背景
观看时长预测本质是一个回归问题,由于时长是连续值,跨度很大。又因为标签的分布显著影响回归任务的难度,适当的分布假设可以提高回归精度
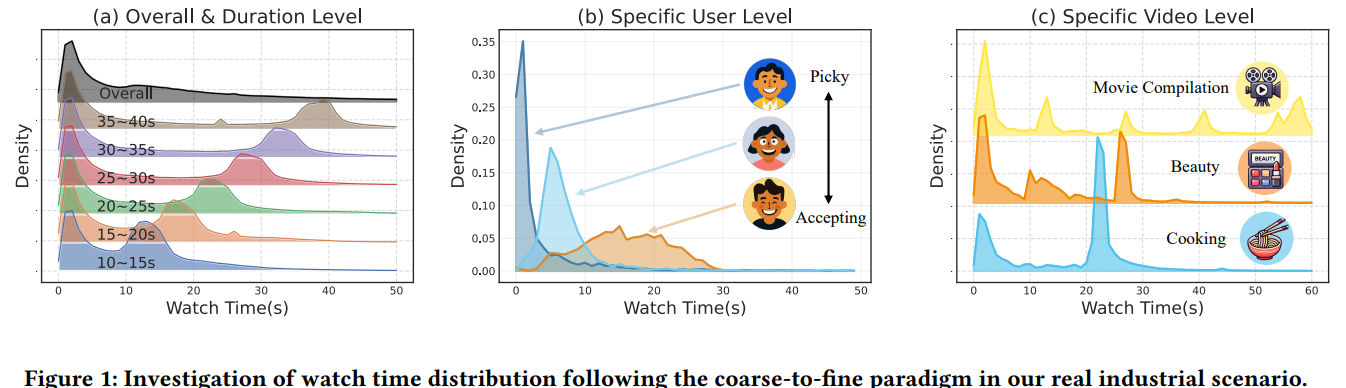
利用小红书工业数据,作者对观看时长进行了彻底的调查,结果如下:

-
总体来看,在 0 附近有明显的偏度,快滑占多数
-
在持续时间上有明显的双峰模式
-
特定用户的观看时间分布具有显著的多样性,一些用户喜欢快滑,一些用户有更大的耐心观看
-
不同视频的观看时长分布呈现出多峰现象,视频之间差异明显
本文研究短视频推荐中的观看时长预测问题。作者发现真实数据在多粒度层面呈现复杂分布特性,包括:
-
粗粒度:大量快速滑走(quick-skip)导致严重偏态,需要能够解决这种局部聚类现象的专门建模方法
-
细粒度:用户-视频的细粒度交互导致多样性和多峰分布,引入了跨粒度的不兼容性,从而放大了预测的复杂性,需要自适应架构来捕获异构特征
现有的观看时间预测方法通常通过两种主要方法来规避这些挑战。第一种方法是标签标准化,它不仅简化了标签分布以便于拟合,而且还提供了用户兴趣的公正反映。然而,这可能会导致绝对观看时间信息丢失,从而导致预测精度降低。第二种方法是任务转换,其中回归任务被转换为一系列分类。好处是每个子分类任务比整体回归问题更容易学习,而离散化和后续重建的过程不可避免地会引入额外的误差
因此作者建议基于合理的分布假设直接回归观看时间的绝对值,从而提高估计精度,协调不同粒度的分布差异。作者假设短视频观看时长服从指数-高斯混合分布(EGM),其中指数分量解决粗粒度分布偏度,高斯分量自适应捕获细粒度分布多样性。并设计了一个神经网络模型 EGMN 来学习该分布参数
方法
建模
以前的方法通常选择特定的度量(例如 MSE)来构建损失函数,然而这些指标依赖于对观看时间概率分布 \(p(t)\) 的过于简化的假设,忽略了跨多粒度级别的固有异质性,因此作者这里对 \(p(t)\) 进行概率建模
作为一个指数分布和 K-高斯分布的混合,EGM 的密度公式如下:
\(p(t) = \omega_0 f_{\text{exp}}(t|\lambda) + \sum_{k=1}^K \omega_k f_{\text{gauss}}(t|\mu_k, \sigma_k^2)\)
其中前者是速率参数为 \(\lambda\) 的指数分布的概率密度函数;后者是均值为 \(\mu\),方差为 \(\sigma^2\) 的高斯分布的概率密度函数
在粗粒度水平上,分布高度倾斜,指数分布非常适合对快速跳跃行为进行建模;在细粒度级别,分布变得更加复杂,而高斯混合分布在理论上已被建立为复杂多模态分布的统一一致估计量
EGMN

(1) 隐藏表示编码器
对于每个 user-item 对,先从多个来源收集特征(用户、视频、上下文),可用特征通过嵌入层进行处理,以创建特征向量 x。最初 x 被输入到特征编码器主干中以获得隐藏表示 h,该表示在 EGM 分布中的多个组件之间共享。其中主干网络可以使用任何适合推荐预测场景的特征编码主干进行实例化,例如 DCN、DIN、SENet、Transformer 等
(2) 混合参数生成器
隐藏表示随后被送往单独的分支中以估计每个分布分量的参数(上图右半部分)。对于 0 附近的峰值使用指数分布进行刻画,h 为基座模型的输出(比如 MoE 等),用 h 输入到一个 dense 网络得到指数分布的参数值;为了确保可识别性并防止分量模糊,对高斯函数的均值限制为超过等式 (4) 中指数分量的均值
最终某个样本的时长分布,由上述分布的加权和构成,权重由模型去学习一个 gate 网络得到
\(p(t|x) = \omega_0(x)f_{\text{exp}}(t|\lambda(x)) + \sum_{k=1}^K \omega_k(x)f_{\text{gauss}}(t|\mu_k(x), \sigma_k^2(x))\)
(3) 训练目标
作者使用三个损失函数的组合来优化 EGMN,分别是:
-
最大似然估计损失:鼓励模型给更接近的分布更高的权重
-
熵最大化损失:避免模型偷懒,只认真学习了其中一两个分布,作者对分布权重值计算了熵,希望熵越大越好(不同分布的权重尽量均匀,尽量都有学习到)
-
回归损失:确保模型在最终预估的时长均值和真实 label 的距离越近越好
最终的损失函数为这三种损失的加权和
(4) 推理过程
在推理过程中,EGMN 以完全端到端的方式在可能的观看时间范围内生成完整的条件概率分布。对于标准观看时间预测,我们简单地利用各个分布的均值的加权和作为时长的预估值
实验

可以看到 EGMN 在量化指标上取得了全面领先,并能拿到 0.6% 的线上时长收益

由于引入指数分布刻画 0 值附近的分布,模型对快滑样本的预估能力提升,能够更好的识别快滑样本(这对负反馈有很大的意义)。从图上可以看到,EGMN 能够更好的逼近真实分布,同时也能更加准确的建模用户个人习惯和视频特定参与模式的能力,并组合它们形成准确的联合预测分布
总结
EGMN 确实是理论上很好的工作,在输入特征完全的情况下,理论上可以拟合所有不同 user-item 对的多模态分布(不同 duration 区间、不同性格用户、不同视频种类),指数-混合高斯也是很好的拟合分布,但是我更想知道是不是真的实现了这种效果(结果里面只展示了不同 duration 区间内部的拟合情况,并没有展示不同性格用户、不同视频种类的拟合情况),尤其实在显示场景中数据极其不平衡的限制下真得能让高斯分量理想的学到他应该学的内容吗
文章摘自:https://www.cnblogs.com/mianmaner/p/19917165