GitHub: https://github.com/PeterGriffinJin/Search-R1
Motivation
使用seach engine给reasoning LLM赋能
Method
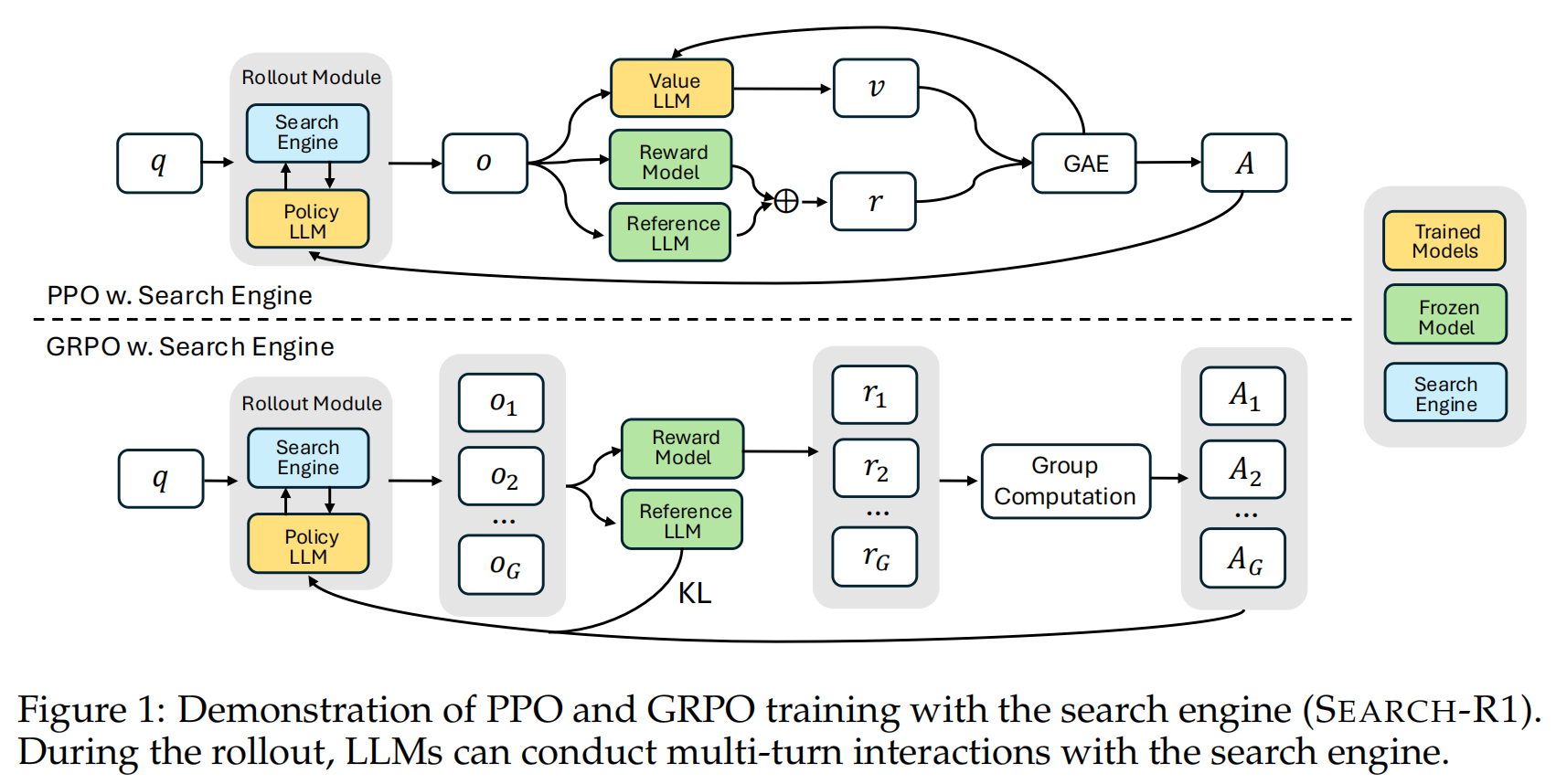
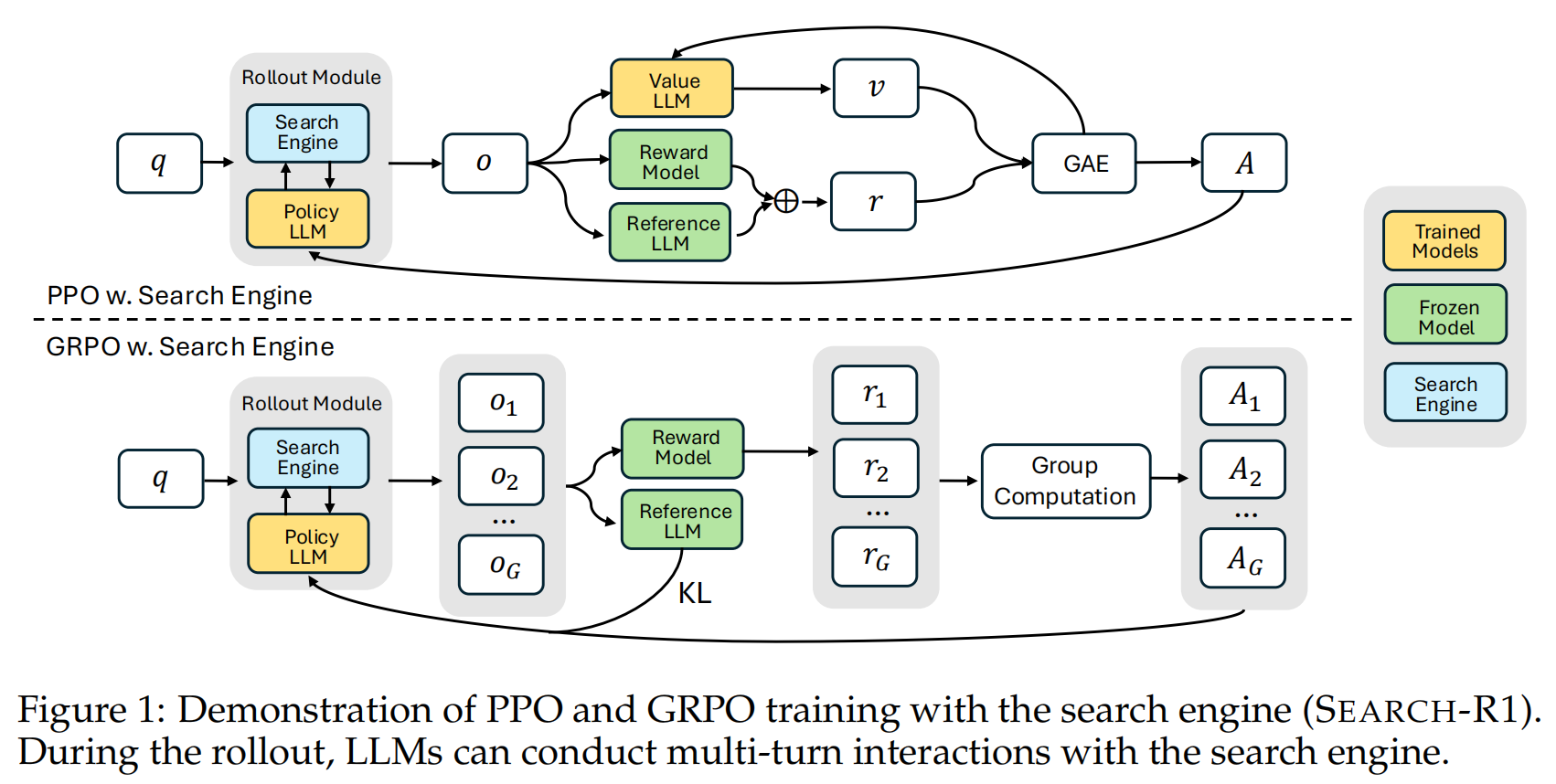
在PPO的基础上,基于给定的Search Egine \(R\),进行轨迹生成。
\[J_{PPO}(\theta) = \mathbb{E}_{(q,a)\sim\mathcal{D}, o\sim{\pi_{old}(\cdot|q;R)}}\frac{1}{\sum_{t=1}^{|o|}I(o_t)} \min[\frac{\pi_{\theta}(o_t|q, o_{<t};R)}{\pi_{old}(o_t|q,o_{<t};R)} A_t, clip(1-\epsilon, 1+\epsilon, \frac{\pi_{\theta}(o_t|q,o_{<t};R)}{\pi_{old}(o_t|q, o_{<t};R)})A_t] \]
其中需要对\(R\)返回的token进行mask
\[I(o_t) = \begin{cases} 0, & o_t\mathrm{\ is\ a\ retrived\ token};\\ 1, & otherwise; \end{cases} \]
Experiments
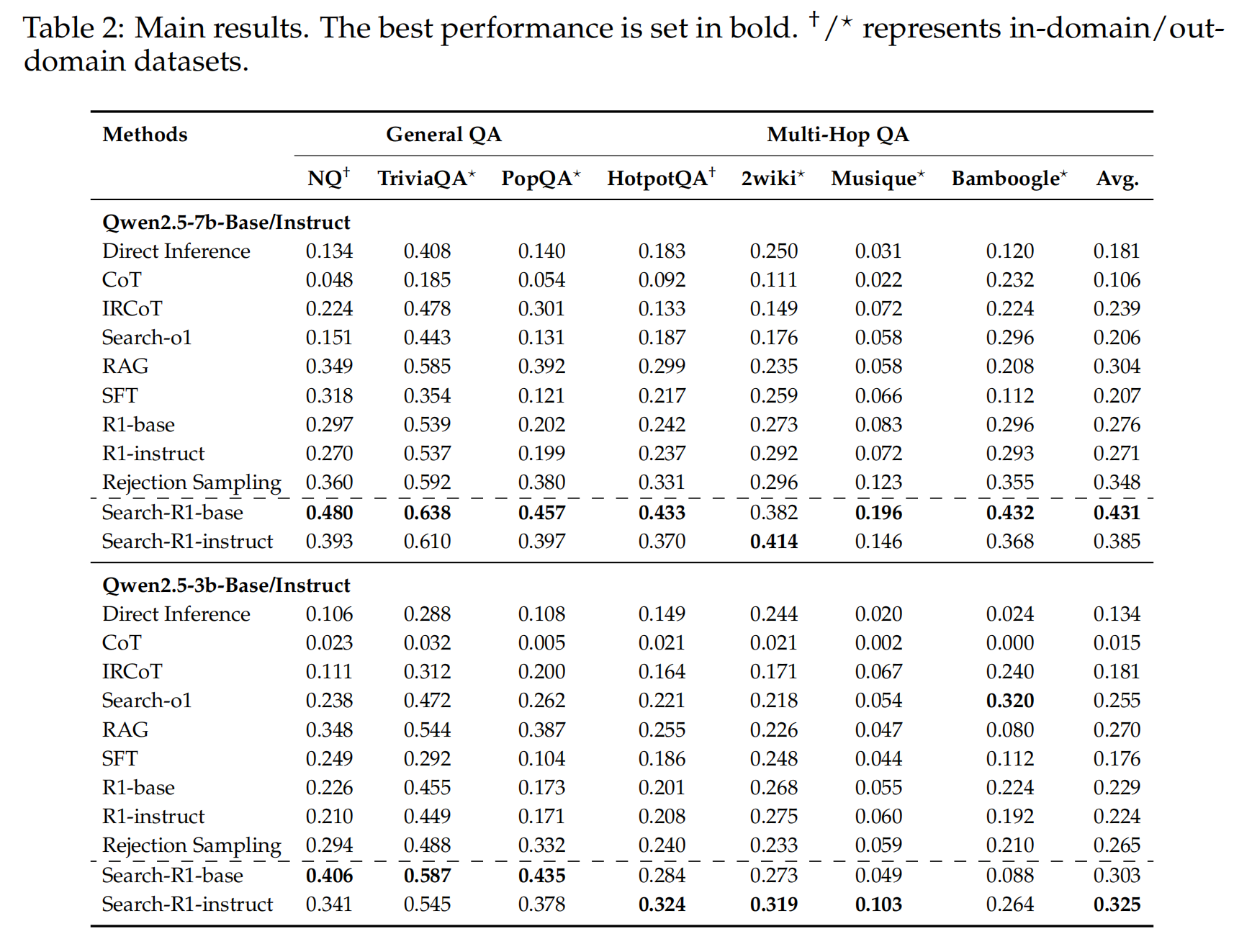
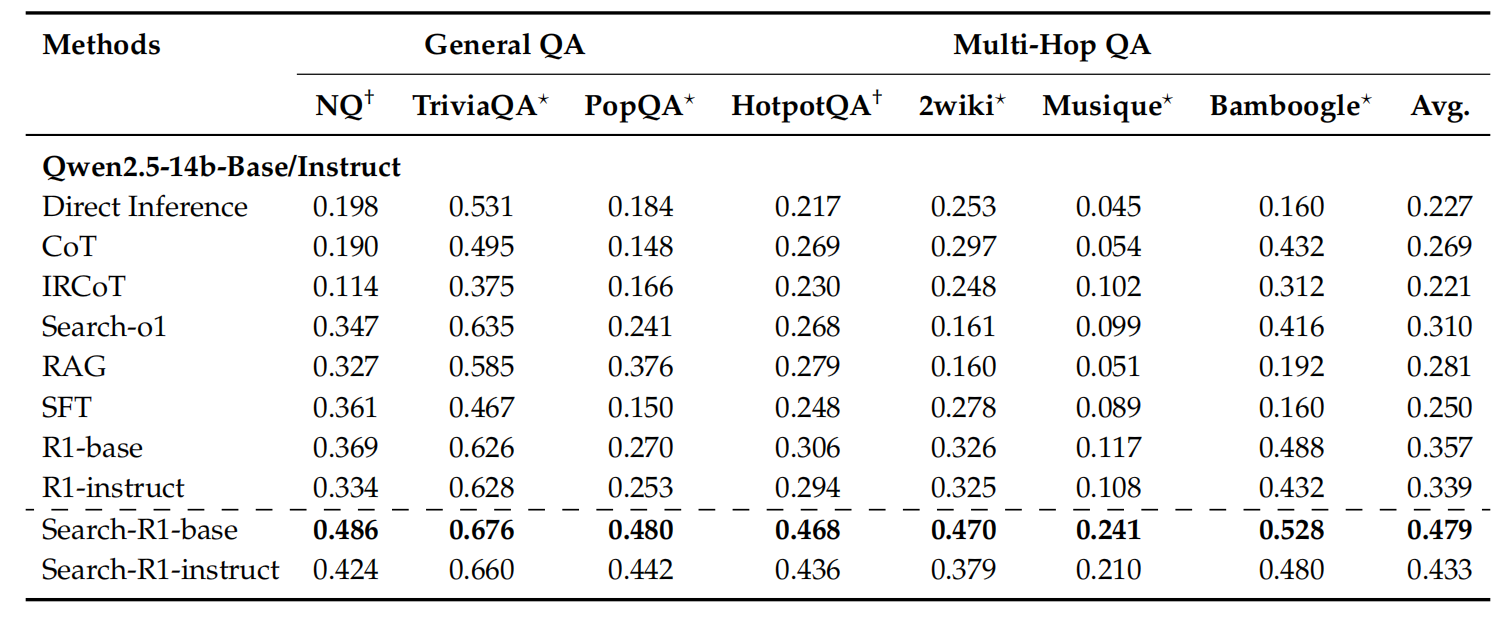
默认使用PPO,整体效果来看search-r1强化是有效的。training dataset来自NQ和Hotpot QA
-
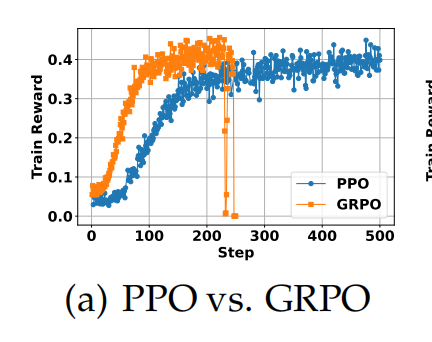
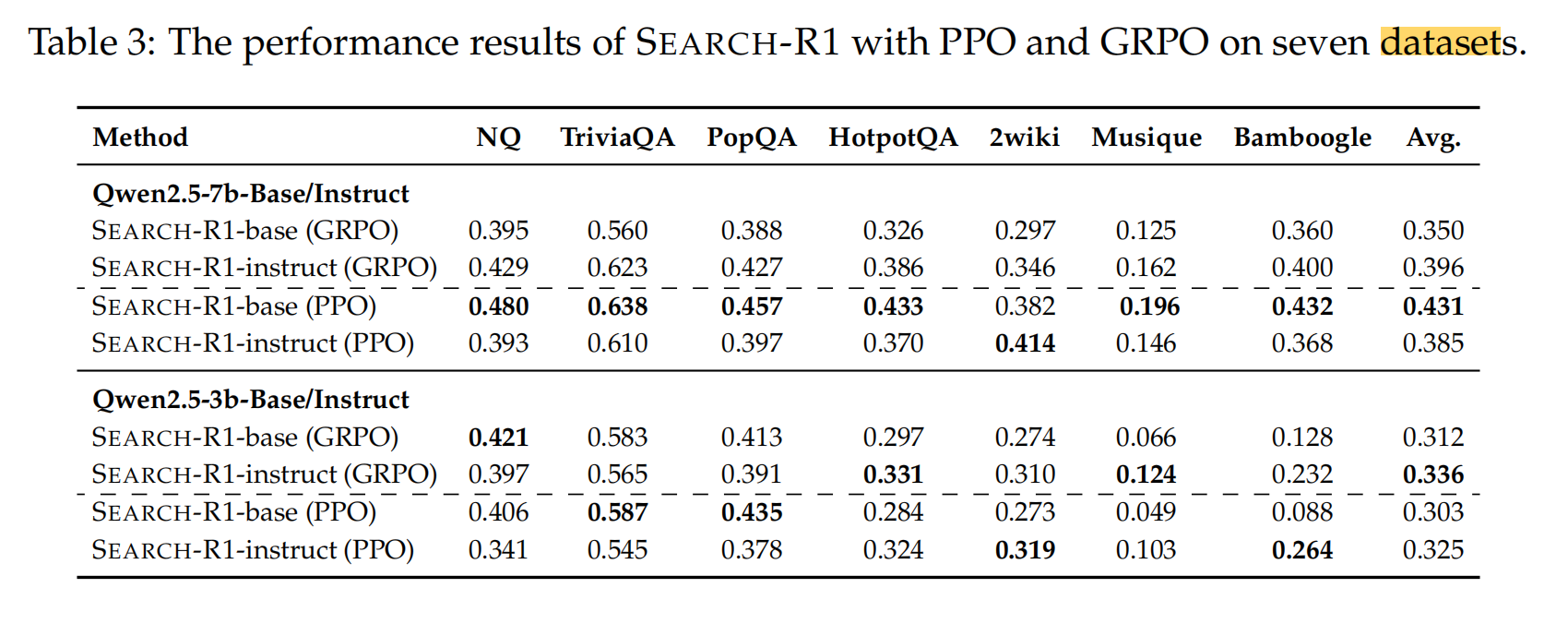
PPO vs GRPO
认为PPO比GRPO更加稳定,效果更好;GRPO收敛更快
-
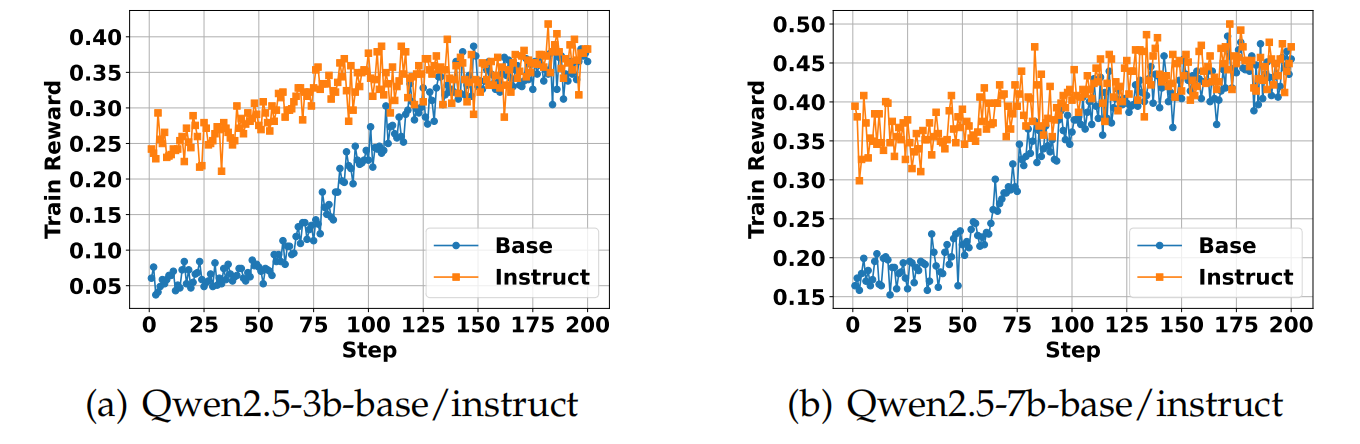
Instruct model vs base model
认为虽然instruct model在最开始的reward要优于base model,但是在step的后期,两者reward是可比的,且base model的效果优于instruct model。
(我认为,这里instruct好于base,可能是因为instruct后,模型的多样性下降了(因为RL的对齐),导致模型在search task的探索能力下降。但是,WebDancer等文章均使用的是Instruct model,我认为是那些工作 并不是一上来就search RL的,而是先做RFT的SFT,想让instruct model适应RL的格式,并注入search task的领域知识(planing能力、工具调用能力、总结能力等等)。如果是对base model做post-training的RFT(数据量可能不大),base model会出现指令不遵循的问题。因此在SFT+RL的后续WebAgent的工作中,一半以Instruct model为基座。)
-
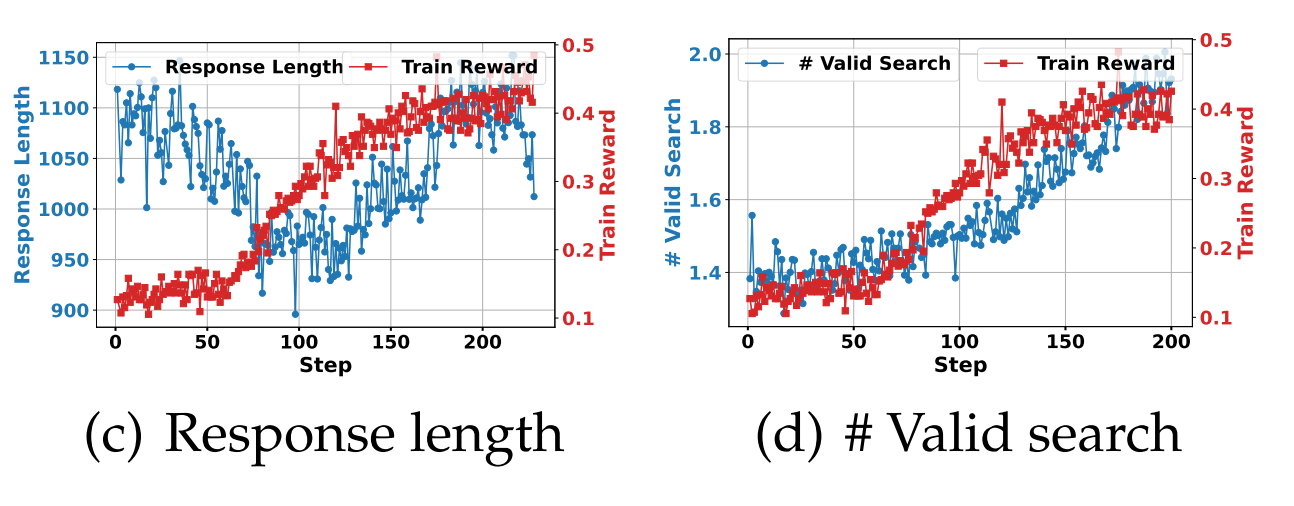
Response length and valid study
- early stage:response length明显下降,同时reward有小幅度提升(更好的理解search 任务,输出更精简)
- latter stage:response length回升,reward也提升(可以发现是seach call的次数提升导致)
-
ablation of retrived token mask
mask是必要的,因为model的预测目标本就不是 预测出retrieved token,而是学会工具调用与计划总结
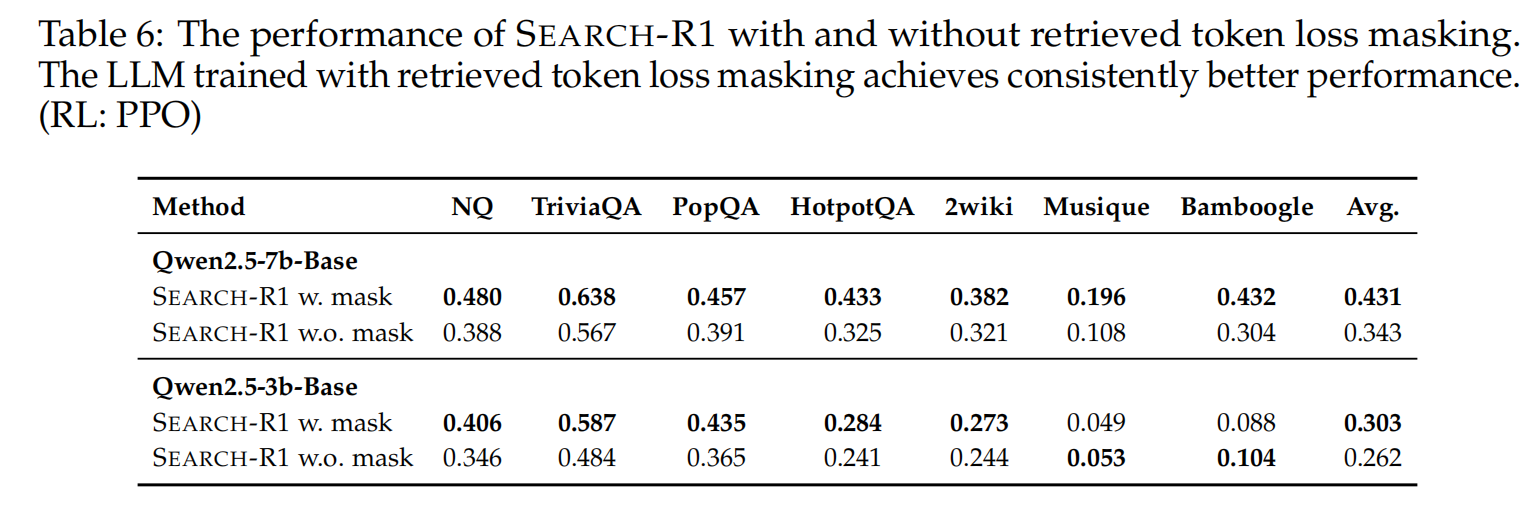
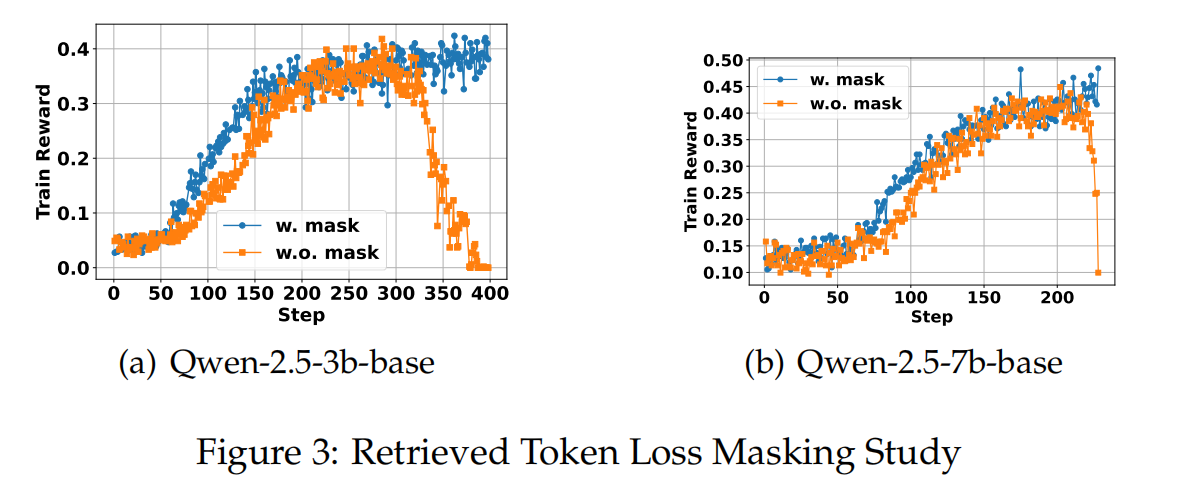
-
Number of Retrieved Passages Study in SEARCH-R1 Training
召回的docs不是越多越好(actor model总结时会更容易出现幻觉或是遗漏细节),也不是越少越好(巧妇难为无米之炊)
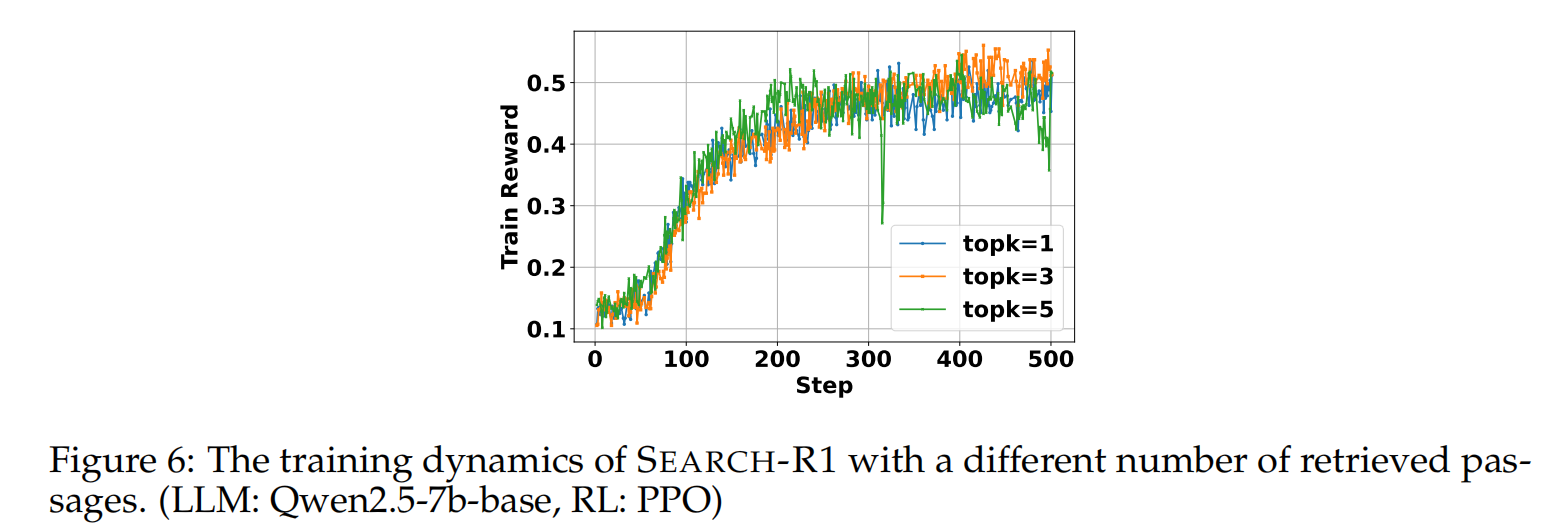
-
group size of GRPO
GRPO的size 大的话,效果好收敛快,但是不太稳定(感觉是论文工作设计有问题,我没有遇到过这种reward sharp decrease)
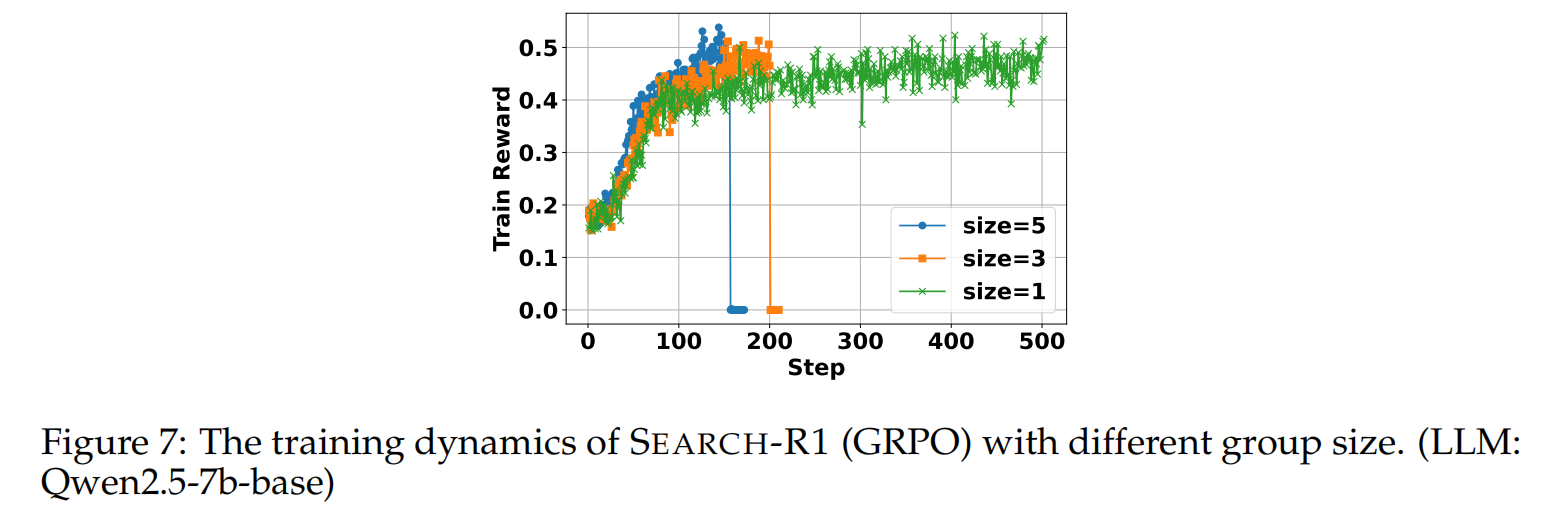
Conclusion
提出了agent下的RL方法,但是没有构建sft的轨迹数据,导致无法学到 planing规划、单一工具调用、多工具关系的能力。
代码实现
Agent-RL的代码实现难点在于以下两方面,我将会对比naive RL和search-r1的在以下两方面的代码进行解析
- traj的loop 生成
- traj的reward manager
1. loop生成轨迹数据
区别于naive的RL,search-r1需要提取每步的action和tool,并进行retrieve调用。
首先咱们先来看一下verl在verl.trainer.ppo.ray_trainer.py调用的self.actor_rollout_wg.generate_sequences(gen_batch_output)的navie实现。
verl/workers/rollout/naive/naive_rollout.py。值得注意的是,rollout是采样,不需要保存计算图的,使用@torch.no_grad
class NaiveRollout(BaseRollout):
def __init__(self, module: nn.Module, config):
"""A naive rollout. It requires the module to be compatible with huggingface APIs. That is:
The module should define __call__ to receive input_ids, attention_mask and position_ids.
It outputs a structure that contains logits field.
Args:
module: module here follows huggingface APIs
config: DictConfig
"""
super().__init__()
self.config = config
self.module = module
#########################################################################
# rollout 不保存计算图
#########################################################################
@torch.no_grad()
def generate_sequences(self, prompts: DataProto) -> DataProto:
"""Generate sequences"""
#########################################################################
# 值得注意的是 如果是grpo,那么这里batch['input_ids']的shape是(batch_size*rollout.n, prompt_length)的
# 在ray_trainer.py里面有先做repeat操作
#########################################################################
idx = prompts.batch['input_ids'] # (bs, prompt_length)
attention_mask = prompts.batch['attention_mask'] # left-padded attention_mask
position_ids = prompts.batch['position_ids']
# used to construct attention_mask
eos_token_id = prompts.meta_info['eos_token_id']
batch_size = idx.size(0)
prompt_length = idx.size(1)
self.module.eval()
# 这里的pre_attention_mask是记录每一个sequence是否已经rollout完毕
# 即 在当前iter生成的token之前 是否已经出现过 eos_token
prev_attention_mask = torch.ones(size=(batch_size, 1), dtype=attention_mask.dtype, device=attention_mask.device)
logits_lst = []
#########################################################################
# 这里整体的思路是,每个迭代iter 同步生成所有sequence的同一位置(position_id)的 next_token_id
# 并且循环 response_length次,无论是否遇到eos_id
# 这么做的目的在于,基于矩阵操作并行地生成所有sequence,而不是每个sequence的生成,保证rollout效率
#########################################################################
for _ in range(self.config.response_length):
# if the sequence context is growing too long we must crop it at block_size
# idx_cond = idx if idx.size(1) <= self.config.block_size else idx[:, -self.config.block_size:]
idx_cond = idx
# forward the model to get the logits for the index in the sequence
# we use huggingface APIs here
output = self.module(input_ids=idx_cond, attention_mask=attention_mask, position_ids=position_ids)
# logits: (bs, hidden_layer_num, vocab_size)
logits = output.logits
#########################################################################
# 下面是一些采样的操作
# temperature: 每个token的所有的vocab的logit/temp
# topk: 把非topk的vocab 的logit 赋值为-inf,不影响后续的softmax,忽略这些低概率的vocab
# do_sample: 是概率采样 或是 选择概率最大的idx
#########################################################################
# pluck the logits at the final step and scale by desired temperature
logits = logits[:, -1, :] / self.config.temperature # (bs, vocab_size)
# optionally crop the logits to only the top k options
if self.config.top_k is not None:
v, _ = torch.topk(logits, min(self.config.top_k, logits.size(-1)))
logits[logits < v[:, [-1]]] = -float('Inf')
# apply softmax to convert logits to (normalized) probabilities
probs = F.softmax(logits, dim=-1)
# sample from the distribution
if self.config.do_sample:
idx_next = torch.multinomial(probs, num_samples=1)
else:
idx_next = torch.argmax(probs, dim=-1, keepdim=True)
#########################################################################
# 下面进行拼接
# attention_mask
# position_ids
# idx
#########################################################################
# 将当前token的mask拼接到之前的attention_mask上
# 其实当前token是否被mask主要看 之前的token是否出现 eos_token
attention_mask = torch.cat((attention_mask, prev_attention_mask), dim=-1)
# 如果当前token是eos_token或之前出现过eos_token,那么之后的所有token都应该是被mask掉的
prev_attention_mask = torch.logical_and(idx_next != eos_token_id, prev_attention_mask.bool())
prev_attention_mask.to(attention_mask.dtype)
position_ids = torch.cat((position_ids, position_ids[:, -1:] + 1), dim=-1)
# append sampled index to the running sequence and continue
idx = torch.cat((idx, idx_next), dim=1)
logits_lst.append(logits)
# 将[(bs, vocab_size), ..., (bs, vocab_size)] 一共resp_length个 在1维度上进行堆叠
logits = torch.stack(logits_lst, dim=1) # (bs, response_length, vocab_size)
prompts = idx[:, :prompt_length] # (bs, prompt_length)
response = idx[:, prompt_length:] # (bs, response_length)
# 获取采样的每个token的概率(一般就是softmax一下,再根据response进行检索)
log_probs = logprobs_from_logits(logits=logits, labels=response)
batch = TensorDict(
{
'input_ids': prompts,
'responses': response,
'sequences': idx,
'old_log_probs': log_probs,
'attention_mask': attention_mask,
'position_ids': position_ids,
},
batch_size=batch_size)
self.module.train()
return DataProto(batch=batch)
可以发现的是,batch的response相当于是右填充,因为每个seq首次出现的eos_idx的后面的attnetion_mask都是1,具体是以下代码导致的:
# 将当前token的mask拼接到之前的attention_mask上
# 其实当前token是否被mask主要看 之前的token是否出现 eos_token
attention_mask = torch.cat((attention_mask, prev_attention_mask), dim=-1)
# 如果当前token是eos_token或之前出现过eos_token,那么之后的所有token都应该是被mask掉的
prev_attention_mask = torch.logical_and(idx_next != eos_token_id, prev_attention_mask.bool())
好了,看完naive的一个batch的sequences的generate流程,我们需要进一步看一下agent的traj的生成。
traj可以简单地认为是naive sequence的loop,但是需要对在每个step生成的sequence进行decode,来解析工具,并将工具调用的结果拼接到sequence的后面作为prompt,进行后续step的生成。
search-r1的训练流程为verl.trainer.ppo.ray_trainer.py,与原始verl最大的区别在于使用了新的LLMGenerationManager.run_llm_loop()方法以生成agent traj,因此我们先阅读这个主要模块:search_r1.llm_agent.generation.py
@dataclass
class GenerationConfig:
max_turns: int
# 最大开始prompt长度
max_start_length: int
# 最大累积prompt长度(start+(repsonse+obser)*step)
max_prompt_length: int
# 最大单次生成response的长度
max_response_length: int
# 最大工具返回内容的长度
max_obs_length: int
num_gpus: int
# 是否需要think
no_think_rl: bool=False
# search engine的url
search_url: str = None
# 召回docs的个数
topk: int = 3
class LLMGenerationManager:
...
#################################################################
# 生成agent traj数据,循环config.max_turns轮,每个traj最多是由max_turns*[sequence]拼接得到的
#################################################################
def run_llm_loop(self, gen_batch, initial_input_ids: torch.Tensor) -> Tuple[Dict, Dict]:
"""Run main LLM generation loop."""
#################################################################
# 下面初始化一些全局变量,用于维护 batch中每一个traj在 每个轮次turn的
# prompt response mask status action_stats search_stats
#################################################################
# 左填充
original_left_side = {'input_ids': initial_input_ids[:, -self.config.max_start_length:]}
# 右填充
original_right_side = {'responses': initial_input_ids[:, []], 'responses_with_info_mask': initial_input_ids[:, []]}
# 当前轮次 每个taj是否是active的(是否未完成且无异常):(bsz*rollout.n)
# 若active_mask = 0,那么这个example可能是结果了或是异常了,就不再进行后续turn的生成了
active_mask = torch.ones(gen_batch.batch['input_ids'].shape[0], dtype=torch.bool)
# 每个traj的active turn的总数(这个traj的turn总数)
turns_stats = torch.ones(gen_batch.batch['input_ids'].shape[0], dtype=torch.int)
# 每个traj的action的总数(不一定等于turns_stats,因为有些turn可能action是错误的,不在(answer, search)中)
valid_action_stats = torch.zeros(gen_batch.batch['input_ids'].shape[0], dtype=torch.int)
# 每个traj的search action的总数( 一般是turns_stats - answer_num(一般是1) )
valid_search_stats = torch.zeros(gen_batch.batch['input_ids'].shape[0], dtype=torch.int)
# 每个轮次中 活跃的traj的数量
active_num_list = [active_mask.sum().item()]
rollings = gen_batch
#################################################################
# 下面开始 轮次循环,每个轮次需要生成response+提取工具+调用工具+获取obs+拼接prompt
#################################################################
# Main generation loop
for step in range(self.config.max_turns):
if not active_mask.sum():
break
rollings.batch = self.tensor_fn.cut_to_effective_len(
rollings.batch,
keys=['input_ids', 'attention_mask', 'position_ids']
)
# gen_output = self.actor_rollout_wg.generate_sequences(rollings)
# 仅筛选出还是active的traj(根据active_mask)
rollings_active = DataProto.from_dict({
k: v[active_mask] for k, v in rollings.batch.items()
})
# 这里先认为num_gpus是1, 并没有data-paralle,直接就是gen_output = self.actor_rollout_wg.generate_sequences(rollings)生成response
gen_output = self._generate_with_gpu_padding(rollings_active)
meta_info = gen_output.meta_info
# 对responses (bsz*rollout.n, response_length)做后处理
# 先做decode,将token ids解码成字符串,提取<search></search>包裹的动作或是<answer></answer>包裹的答案
# 并对提取出的search或是answer重新进行encode得到ids返回(右填充)
responses_ids, responses_str = self._postprocess_responses(gen_output.batch['responses'])
# 根据active_mask,将不active的exmaple的ids用pad_token填充,其str为""
# 因为active的example数量小于等于 batch的大小,为了填充batch,则需要padding not active example
responses_ids, responses_str = self.tensor_fn._example_level_pad(responses_ids, responses_str, active_mask)
# 调用search engine,返回所有exmaple的 【docs、是否成功、action是否合理、是否是search动作】 的列表
# Execute in environment and process observations
next_obs, dones, valid_action, is_search = self.execute_predictions(
responses_str, self.tokenizer.pad_token, active_mask
)
# 如果done的话,那么就要mask掉,因此是0
curr_active_mask = torch.tensor([not done for done in dones], dtype=torch.bool)
# 上个turn是not active,那么这个轮次还是
active_mask = active_mask * curr_active_mask
active_num_list.append(active_mask.sum().item())
turns_stats[curr_active_mask] += 1
valid_action_stats += torch.tensor(valid_action, dtype=torch.int)
valid_search_stats += torch.tensor(is_search, dtype=torch.int)
# 处理observation,先右填充编码,再进行max_obs_length截断,获取靠右左侧的obs
next_obs_ids = self._process_next_obs(next_obs)
# 将每traj的rolling+response_ids+next_obs_ids进行拼接
# 注意:rolling是左填充,response obs均是右填充
# 因此 拼接完成后,还需要将中间的padding ids移动到左侧,保持其他token的原有位置,继续维持rollings的左填充
# Update states
rollings = self._update_rolling_state(
rollings,
responses_ids,
next_obs_ids
)
# 同样是拼接 original_right_side+response+obs
# 但保持右填充
original_right_side = self._update_right_side(
original_right_side,
responses_ids,
next_obs_ids
)
# 可能存在一些example经过max_turns次循环后,还是没有得到answer,导致没有not active
# final LLM rollout
if active_mask.sum():
rollings.batch = self.tensor_fn.cut_to_effective_len(
rollings.batch,
keys=['input_ids', 'attention_mask', 'position_ids']
)
# gen_output = self.actor_rollout_wg.generate_sequences(rollings)
rollings_active = DataProto.from_dict({
k: v[active_mask] for k, v in rollings.batch.items()
})
gen_output = self._generate_with_gpu_padding(rollings_active)
meta_info = gen_output.meta_info
responses_ids, responses_str = self._postprocess_responses(gen_output.batch['responses'])
responses_ids, responses_str = self.tensor_fn._example_level_pad(responses_ids, responses_str, active_mask)
# # Execute in environment and process observations
_, dones, valid_action, is_search = self.execute_predictions(
responses_str, self.tokenizer.pad_token, active_mask, do_search=False
)
curr_active_mask = torch.tensor([not done for done in dones], dtype=torch.bool)
active_mask = active_mask * curr_active_mask
active_num_list.append(active_mask.sum().item())
valid_action_stats += torch.tensor(valid_action, dtype=torch.int)
valid_search_stats += torch.tensor(is_search, dtype=torch.int)
original_right_side = self._update_right_side(
original_right_side,
responses_ids,
)
meta_info['turns_stats'] = turns_stats.tolist()
meta_info['active_mask'] = active_mask.tolist()
meta_info['valid_action_stats'] = valid_action_stats.tolist()
meta_info['valid_search_stats'] = valid_search_stats.tolist()
print("ACTIVE_TRAJ_NUM:", active_num_list)
return self._compose_final_output(original_left_side, original_right_side, meta_info)
# 拼接origin_left+累积的模型输出和工具调用
def _compose_final_output(self, left_side: Dict,
right_side: Dict,
meta_info: Dict) -> Tuple[Dict, Dict]:
"""Compose final generation output."""
final_output = right_side.copy()
final_output['prompts'] = left_side['input_ids']
# Combine input IDs
final_output['input_ids'] = torch.cat([
left_side['input_ids'],
right_side['responses']
], dim=1)
# Create attention mask and position ids
final_output['attention_mask'] = torch.cat([
self.tensor_fn.create_attention_mask(left_side['input_ids']),
self.tensor_fn.create_attention_mask(final_output['responses'])
], dim=1)
final_output['info_mask'] = torch.cat([
self.tensor_fn.create_attention_mask(left_side['input_ids']),
self.tensor_fn.create_attention_mask(final_output['responses_with_info_mask'])
], dim=1)
final_output['position_ids'] = self.tensor_fn.create_position_ids(
final_output['attention_mask']
)
final_output = DataProto.from_dict(final_output)
final_output.meta_info.update(meta_info)
return final_output
咱们再回过来看一下search-r1的rl流程 ray_trainer.py
#########################################################################
# search-r1是直接在verl的trainer.ppo.ray_trainer.py的源码上进行扩展
# 添加了新的 generate_mannager用于生成agent traj(将在下一个代码框进行介绍)
# 我们先来看一下search-r1的整体训练流程
#########################################################################
def fit(self):
"""
The training loop of PPO.
The driver process only need to call the compute functions of the worker group through RPC to construct the PPO dataflow.
The light-weight advantage computation is done on the driver process.
"""
logger = self.logger
self.global_steps = 0
# perform validation before training
# currently, we only support validation using the reward_function.
if self.val_reward_fn is not None and self.config.trainer.get('val_before_train', True):
val_metrics = self._validate()
pprint(f'Initial validation metrics: {val_metrics}')
logger.log(data=val_metrics, step=self.global_steps)
if self.config.trainer.get('val_only', False):
return
# we start from step 1
self.global_steps += 1
#########################################################################
# 这里是新添加的agent traj轨迹数据的generate模块
# Agent config preparation
gen_config = GenerationConfig(
max_turns=self.config.max_turns,
max_start_length=self.config.data.max_start_length,
max_prompt_length=self.config.data.max_prompt_length,
max_response_length=self.config.data.max_response_length,
max_obs_length=self.config.data.max_obs_length,
num_gpus=self.config.trainer.n_gpus_per_node * self.config.trainer.nnodes,
no_think_rl=self.config.algorithm.no_think_rl,
search_url = self.config.retriever.url,
topk = self.config.retriever.topk,
)
generation_manager = LLMGenerationManager(
tokenizer=self.tokenizer,
actor_rollout_wg=self.actor_rollout_wg,
config=gen_config,
)
#########################################################################
#########################################################################
# 这里的loop还是verl的源码,循环每一个train epoch
# start training loop
for epoch in range(self.config.trainer.total_epochs):
for batch_dict in self.train_dataloader:
print(f'epoch {epoch}, step {self.global_steps}')
metrics = {}
timing_raw = {}
# 获取一个batch的训练数据 (bsz, prompt_length)
# 并进行repeat(grpo需要repeat)
# 注意:prompt是左填充的
batch: DataProto = DataProto.from_single_dict(batch_dict)
batch = batch.repeat(repeat_times=self.config.actor_rollout_ref.rollout.n_agent, interleave=True)
# pop those keys for generation
gen_batch = batch.pop(batch_keys=['input_ids', 'attention_mask', 'position_ids'])
####################
# original code here
with _timer('step', timing_raw):
if not self.config.do_search:
gen_batch_output = self.actor_rollout_wg.generate_sequences(gen_batch)
batch.non_tensor_batch['uid'] = np.array([str(uuid.uuid4()) for _ in range(len(batch.batch))],
dtype=object)
# repeat to align with repeated responses in rollout
batch = batch.repeat(repeat_times=self.config.actor_rollout_ref.rollout.n, interleave=True)
batch = batch.union(gen_batch_output)
#########################################################################
# 这里就是新的search-r1的训练流程了
#########################################################################
####################
# Below is aLL about agents - the "LLM + forloop"
####################
# with _timer('step', timing_raw):
else:
# 这里先做了一个左截断,仅保留靠右的max_start_length的prompt ids
first_input_ids = gen_batch.batch['input_ids'][:, -gen_config.max_start_length:].clone().long()
with _timer('gen', timing_raw):
generation_manager.timing_raw = timing_raw
# 这里生成数据 (bsz*rollout.n, prompt_length+response_length)
final_gen_batch_output = generation_manager.run_llm_loop(
gen_batch=gen_batch,
initial_input_ids=first_input_ids,
)
# final_gen_batch_output.batch.apply(lambda x: x.long(), inplace=True)
for key in final_gen_batch_output.batch.keys():
final_gen_batch_output.batch[key] = final_gen_batch_output.batch[key].long()
with torch.no_grad():
output = self.actor_rollout_wg.compute_log_prob(final_gen_batch_output)
final_gen_batch_output = final_gen_batch_output.union(output)
# batch.non_tensor_batch['uid'] = np.array([str(uuid.uuid4()) for _ in range(len(batch.batch))],
# dtype=object)
# 看来是输入的时候记录了每个q的index在non_tensor中
batch.non_tensor_batch['uid'] = batch.non_tensor_batch['index'].copy()
# repeat to align with repeated responses in rollout
batch = batch.repeat(repeat_times=self.config.actor_rollout_ref.rollout.n, interleave=True)
batch = batch.union(final_gen_batch_output)
####################
####################
# balance the number of valid tokens on each dp rank.
# Note that this breaks the order of data inside the batch.
# Please take care when you implement group based adv computation such as GRPO and rloo
self._balance_batch(batch, metrics=metrics)
# compute global_valid tokens
batch.meta_info['global_token_num'] = torch.sum(batch.batch['attention_mask'], dim=-1).tolist()
# batch.batch.apply(lambda x, key: x.long() if key != "old_log_probs" else x, inplace=True, key=True)
for key in batch.batch.keys():
if key != 'old_log_probs':
batch.batch[key] = batch.batch[key].long()
if self.use_reference_policy:
# compute reference log_prob
with _timer('ref', timing_raw):
ref_log_prob = self.ref_policy_wg.compute_ref_log_prob(batch)
batch = batch.union(ref_log_prob)
# compute values
if self.use_critic:
with _timer('values', timing_raw):
values = self.critic_wg.compute_values(batch)
batch = batch.union(values)
with _timer('adv', timing_raw):
# compute scores. Support both model and function-based.
# We first compute the scores using reward model. Then, we call reward_fn to combine
# the results from reward model and rule-based results.
if self.use_rm:
# we first compute reward model score
reward_tensor = self.rm_wg.compute_rm_score(batch)
batch = batch.union(reward_tensor)
# we combine with rule-based rm
reward_tensor = self.reward_fn(batch)
batch.batch['token_level_scores'] = reward_tensor
# compute rewards. apply_kl_penalty if available
if not self.config.actor_rollout_ref.actor.use_kl_loss:
batch, kl_metrics = apply_kl_penalty(batch,
kl_ctrl=self.kl_ctrl,
kl_penalty=self.config.algorithm.kl_penalty)
metrics.update(kl_metrics)
else:
batch.batch['token_level_rewards'] = batch.batch['token_level_scores']
# compute advantages, executed on the driver process
batch = compute_advantage(batch,
adv_estimator=self.config.algorithm.adv_estimator,
gamma=self.config.algorithm.gamma,
lam=self.config.algorithm.lam,
num_repeat=self.config.actor_rollout_ref.rollout.n)
# update critic
if self.use_critic:
with _timer('update_critic', timing_raw):
critic_output = self.critic_wg.update_critic(batch)
critic_output_metrics = reduce_metrics(critic_output.meta_info['metrics'])
metrics.update(critic_output_metrics)
# implement critic warmup
if self.config.trainer.critic_warmup <= self.global_steps:
# update actor
with _timer('update_actor', timing_raw):
if self.config.do_search and self.config.actor_rollout_ref.actor.state_masking:
batch, metrics = self._create_loss_mask(batch, metrics)
actor_output = self.actor_rollout_wg.update_actor(batch)
actor_output_metrics = reduce_metrics(actor_output.meta_info['metrics'])
metrics.update(actor_output_metrics)
# validate
if self.val_reward_fn is not None and self.config.trainer.test_freq > 0 and \
self.global_steps % self.config.trainer.test_freq == 0:
with _timer('testing', timing_raw):
val_metrics: dict = self._validate()
metrics.update(val_metrics)
if self.config.trainer.save_freq > 0 and \
self.global_steps % self.config.trainer.save_freq == 0:
with _timer('save_checkpoint', timing_raw):
self._save_checkpoint()
# collect metrics
metrics.update(compute_data_metrics(batch=batch, use_critic=self.use_critic))
metrics.update(compute_timing_metrics(batch=batch, timing_raw=timing_raw))
# TODO: make a canonical logger that supports various backend
logger.log(data=metrics, step=self.global_steps)
self.global_steps += 1
if self.global_steps >= self.total_training_steps:
# perform validation after training
if self.val_reward_fn is not None:
val_metrics = self._validate()
pprint(f'Final validation metrics: {val_metrics}')
logger.log(data=val_metrics, step=self.global_steps)
return
2. Tool use
待更新