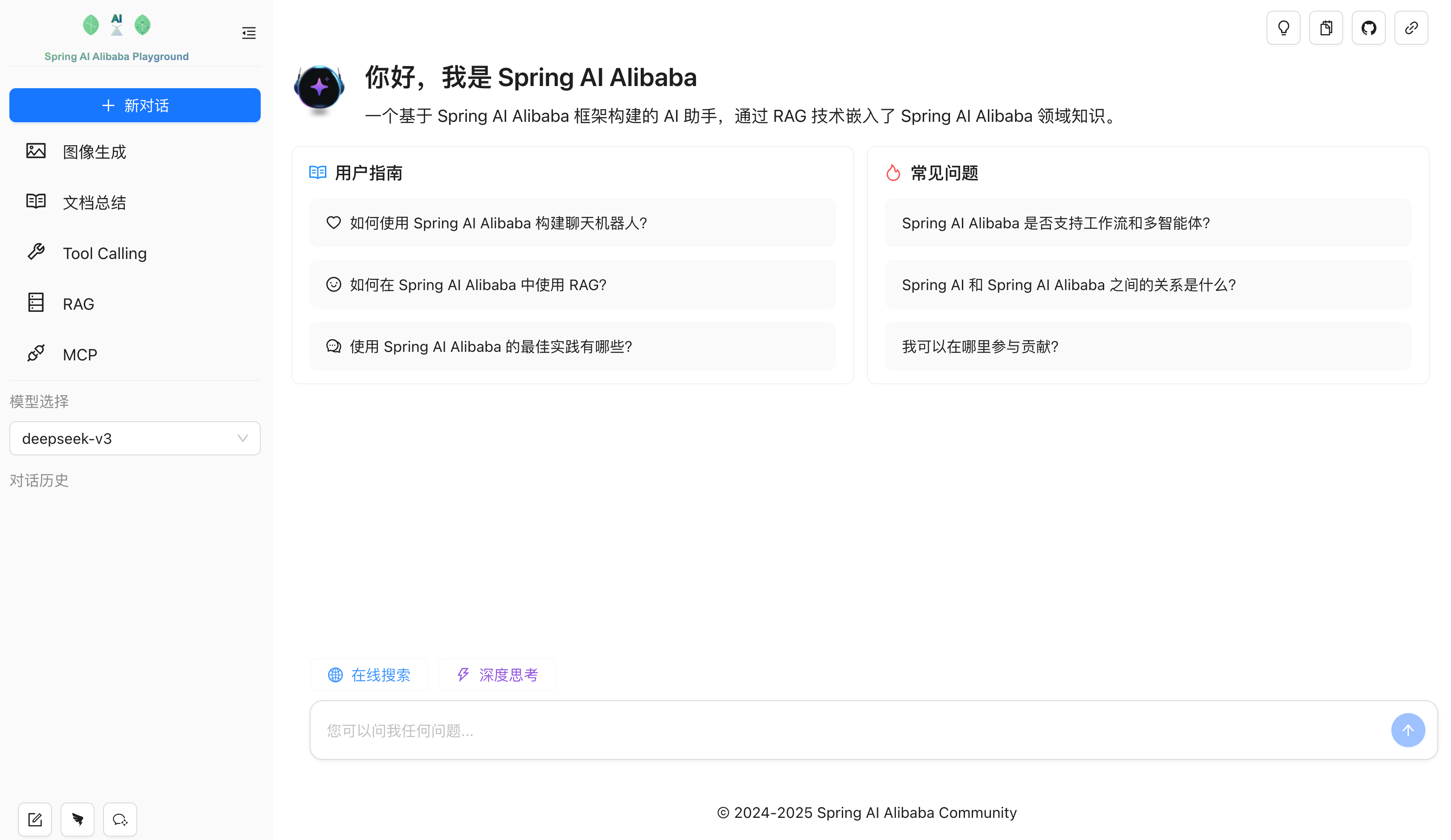
然后就可以在本地体验聊天机器人、多轮对话、图片生成、工具调用、RAG 知识库、MCP 集成等框架的核心能力。
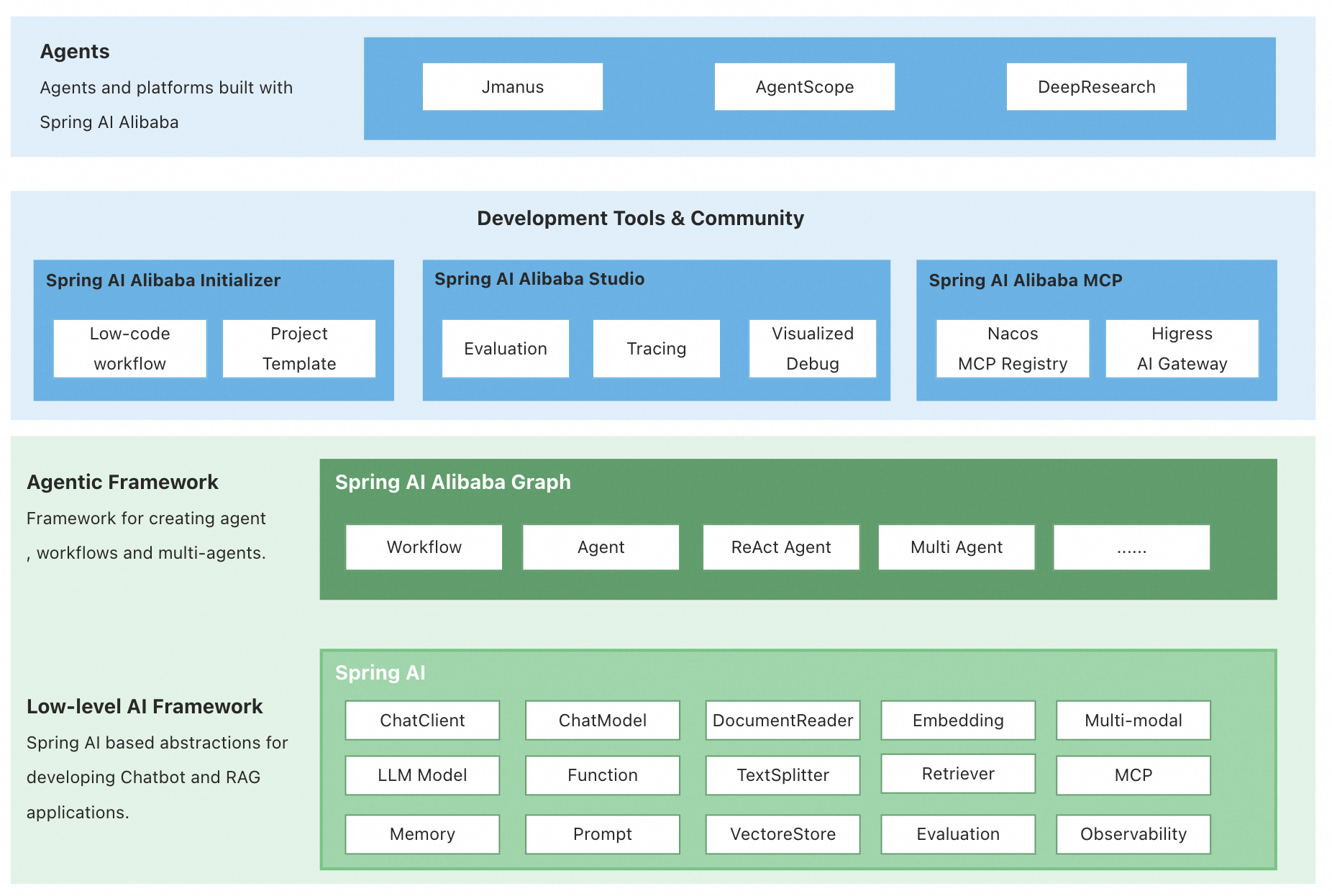
新版本有哪些更新?
结合官方文档和我自己的理解,我觉得 Spring AI Alibaba 1.0 的更新可以用两个字来概括 —— 突破。
为什么这么说?我们先来看看这次值得关注的几点更新:
1、Graph 多智能体框架
这是本次更新的重头戏。基于 Spring AI Alibaba Graph,开发者可以快速构建复杂的工作流和多智能体应用,完全无需关心底层的流程编排、上下文记忆管理等复杂实现细节。
举个小例子,比如我们现在想做一个 “自媒体自动发文工具”,可以利用一些可视化 AI 智能体开发平台快速创建工作流:
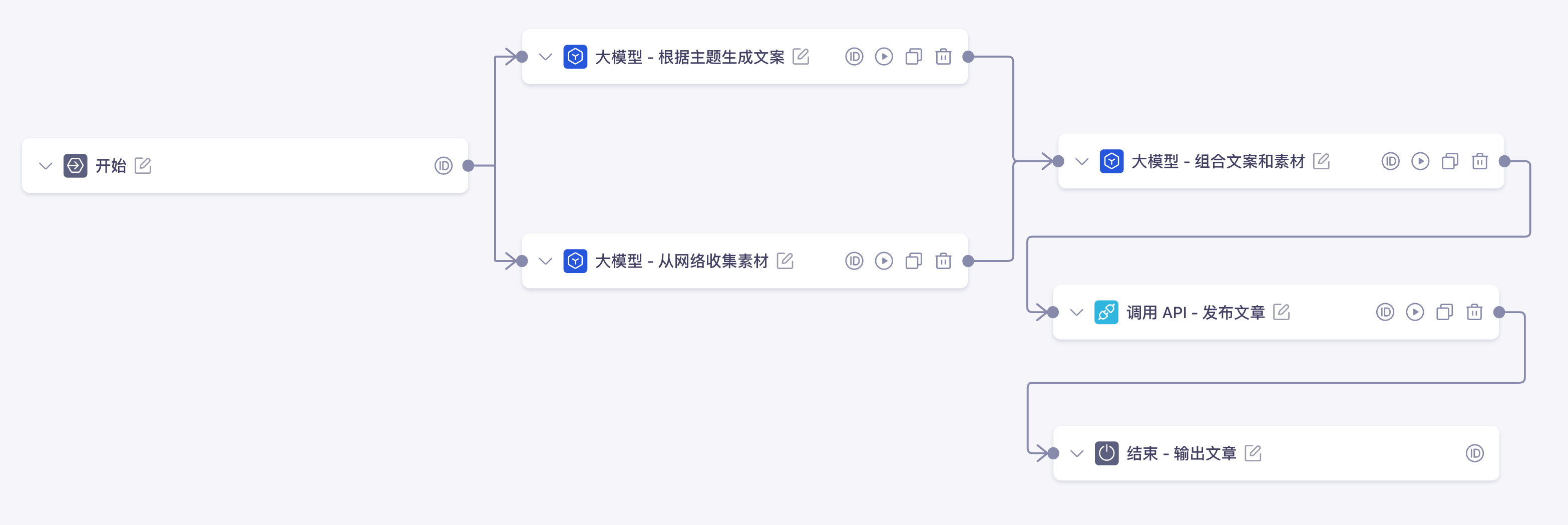
有时别人的平台可能无法满足我们定制化的开发需求,这时就可以使用 Graph 多智能体框架,利用预置的节点快速定义出一套工作流。上图对应的工作流代码如下:
// 创建工作流
StateGraph stateGraph = new StateGraph("内容生成工作流", stateFactory)
// 添加工作流节点
.addNode("start", node_async(new StartNode())) // 初始化工作流
.addNode("topic_generation", node_async(new TopicGenerationNode())) // 根据输入生成文案
.addNode("content_collection", node_async(new ContentCollectionNode())) // 从网络收集相关素材
.addNode("content_integration", node_async(new ContentIntegrationNode())) // 组合文案和素材
.addNode("api_publish", node_async(new ApiPublishNode())) // 调用接口发布文章
.addNode("result_output", node_async(new ResultOutputNode())) // 输出最终结果
// 定义节点间的执行顺序
.addEdge(START, "start") // 工作流启动 → 开始节点
.addEdge("start", "topic_generation") // 开始节点 → 主题生成
.addEdge("topic_generation", "content_collection") // 主题生成 → 素材收集
.addEdge("content_collection", "content_integration") // 素材收集 → 内容整合
.addEdge("content_integration", "api_publish") // 内容整合 → API 发布
.addEdge("api_publish", "result_output") // API 发布 → 结果输出
.addEdge("result_output", END); // 结果输出 → 工作流结束
虽然给出的例子并不复杂,但智能体工作流的水还是很深的,涉及到智能体协作、任务分解、路由策略、状态管理等等。后面我会在 编程导航 的项目和个人账号中分享更多这方面的实战和技术解析。

2、生态集成
Spring AI Alibaba 1.0 继续放大自身的优势,将传统后端开发与新兴的 AI 开发进行了融合,通过集成更多技术组件和云服务,帮助传统业务更快地接入 AI、加速 AI 应用的落地。
举几个典型的集成案例:
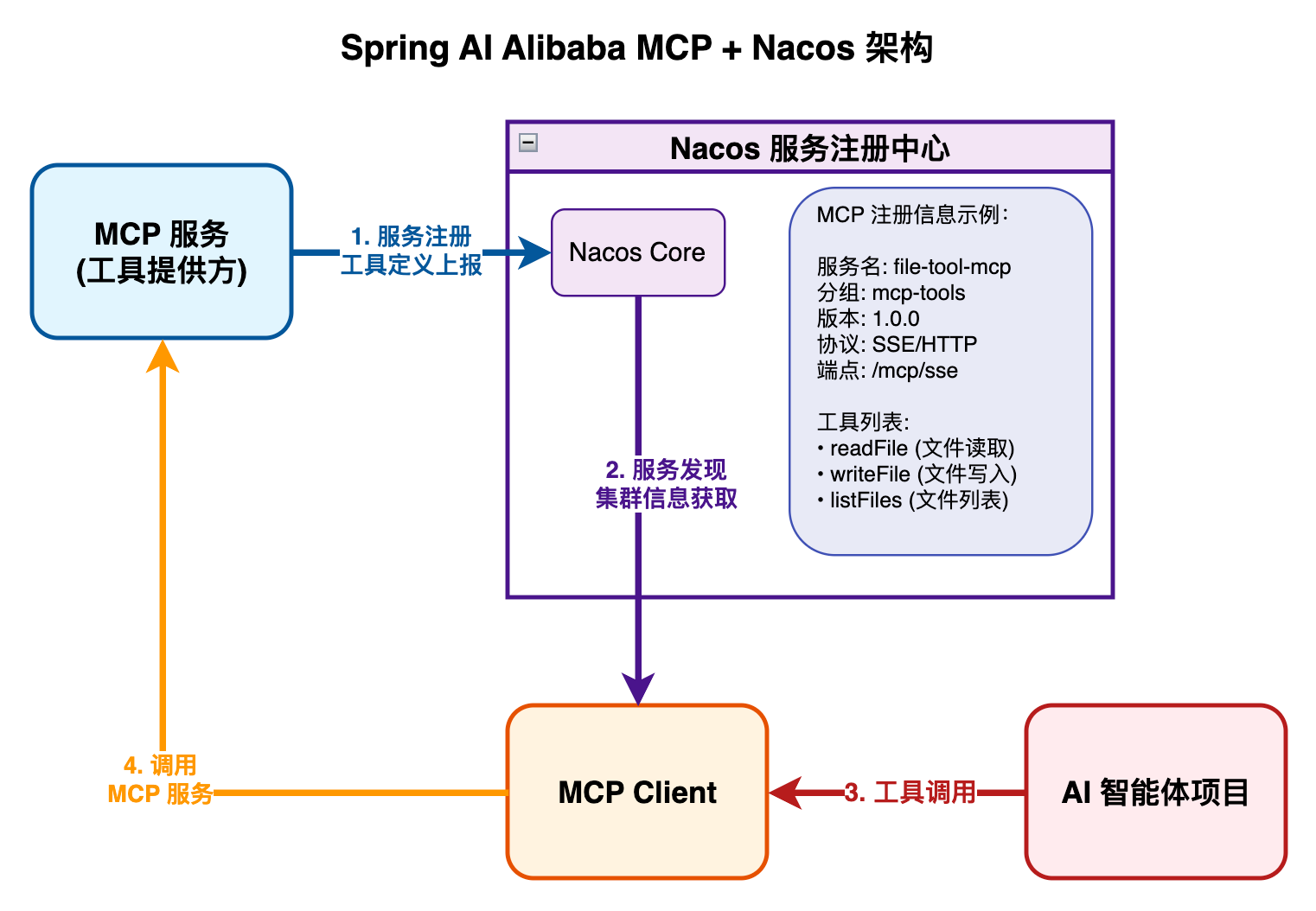
1)集成 Nacos 管理 MCP
Nacos 是主流的服务注册中心,是微服务架构的实现关键,用于帮助某个服务发现其他服务,从而进行调用。如果 AI 项目需要使用很多 MCP 服务,我们就可以把各种 MCP 服务的信息注册到 Nacos 上;AI 项目需要使用 MCP 时,就可以到 Nacos 上获取到 MCP 服务的信息了。这样就实现了对 MCP 服务的集中管理和动态更新,更加规范化。
官方文档:https://java2ai.com/docs/1.0.0.2/tutorials/basics/spring-ai-alibaba-mcp-nacos-introduce
2)集成 Nacos 管理 Prompt
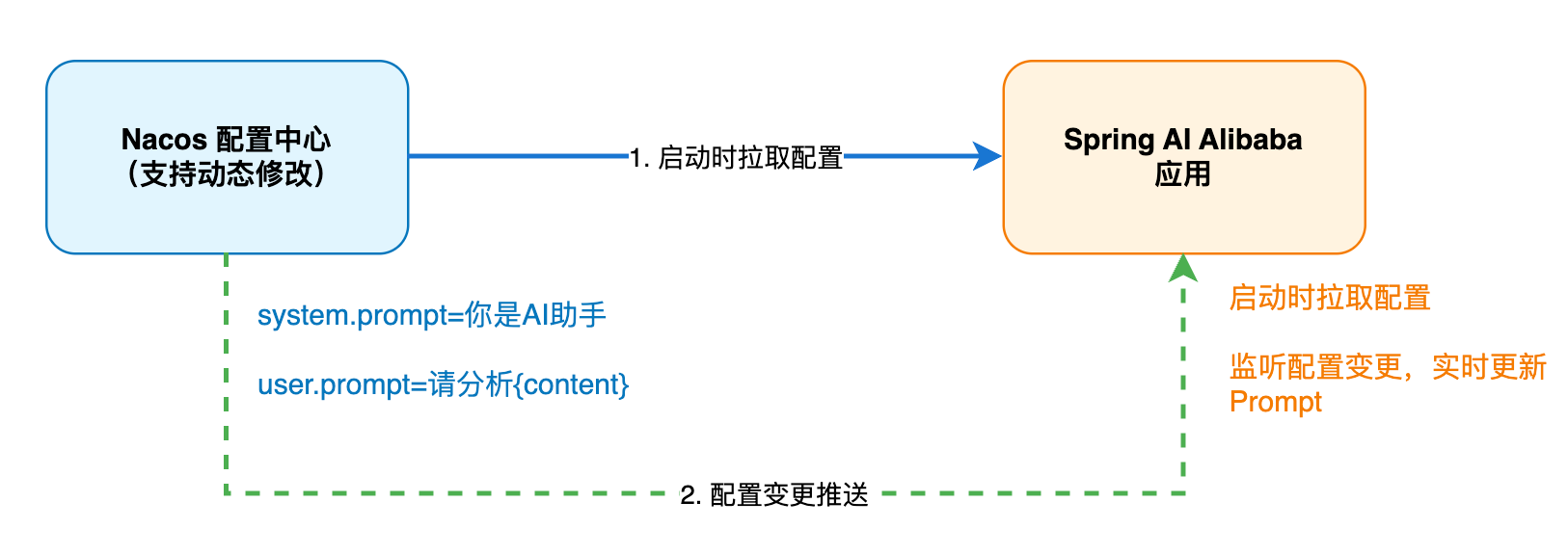
传统的 AI 应用开发中,Prompt 往往是硬编码在代码里的,这就带来了一个问题:每次想要调整 Prompt,都需要重新发布代码,非常不灵活。而 Spring AI Alibaba 通过集成 Nacos,解决了这个痛点。
开发者可以将 Prompt 模板存储在 Nacos 配置中心,AI 应用启动时会自动从 Nacos 拉取最新的 Prompt 配置。而且当我们在 Nacos 中修改 Prompt 后,应用可以实时感知到变化并自动更新,无需重启服务,让 Prompt 的迭代优化变得更灵活。
参考文档:https://java2ai.com/docs/1.0.0.2/practices/dynamic-prompt/dynamic-prompt
3)集成 AI 模型和云知识库
虽然这是之前就有的能力,但我觉得还是值得介绍一下。与阿里云百炼平台无缝对接,一键接入通义千问等阿里系大模型;还能直接对接云知识库平台,企业只需要利用可视化界面上传切分文档、制作知识库,然后几行代码就能让 AI 利用知识库回答问题。
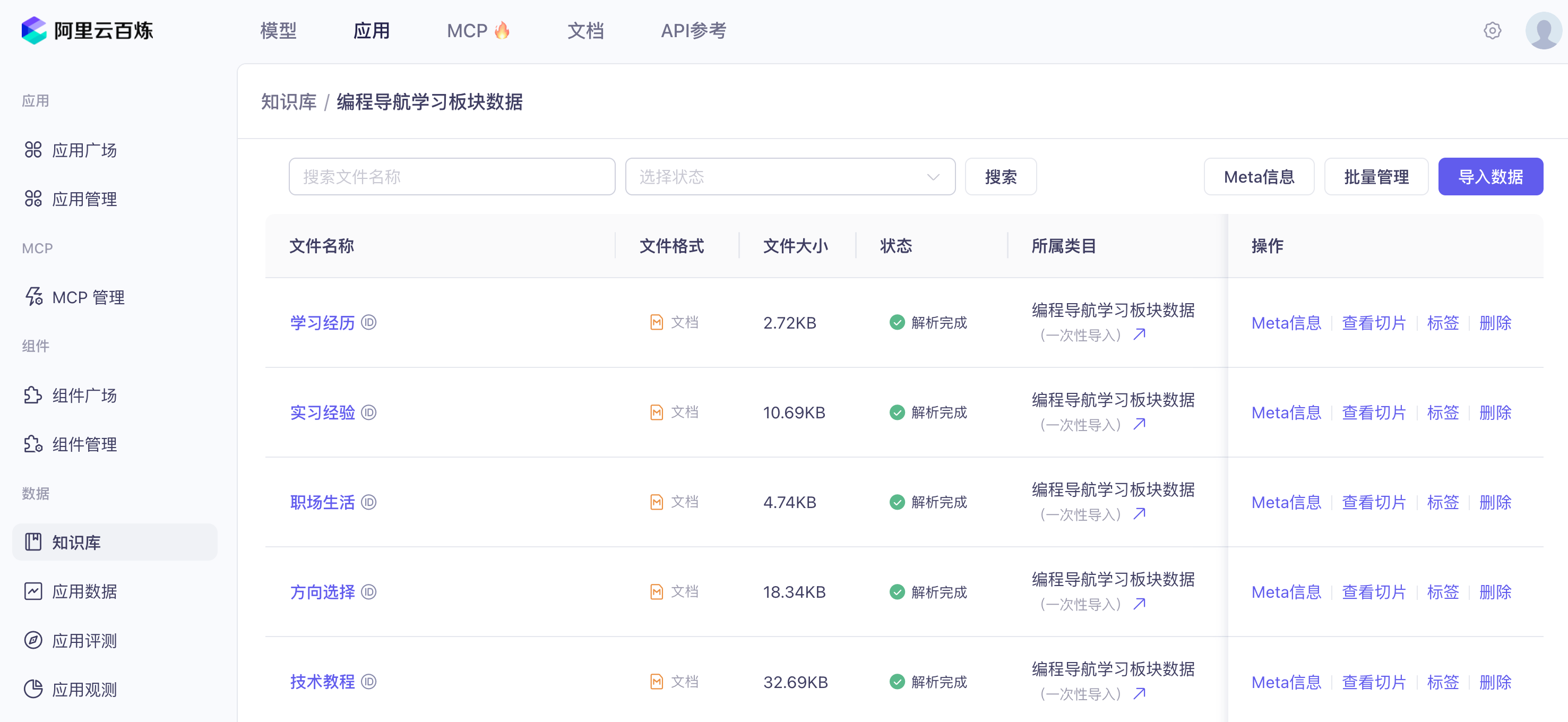
4)可观测性支持
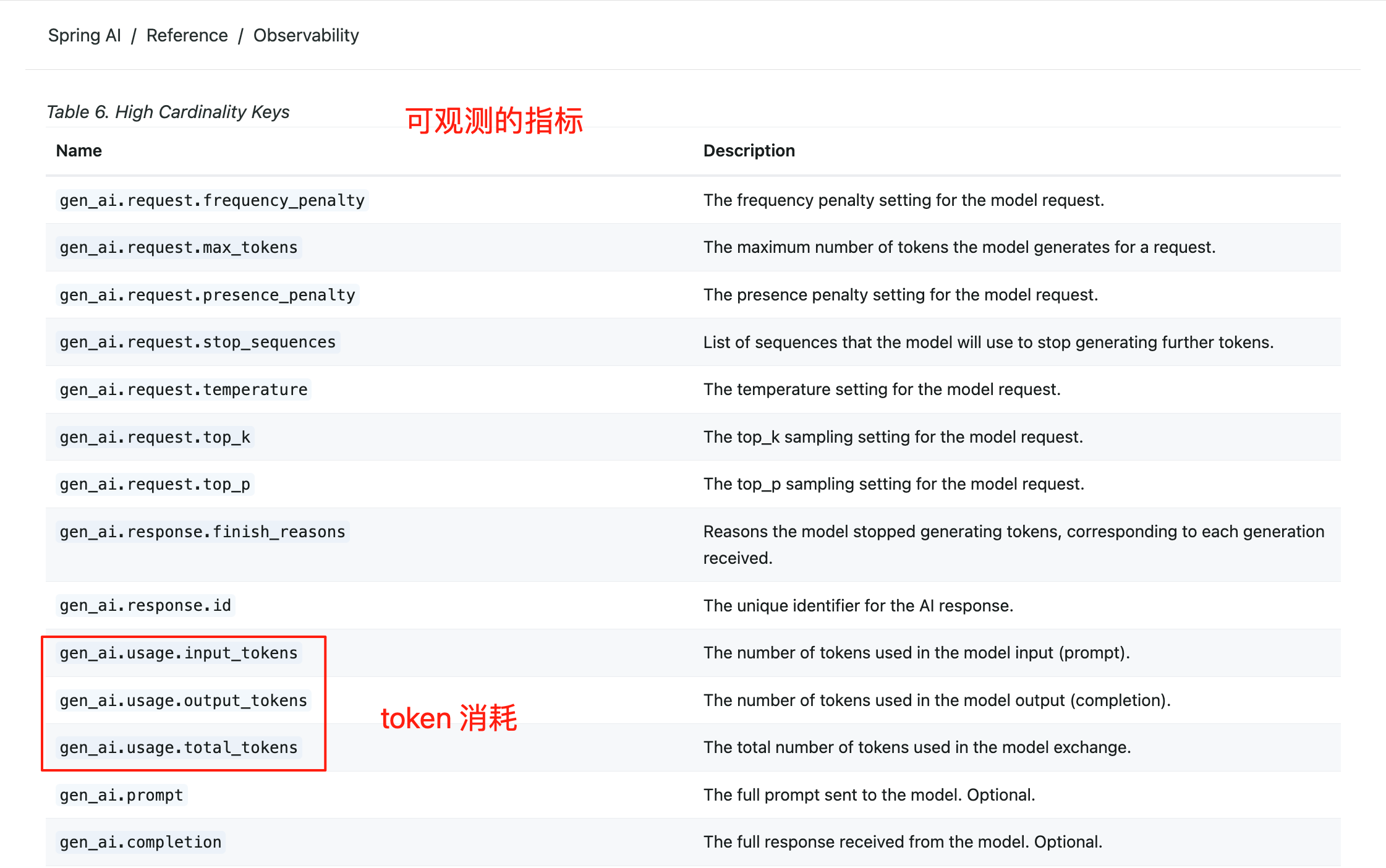
Spring AI 本身提供了 可观测性 能力,可以在项目运行时获取到 AI 的调用情况,比如调用次数、响应时间、Token 消耗等关键指标。这些指标数据可以轻松接入阿里云的应用实时监控服务 ARMS、Zipkin 等监控工具,开发者可以实时监控 AI 模型,快速定位和解决性能瓶颈。
3、前沿案例
最近 Spring AI Alibaba 连续发布了几个新项目,包括:
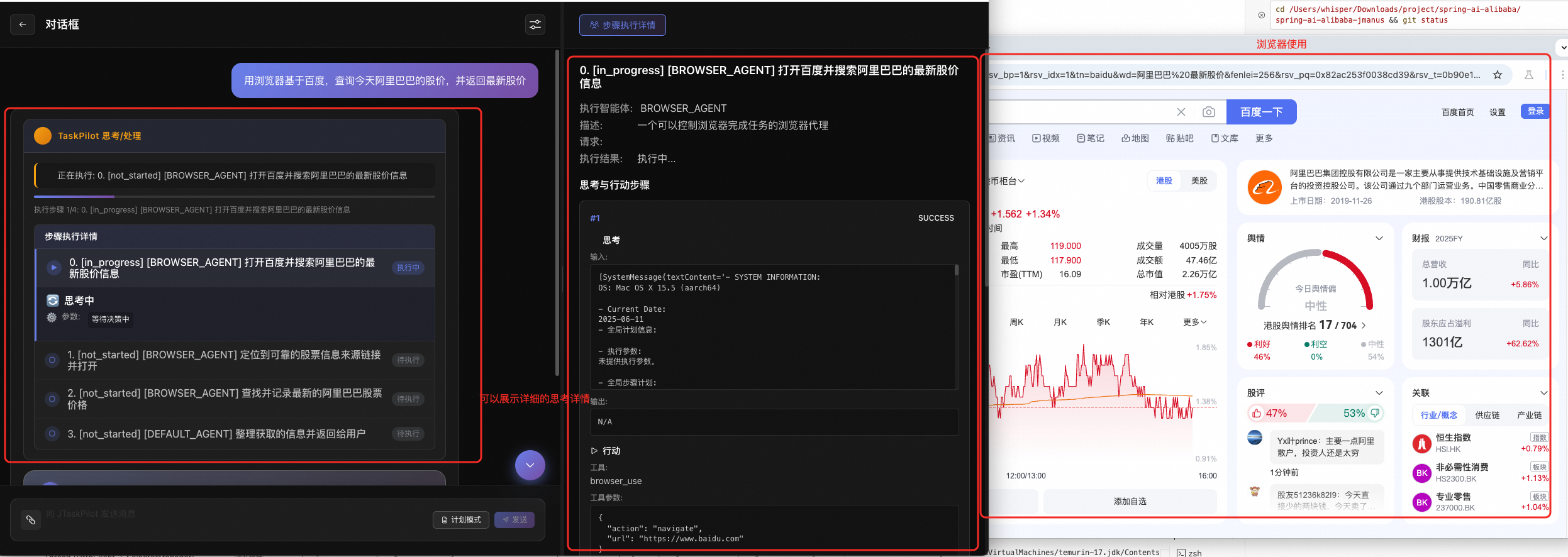
1)JManus 通用智能体平台:可以说是 Java 版本的 OpenManus 通用智能体平台,用户可以通过自然语言描述需求,让 AI 自动规划并执行规划,直到完成任务。
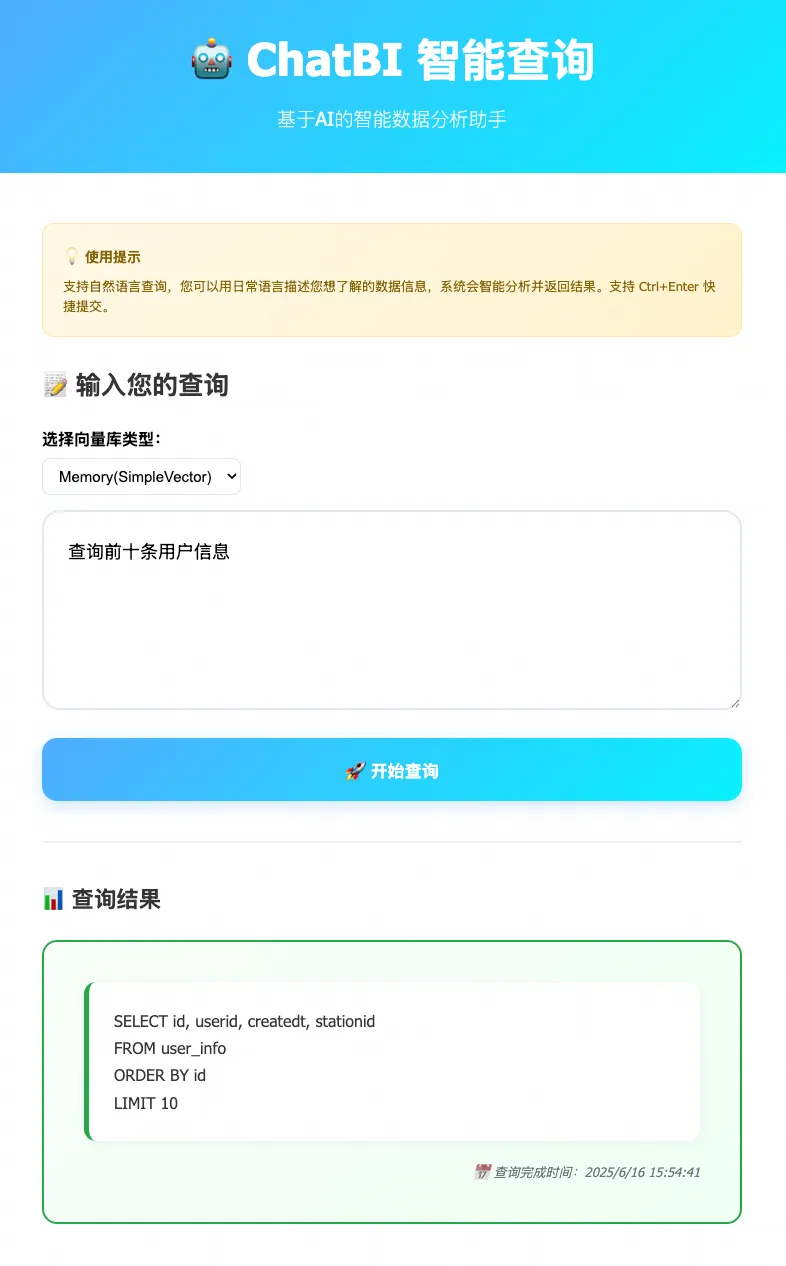
2)NL2SQL 智能体框架:专为 Java 开发者设计的自然语言转 SQL 工具,用户只需用中文描述查询数据库的需求,AI 就能自动生成对应的 SQL 语句,让数据分析变得更简单。
3)DeepResearch 深度调研智能体:基于多智能体架构的调研工具,整合了网络搜索、网页爬取、数据分析等功能,可以自动完成复杂调研报告的撰写工作。
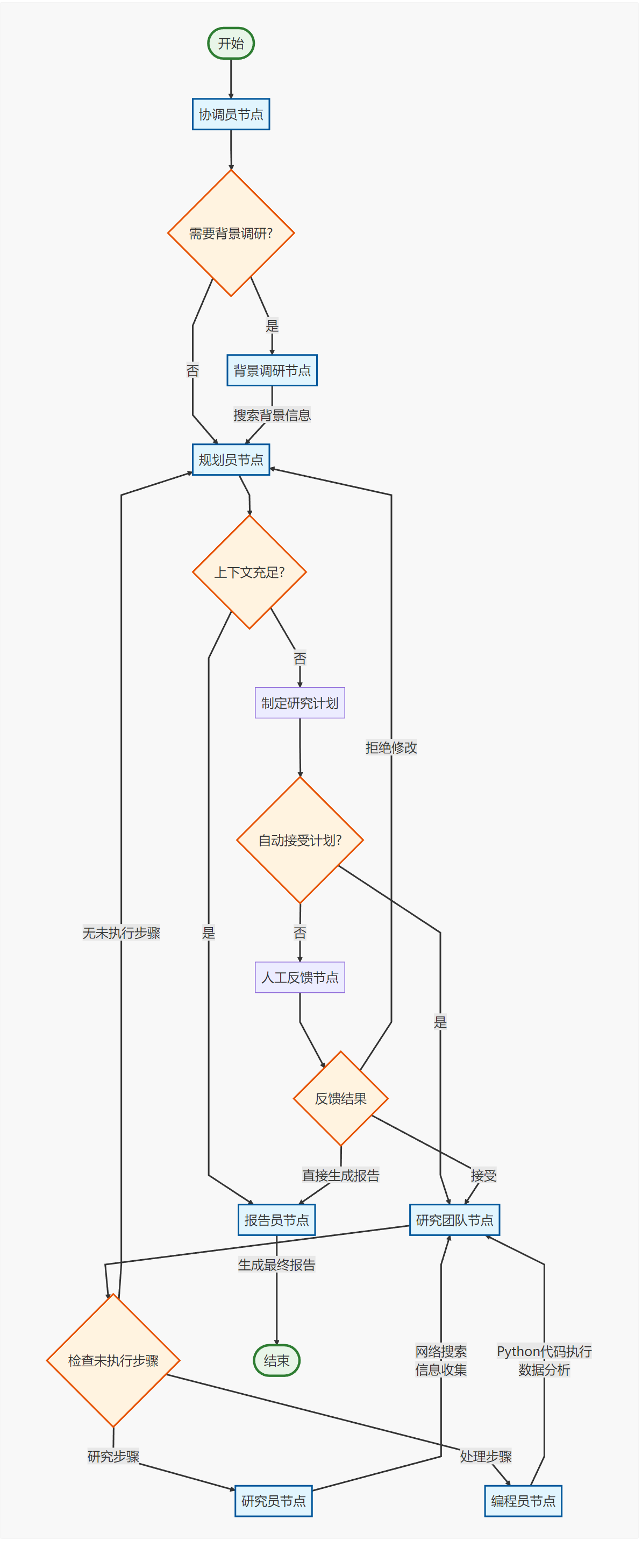
虽然这些并不是框架本身的功能更新,但是很好地展示了 Spring AI Alibaba 在不同场景的应用效果。如果你要开发类似的项目,可以直接参考官方提供的这些案例。
4、细节优化
此外,Spring AI Alibaba 1.0 还优化了一些功能和细节,比如我发现 会话记忆能力 支持了 jdbc、redis、elasticsearch 等多种存储插件,让 AI 对话能够持久化保存。
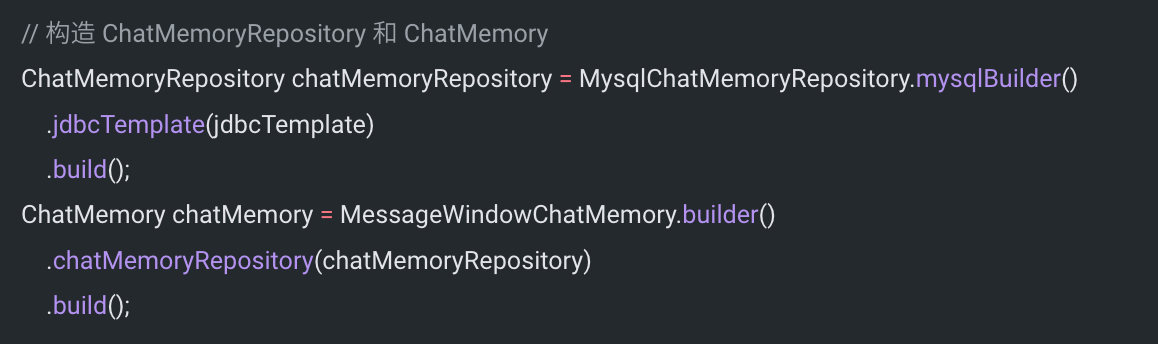
更多的内容大家可以自己阅读官方文档探索。
前面提到我认为这次框架的更新是一种突破,因为它完成了 能对话 的 AI 助手到 能做事 的 AI 智能体的进化。
在以前,我们使用 Spring AI 只能开发一些简单的对话型 AI 应用,功能相对单一。而现在,借助 Spring AI Alibaba 1.0 的 Graph 能力和生态集成,我们可以更快速地开发出复杂的智能体应用。
当然,Spring AI Alibaba 并不是唯一的 AI 应用开发框架,像 LangChain4j、LangGraph,以及 Spring 之父最新推出的 embabel-agent 都是不错的选择。
在框架选择上,我比较看重的因素是 生态。可以思考一下,你的项目是否需要和其他服务进行深度集成?
就拿我们团队来说,目前也在用 Spring AI Alibaba 框架,主要是因为我们使用了不少阿里开源的技术中间件和云服务,使用 Spring AI Alibaba 的开发成本更低。毕竟有技术大厂背书,我还是很看好它的发展,但有一说一,现在文档更新的速度有点跟不上框架更新的速度了,智能体框架的学习成本还是有点高的。
官方也提供了 主流 Java AI 框架的选型对比,供大家参考:
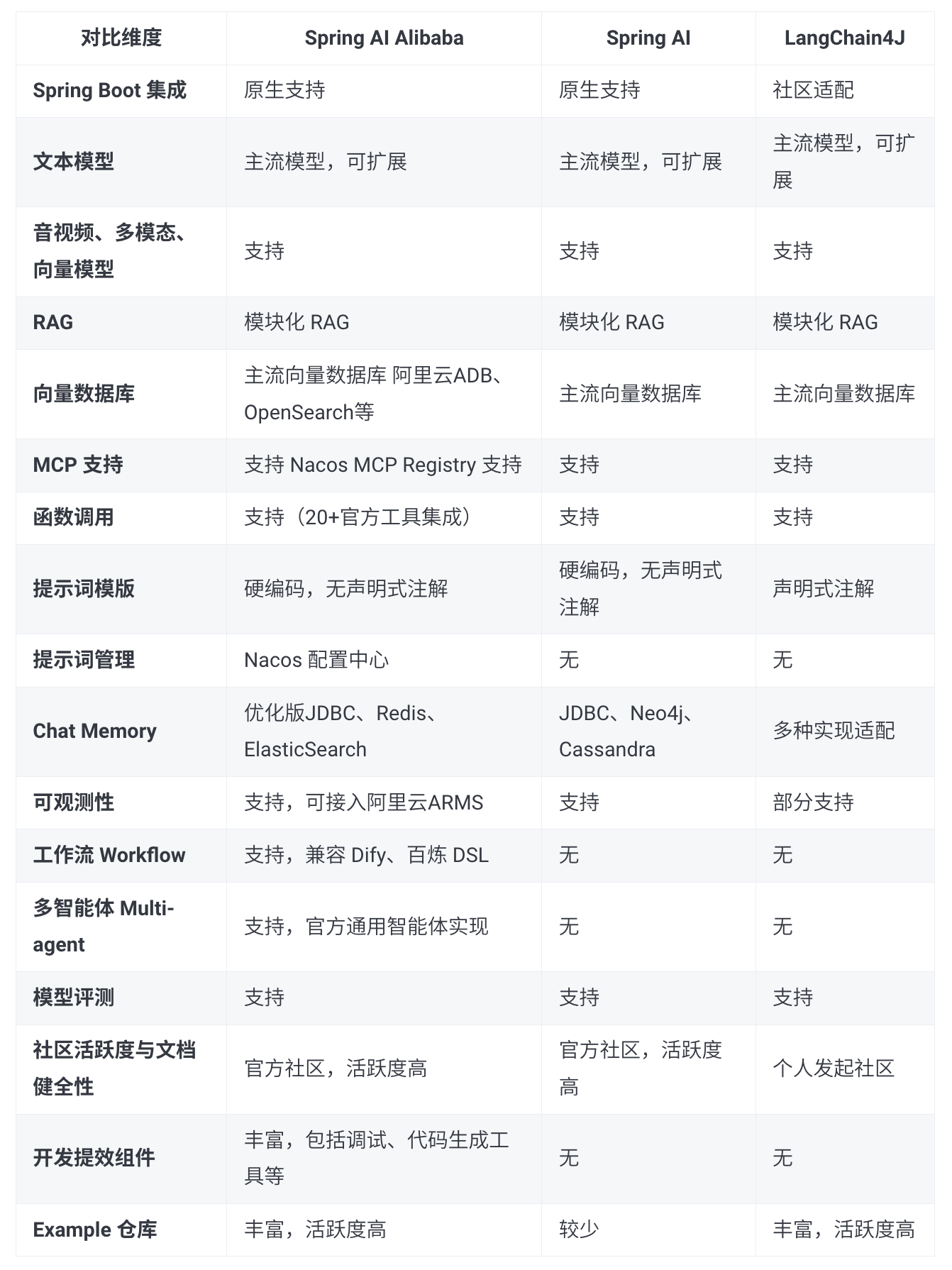
如何升级框架版本?
接下来进入实战环节,我会用自己之前开源的 AI 超级智能体项目 来详细演示如何将老版本的 Spring AI Alibaba 项目升级到 1.0 版本。大家一定要认真看,因为有些变动连官方文档都没有明确指出,是我在升级过程中踩坑摸索出来的宝贵经验。
友情提醒:这个项目涉及到向量数据库、MCP 服务、API Key 等外部依赖,直接下载项目是跑不起来的,这是正常现象。必须要按照项目说明补充相应的配置,所有需要配置的地方我都已经详细标注出来了。
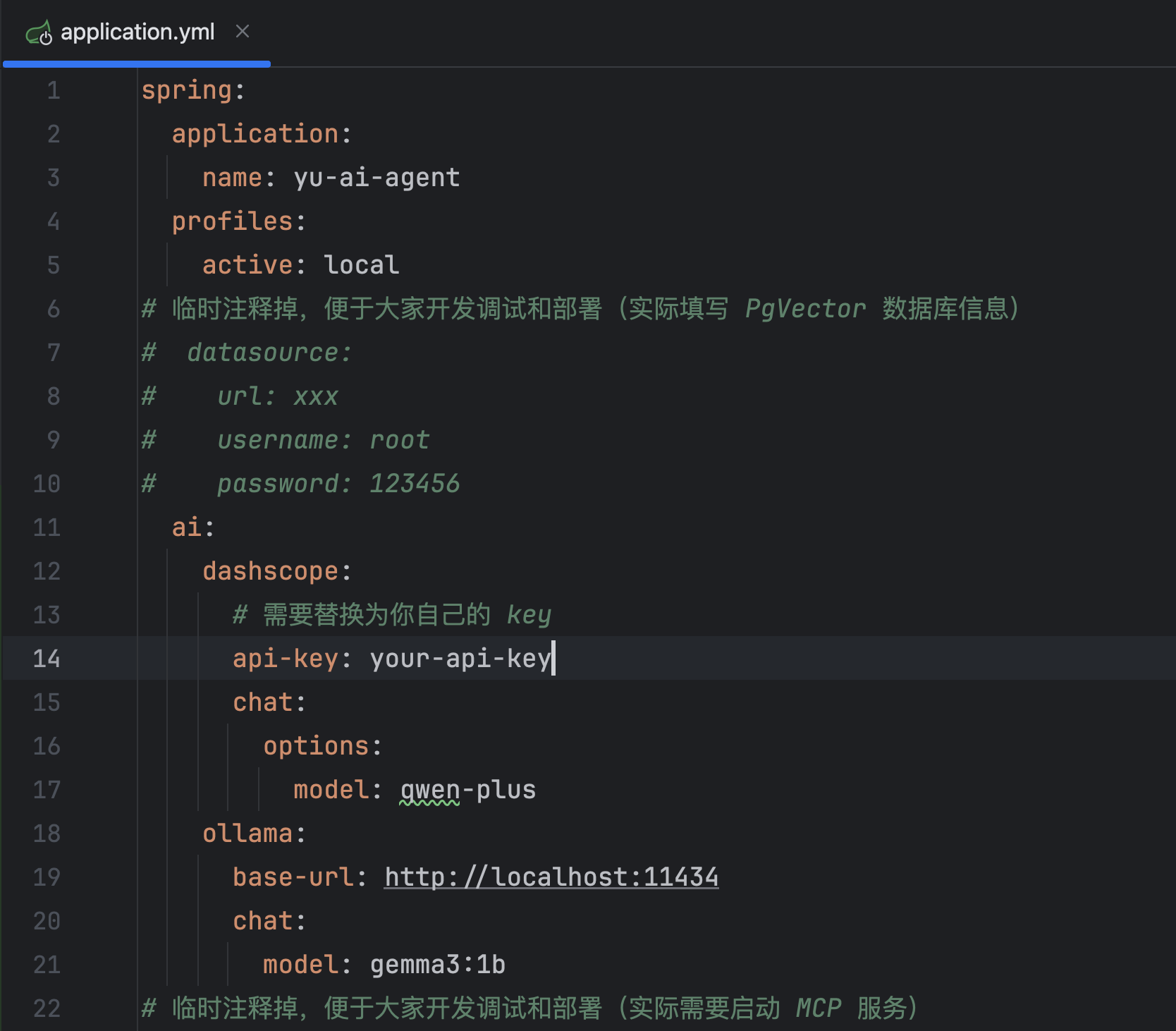
建议大家先新建一个本地配置文件,然后让我们开始将 Spring AI Alibaba 从 1.0.0-M6.1 版本升级到 1.0.0.2 版本。
第一步:依赖更新
我们的项目分为主项目和 MCP 服务子项目两部分,需要分别进行更新。
主项目依赖更新
1)更新 Spring AI Alibaba 基础依赖,从官方文档复制依赖管理配置并引入依赖:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-bom</artifactId>
<version>1.0.0.2</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter-dashscope</artifactId>
</dependency>
</dependencies>
2)更新 Spring AI 相关依赖
参考 官方文档 进行升级,首先引入仓库配置,确保能够正确拉取到 Spring AI 相关的依赖:
<repositories>
<repository>
<id>spring-snapshots</id>
<name>Spring Snapshots</name>
<url>https://repo.spring.io/snapshot</url>
<releases>
<enabled>false</enabled>
</releases>
</repository>
<repository>
<name>Central Portal Snapshots</name>
<id>central-portal-snapshots</id>
<url>https://central.sonatype.com/repository/maven-snapshots/</url>
<releases>
<enabled>false</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
</repositories>
在这个过程中,你可以通过 Maven 仓库 来查看最新版本信息:
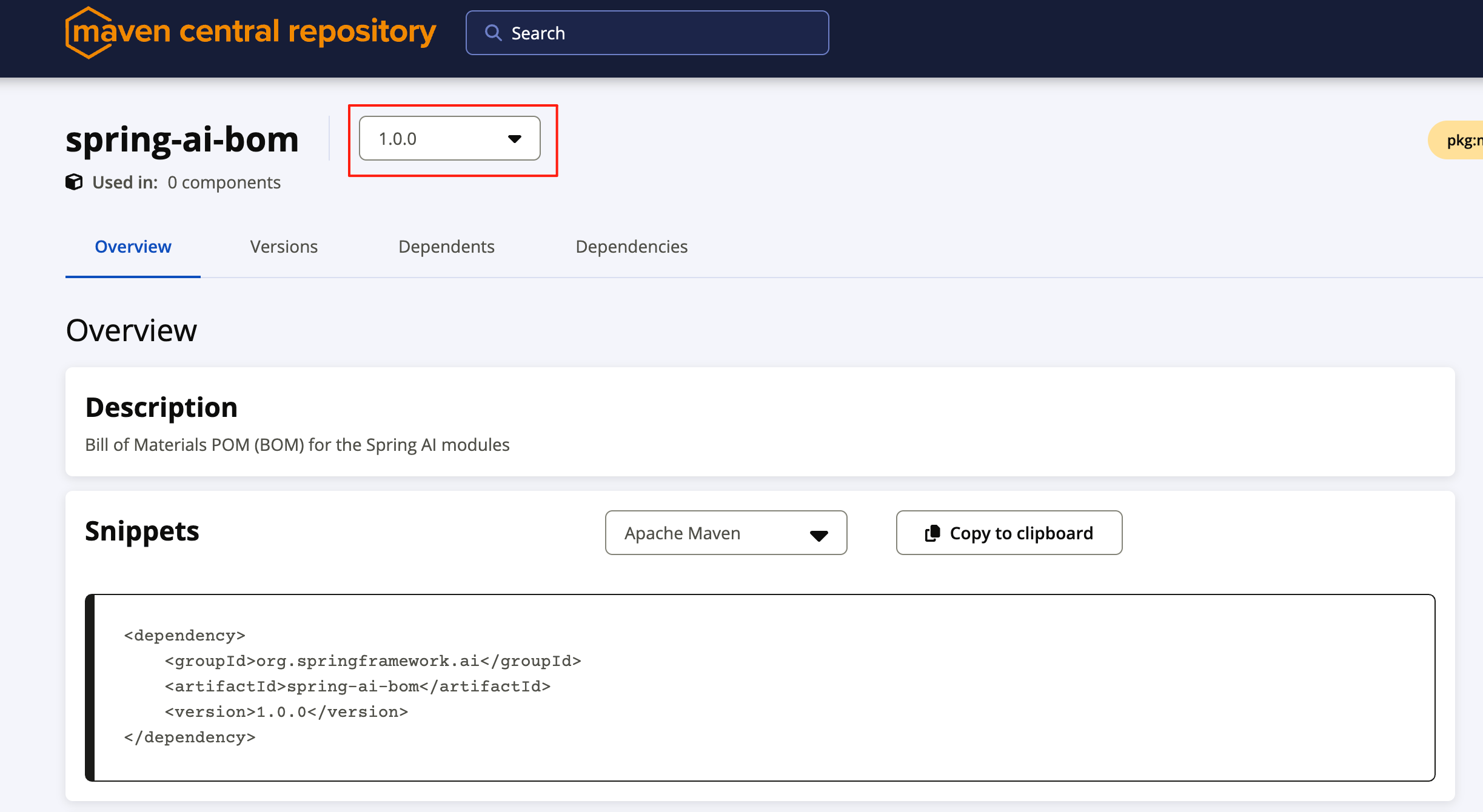
然后添加依赖管理配置,注意版本号不用添加 SNAPSHOT 后缀,就 1.0.0 版本:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>1.0.0</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
具体要修改的依赖项如下,修改前的依赖配置:
<!-- 本地部署大模型 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-ollama-spring-boot-starter</artifactId>
<version>1.0.0-M6</version>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-markdown-document-reader</artifactId>
<version>1.0.0-M6</version>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pgvector-store</artifactId>
<version>1.0.0-M6</version>
</dependency>
<!-- Spring AI MCP Client -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-mcp-client-spring-boot-starter</artifactId>
<version>1.0.0-M6</version>
</dependency>
修改后的依赖配置,鱼皮是依次参考官方文档进行确认和更新的:
-
Ollama:https://docs.spring.io/spring-ai/reference/api/chat/ollama-chat.html
-
Markdown Document Reader:https://docs.spring.io/spring-ai/reference/api/etl-pipeline.html#_markdown
-
PGvector:https://docs.spring.io/spring-ai/reference/api/vectordbs/pgvector.html#_manual_configuration
-
MCP:https://docs.spring.io/spring-ai/reference/api/mcp/mcp-client-boot-starter-docs.html
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-ollama</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-markdown-document-reader</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pgvector-store</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-mcp-client</artifactId>
</dependency>
3)更新完依赖后,建议安装 Maven Helper 插件来检测依赖冲突:
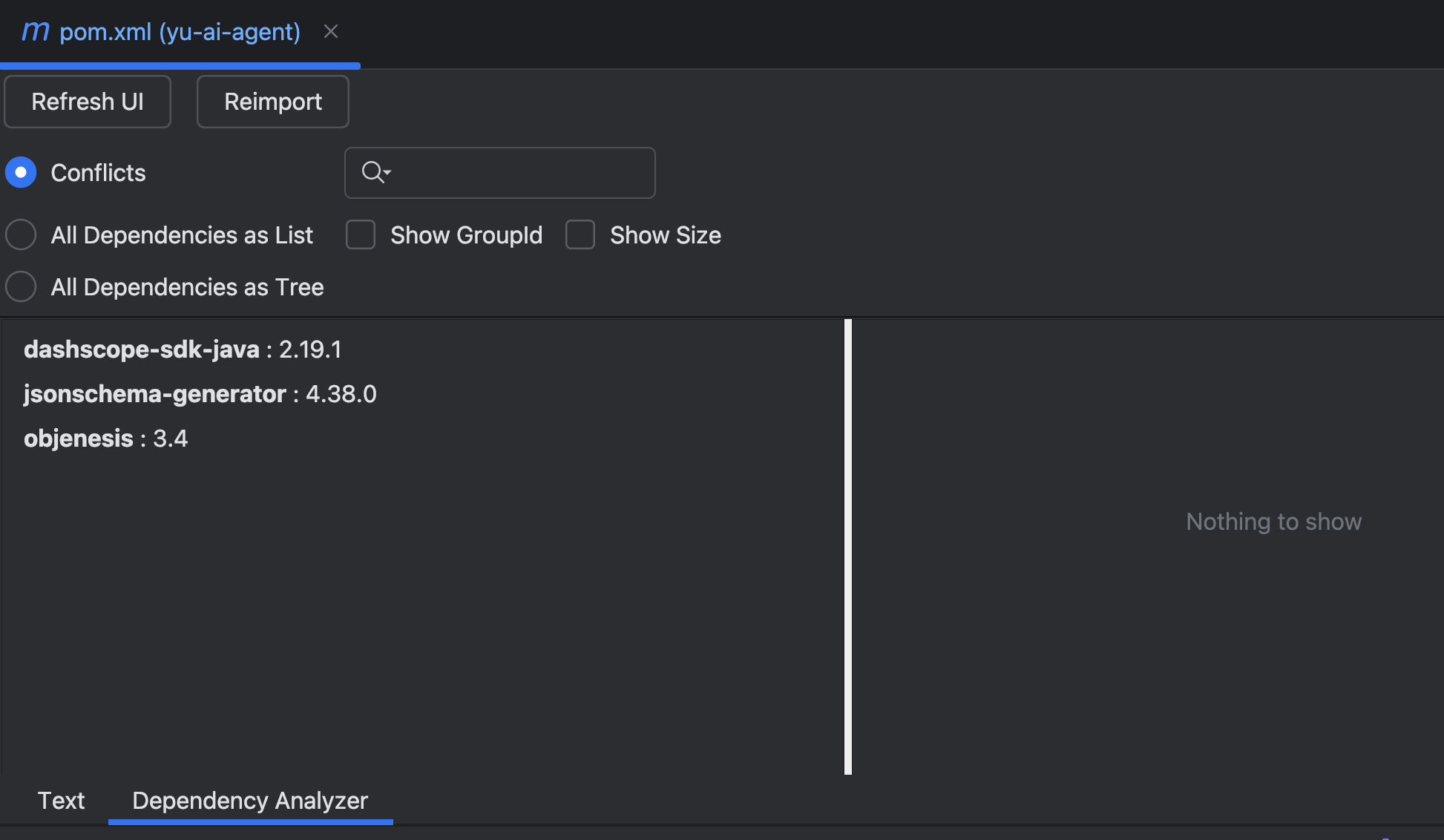
检查结果显示没有 Spring AI 相关冲突,说明依赖配置正确:
MCP 服务端项目依赖更新
MCP 服务端项目的更新相对简单,跟前面一样,引入仓库和依赖管理配置,然后只需要更新 spring-ai-starter-mcp-server-webmvc 依赖即可:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>1.0.0</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<repositories>
<repository>
<id>spring-snapshots</id>
<name>Spring Snapshots</name>
<url>https://repo.spring.io/snapshot</url>
<releases>
<enabled>false</enabled>
</releases>
</repository>
<repository>
<name>Central Portal Snapshots</name>
<id>central-portal-snapshots</id>
<url>https://central.sonatype.com/repository/maven-snapshots/</url>
<releases>
<enabled>false</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
</repositories>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-mcp-server-webmvc</artifactId>
</dependency>
第二步:代码问题修复
依赖更新完成后,接下来需要修复由于版本变更导致的代码问题。
1、Advisor 顾问功能修复
这是一个 破坏性变更,很多 advisor 相关的接口和方法都更新了,但坑爹的是官方文档并未明确说明这个变更!

遇到这种情况,我们可以参考源码(比如 SimpleLoggerAdvisor)的实现方式对之前开发的 advisor 进行修改。
1)修改后的 MyLoggerAdvisor 自定义日志拦截器代码:
@Slf4j
public class MyLoggerAdvisor implements CallAdvisor, StreamAdvisor {
@Override
public String getName() {
return this.getClass().getSimpleName();
}
@Override
public int getOrder() {
return 0;
}
private ChatClientRequest before(ChatClientRequest request) {
log.info("AI Request: {}", request.prompt());
return request;
}
private void observeAfter(ChatClientResponse chatClientResponse) {
log.info("AI Response: {}", chatClientResponse.chatResponse().getResult().getOutput().getText());
}
@Override
public ChatClientResponse adviseCall(ChatClientRequest chatClientRequest, CallAdvisorChain chain) {
chatClientRequest = before(chatClientRequest);
ChatClientResponse chatClientResponse = chain.nextCall(chatClientRequest);
observeAfter(chatClientResponse);
return chatClientResponse;
}
@Override
public Flux<ChatClientResponse> adviseStream(ChatClientRequest chatClientRequest, StreamAdvisorChain chain) {
chatClientRequest = before(chatClientRequest);
Flux<ChatClientResponse> chatClientResponseFlux = chain.nextStream(chatClientRequest);
return (new ChatClientMessageAggregator()).aggregateChatClientResponse(chatClientResponseFlux, this::observeAfter);
}
}
2)同样需要修复 ReReadingAdvisor,需要重新编写修改用户提示词的代码:
/**
* 自定义 Re2 Advisor
* 可提高大型语言模型的推理能力
*/
public class ReReadingAdvisor implements CallAdvisor, StreamAdvisor {
/**
* 执行请求前,改写 Prompt
*
* @param chatClientRequest
* @return
*/
private ChatClientRequest before(ChatClientRequest chatClientRequest) {
String userText = chatClientRequest.prompt().getUserMessage().getText();
// 添加上下文参数
chatClientRequest.context().put("re2_input_query", userText);
// 修改用户提示词
String newUserText = """
%s
Read the question again: %s
""".formatted(userText, userText);
Prompt newPrompt = chatClientRequest.prompt().augmentUserMessage(newUserText);
return new ChatClientRequest(newPrompt, chatClientRequest.context());
}
@Override
public ChatClientResponse adviseCall(ChatClientRequest chatClientRequest, CallAdvisorChain chain) {
return chain.nextCall(this.before(chatClientRequest));
}
@Override
public Flux<ChatClientResponse> adviseStream(ChatClientRequest chatClientRequest, StreamAdvisorChain chain) {
return chain.nextStream(this.before(chatClientRequest));
}
@Override
public int getOrder() {
return 0;
}
@Override
public String getName() {
return this.getClass().getSimpleName();
}
}
2、工具调用功能修复
1)ToolRegistration 工具注册类的包名发生了变更,需要修改:
// 原来:
import org.springframework.ai.tool.ToolCallbacks;
// 改为:
import org.springframework.ai.support.ToolCallbacks;
2)LoveApp 中的工具调用方法需要修改:
// 修改为:
.toolCallbacks(toolCallbackProvider)
3)ToolCallAgent 的配置也需要修改,这是为了禁用 Spring AI 内置的工具调用机制,自己处理工具调用的流程和消息上下文:
public ToolCallAgent(ToolCallback[] availableTools) {
super();
this.availableTools = availableTools;
this.toolCallingManager = ToolCallingManager.builder().build();
// 禁用 Spring AI 内置的工具调用机制,自己维护选项和消息上下文
this.chatOptions = DashScopeChatOptions.builder()
.withInternalToolExecutionEnabled(false)
.build();
}
3、RAG 知识库功能修复
1)PgVector 配置修改
由于我们原本就是手动引入 PgVector,没有使用 Spring Boot 的自动配置包,所以只需要移除项目启动类的自动配置即可:
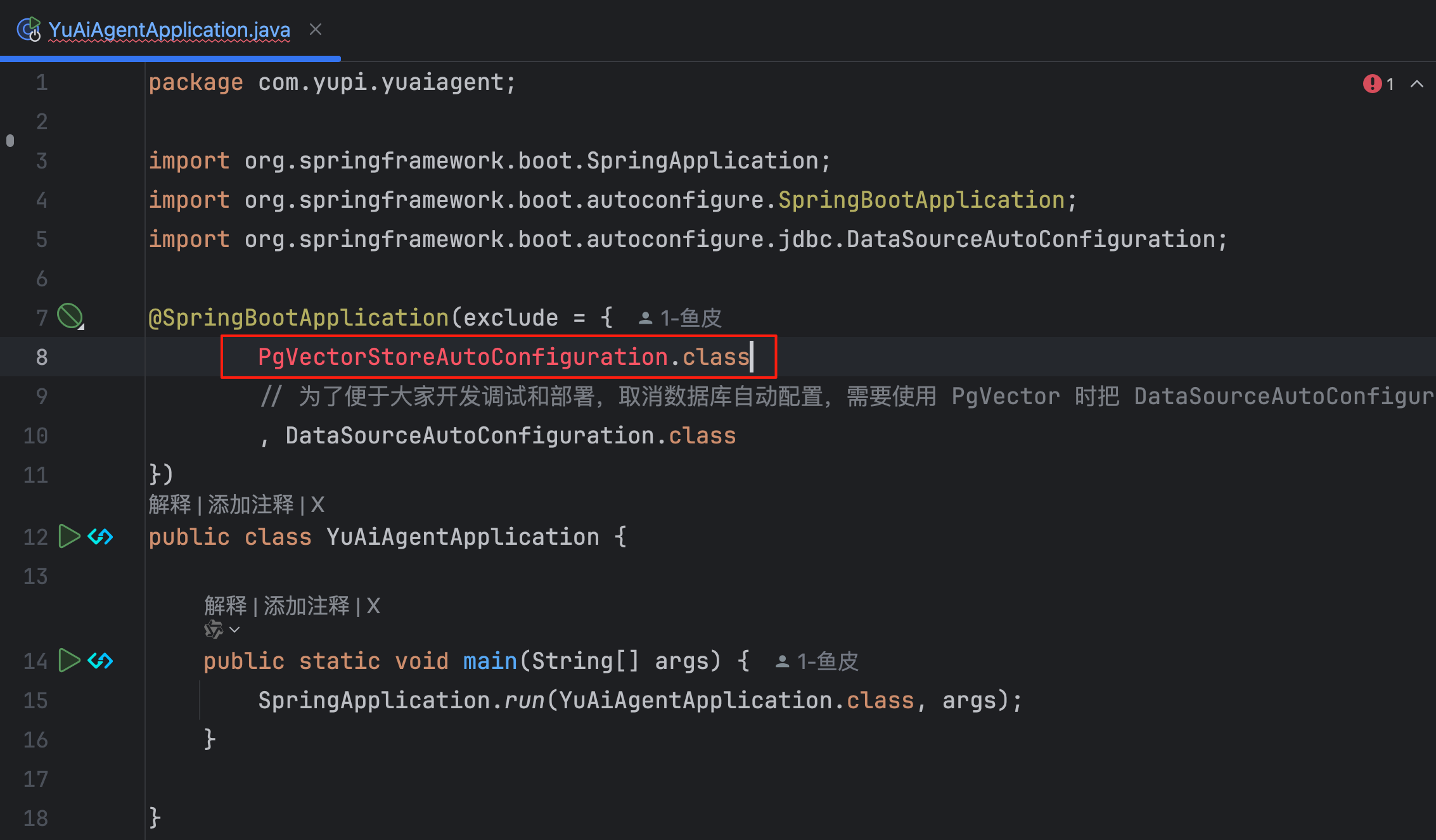
代码如下:
@SpringBootApplication(exclude = {
// 为了便于大家开发调试和部署,取消数据库自动配置
// 需要使用 PgVector 时把 DataSourceAutoConfiguration.class 删除
DataSourceAutoConfiguration.class
})
public class YuAiAgentApplication {
public static void main(String[] args) {
SpringApplication.run(YuAiAgentApplication.class, args);
}
}
2)RAG 相关类包名修复
自定义 RAG 知识库相关的 LoveAppRagCloudAdvisorConfig 和 LoveAppRagCustomAdvisorFactory 类,包名发生了变更:
// 原来:
import org.springframework.ai.chat.client.advisor.RetrievalAugmentationAdvisor;
// 改为:
import org.springframework.ai.rag.advisor.RetrievalAugmentationAdvisor;
3)DashScopeApi 构建方式修改,之前是 new,改为 builder 模式:
DashScopeApi dashScopeApi = DashScopeApi.builder()
.apiKey(dashScopeApiKey)
.build();
4)如果在 LoveApp 中想使用 QuestionAnswerAdvisor,需要引入新的依赖,因为包名发生了变更:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-advisors-vector-store</artifactId>
</dependency>
4、对话记忆功能修复
对话记忆的写法变更还挺大的,参考 官方文档。
1)修改 LoveApp 类中对话记忆的设置方式,新版本将算法和存储进行了分离,支持了更多的存储方式:
// 初始化基于内存的对话记忆
MessageWindowChatMemory chatMemory = MessageWindowChatMemory.builder()
.chatMemoryRepository(new InMemoryChatMemoryRepository())
.maxMessages(20)
.build();
2)修改对话记忆 Advisor 的创建方式,感觉 Spring AI 要统一用建造者模式创建对象了:
chatClient = ChatClient.builder(dashscopeChatModel)
.defaultSystem(SYSTEM_PROMPT)
.defaultAdvisors(
MessageChatMemoryAdvisor.builder(chatMemory).build(),
)
3)会话 ID 键名修改:
.advisors(spec -> spec.param(ChatMemory.CONVERSATION_ID, chatId))
4)修改基于文件持久化的会话记忆 FileBasedChatMemory 类,调整 get 方法,因为 ChatMemory 接口的 get 方法参数发生了变更:
@Override
public List<Message> get(String conversationId) {
return getOrCreateConversation(conversationId);
}
5、 其他
还有个小细节,要修改 MyKeywordEnricher 类,因为关键词元信息增强器的包名发生了变更:
// 原来:
import org.springframework.ai.transformer.KeywordMetadataEnricher;
// 改为:
import org.springframework.ai.model.transformer.KeywordMetadataEnricher;
总结
以上就是 Spring AI Alibaba 框架的升级过程,涉及的修改点还是比较多的、而且还要对所有功能进行测试,很耗时间,这就是为什么在企业中 “项目能运行,就不要动它”。
所有的代码修改我都已经开源到 GitHub 上了,每一次的提交记录都非常清晰,方便大家对照学习。如果有遗漏的地方,也欢迎大家评论区指出,我会继续补充和完善。
不得不感叹技术的更新真的是太太太太快了,但也正是这种快速迭代让我们能够享受到越来越强大的 AI 开发能力。很快我会再带大家用更新的技术做一套全新的 AI 全栈项目,点个关注,敬请期待吧~