1.LangChain是什么?
LangChain是⼀个⽤于开发—> 由(⼤型语⾔模型(LLMs)驱动的应⽤程序)的框架。
简单来说理解就是一个用开发开发大模型应用的开发框架,内部集成了很多功能,也有很多第三方生态扩展,用起来事半功倍,就把他想象成C#中的.NET Core框架,go中的Gin。
它简化了大语言模型应用程序生命周期的各个阶段:
1.开发阶段用LangChain提供的组件开发应用程序,利用第三方集成和模板快速启动。
2.生产化阶段使用LangSmith检查、监控和评估您的链,可以持续优化和部署。
3.部署阶段使用LangServe将任何链转化为API,核心作用就是帮你省去写 Web 框架代码,例如FastAPI 的样板代码的时间,直接把你的链包装成标准的 RESTful API。
什么叫我的链?
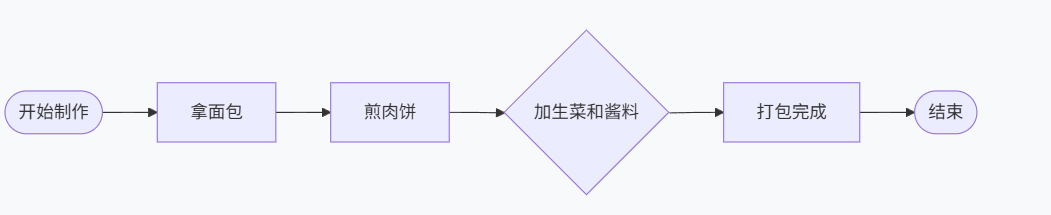
这是我最懵逼的概念,找了些资料,然后写一下demo,大概明白了一点,链是我的业务流程,链也是我实现业务流程的代码,不管是业务流程还是为流程实现的代码肯定是环环相扣的,所以称为链,例如我要用代码写一个制作汉堡的程序,他的流程是:
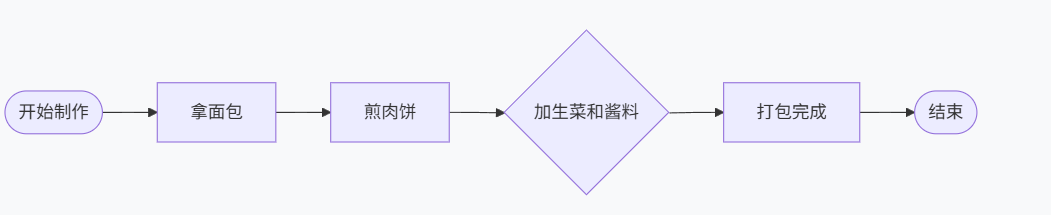
在 LangChain 里,把这一系列动作写成了一个对象或者代码,这个对象就是一条链。它代表了如何完成一个特定任务的完整逻辑。
2.LangChain有哪些功能?
把大模型比作一个拥有很多知识的天才,那LangChain就是他的助理。没LangChain时你问天才问题,他只能靠脑子里的旧知识瞎编,也没法帮你干活。有了LangChain:助理会先帮天才查资料连数据库,帮他记着刚才聊了啥(存记忆),甚至帮他把事办了(调工具、写代码)。其实对应着我们使用大模型作为驱动开发应用中的核心知识概念:
1.助理帮天才查资料 = RAG (检索增强生成)
2.帮他记着刚才聊了啥 = Memory (记忆)
3.帮他把事办了 = Agents智能体和Tools工具
在LangChain框架中,抽象出了这些功能,并定义称为核心模块
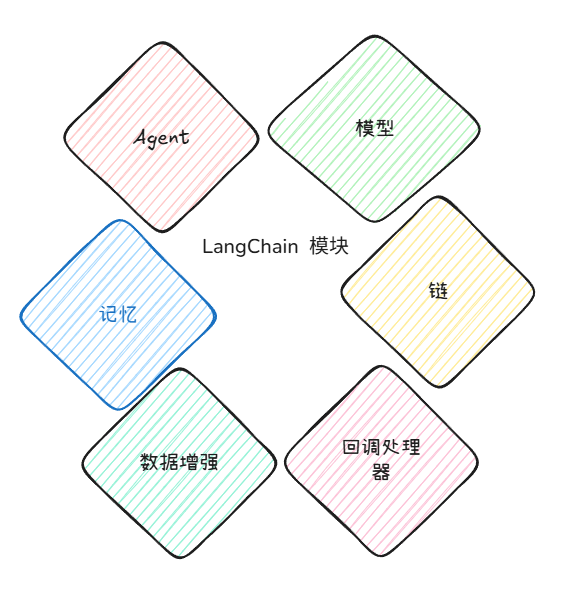
下面单独介绍
LLMs: 大语言模型 ChatModels: 一般基于 LLMs,但按对话结构重新封装 Prompt: 提示词模板 OutputParser: 解析输出
1.模块封装的功能
这些核心模块里面又封装了很多功能
1.模型I/O封装
| 术语 | 解释 | 作用 |
|---|---|---|
| LLMs(大语言模型) | 接话机器 | 最基础的模型接口。你给它一段文字,它接着给你补全下一段文字。它只管“续写”,不太在乎是不是在“聊天”。 |
| ChatModels(对话模型) | 聊天搭子 | 专门为了聊天优化的模型。它懂“系统设定”(比如:你是个猫娘)、“用户消息”和“助手回复”。现在的开发基本都用这个,比 LLMs 更聪明、更懂人话。 |
| Prompt(提示词模板) | 填空题试卷 | 你别每次都手写一大段话。你写好一个模板(比如:“请帮我翻译 {text}”),用的时候把{text}替换成具体内容就行。方便管理,还能复用。 |
| OutputParser(输出解析器) | 翻译官/质检员 | AI 有时候说话很随意(一大段纯文本)。这个模块负责把 AI 的回复“翻译”成程序能看懂的格式(比如 JSON、列表、数字),方便代码后续处理。 |
2.Retrieval 数据连接与向量检索封装
| 模块 | 技术解释 (它在干嘛?) |
|---|---|
| Document Loader | 负责从各种地方(PDF、网页、Notion、微信文章)把原始数据“搬运”进来,统一转换成 LangChain 能读懂的文档格式。 |
| Text Splitting | 大模型记性有限(Token 限制),不能一次读完整本书。切书员把长文档切成一个个小的“知识块”,方便模型消化。 |
| Embedding Model | 它把文字转换成计算机能理解的数字向量。就像图书管理员给每本书贴上“语义标签”(比如:这属于“科技类”、“情感类”),让机器理解文字的含义。 |
| Vector Store | 专门用来存储这些“数字向量”的数据库。它不像传统数据库那样存表格,而是存高维空间的点,方便快速查找相似的内容。 |
| Retriever | 当用户提问时,它负责去 Vector Store 里根据语义相似度,把最相关的几段资料找出来,递给大模型。 |
3.Agents代理封装
根据用户输入,自动规划执行步骤,自动选择每步需要的工具,最终完成用户指定的功能,包括:
| 术语 | 技术解释 |
|---|---|
| Tools(工具) | 最小功能单元。它是一个独立的函数或接口,专门用来做一件具体的事。比如“搜索网络”、“计算数学题”或“运行一段 Python 代码”。 |
| Toolkits(工具包) | 工具的集合。为了解决某个特定领域的复杂问题,LangChain 把一堆相关的 Tools 打包在一起。比如“数据库工具包”里就包含了“查表”、“执行 SQL”、“看表结构”等多个工具。 |
2.LangChain相关核心库
1.langchain-core 基础抽象和LangChain表达式语言
2.langchain-community 第三方集成。合作伙伴包(如langchain-openai、langchain-anthropic等),一些集成已经进一步拆分为自己的轻量级包,只依赖于langchain-core
3.langchain 构成应用程序认知架构的链、代理和检索策略
4.langgraph 通过将步骤建模为图中的边和节点,使用 LLMs 构建健壮且有状态的多参与者应用程序
5.langserve 将 LangChain 链部署为 REST API
6.LangSmith 一个开发者平台,可让您调试、测试、评估和监控LLM应用程序,并与LangChain无缝集成
3.LangChain基本使用
模块安装
# 安装指定版本的LangChain pip install langchain==0.3.7 -i https://pypi.tuna.tsinghua.edu.cn/simple pip install langchain-openai==0.2.3 -i https://pypi.tuna.tsinghua.edu.cn/simple
模型调用
1.通过LangChain的接口来调用OpenAI对话,依然使用阿里百炼的免费模型
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
import os
load_dotenv()
apiKey = os.getenv("api_key")
base_url = os.getenv("base_url")
model_name = "qwen-plus"
llm = ChatOpenAI(api_key=apiKey , base_url=base_url , model_name=model_name )
# 直接提供问题,并调用llm
response = llm.invoke("什么是遇事不决、量子力学?")
print(response)
print("=" * 50)
print(response.content)
2.多轮对话的封装
from dotenv import load_dotenv
import os
from langchain_openai import ChatOpenAI
from langchain.schema import (
AIMessage, # 等价于OpenAI接口中的assistant role AI 模型的回复消息
HumanMessage,# 等价于OpenAI接口中的user role 表示用户输入的消息
SystemMessage # 等价于OpenAI接口中的system role 系统级指令或背景设定
)
load_dotenv()
api_key=os.getenv("QW_KEY")
base_url=os.getenv("QW_URL")
model ='qwen-turbo'
llm = ChatOpenAI(api_key=api_key,base_url=base_url,model=model)
message =[
SystemMessage(content="你是各位老师的个人助理,你叫皮特"),
HumanMessage(content="我的名字叫小余"),
AIMessage(content="不好意思,暂时无法获得天气情况"),
HumanMessage(content="今天天气怎么样?")
]
response = llm.invoke(message)
print(response.content)
3.使用提示模板
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
# 1. 加载环境变量
# verbose=True 会在控制台打印加载了哪些变量,方便调试
load_dotenv(verbose=True)
# 2. 获取配置信息
api_key = os.getenv("QW_KEY")
base_url = os.getenv("QW_URL")
model = 'qwen-turbo'
# 3. 初始化大语言模型
llm = ChatOpenAI(
api_key=api_key,
base_url=base_url,
model=model
)
# 4. 定义提示词模板
# 这里定义了一个系统提示词来设定角色,以及一个用户输入占位符
prompt = ChatPromptTemplate.from_messages(messages=[
("system", "你是一个古诗词接龙的高手"),
("user", "{input}")
])
# 打印提示词模板对象信息(调试用)
print(prompt)
print("----" * 20)
# 5. 构建链 (Chain)
# 使用 "|" 操作符将提示词模板和模型连接起来
chain = prompt | llm
# 6. 调用模型并获取结果
# 传入具体的输入内容替换 {input}
response = chain.invoke({"input": "两岸猿声啼不住"})
# 打印模型生成的回复内容
print(response.content)
4.使用输出解释器
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import JsonOutputParser
# 1. 加载环境变量
load_dotenv(verbose=True)
# 2. 获取配置信息
api_key = os.getenv("QW_KEY")
base_url = os.getenv("QW_URL")
model_name = 'qwen-turbo'
# 3. 初始化大语言模型
llm = ChatOpenAI(
api_key=api_key,
base_url=base_url,
model=model_name
)
# 4. 定义提示词模板
prompt = ChatPromptTemplate.from_messages(messages=[
("system", "你是一个古诗词和文言文接龙的高手"),
("user", "{input}")
])
print("-" * 80)
# 5. 定义输出解析器
# JsonOutputParser 会尝试将模型的输出解析为 Python 字典或列表
output_parser = JsonOutputParser()
# 6. 构建链 (Chain)
# 流程:提示词 -> 模型 -> JSON 解析器
chain = prompt | llm | output_parser
# 7. 调用模型
# 在输入中明确指示模型以 JSON 格式返回 question 和 answer
input_text = "然侍卫之臣不懈于内, 问题用 question 回答用 answer 用 JSON 格式回复"
response = chain.invoke({"input": input_text})
# 8. 打印结果
print(response) # {'question': '然侍卫之臣不懈于内', 'answer': '忠志之士忘身于外者'}
5.使用LangChain存储向量到Chroma,我们调用在线网站的数据,然后进行向量化
import os
from langchain_community.document_loaders import WebBaseLoader
from dotenv import load_dotenv
import bs4
# 1. 替换嵌入模型和向量库导入
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_community.vectorstores import Chroma # 改这里
from langchain_text_splitters import RecursiveCharacterTextSplitter
load_dotenv()
def chroma_conn():
# 读取网页中的数据
loader = WebBaseLoader(
web_path="https://www.gov.cn/zhengce/zhengceku/202504/content_7021191.htm",
bs_kwargs=dict(parse_only=bs4.SoupStrainer(id="UCAP-CONTENT"))
)
docs = loader.load()
api_key = os.getenv("QW_KEY")
# 2. 创建向量模型 Chroma 本地运行
embeddings = DashScopeEmbeddings(
dashscope_api_key=api_key,
model='text-embedding-v2'
)
# 使用分割器分割文档
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
documents = text_splitter.split_documents(docs)[:10]
# 3. 向量存储Chroma
# persist_directory 指定数据保存的本地路径
vector = Chroma.from_documents(
documents=documents,
embedding=embeddings,
persist_directory="/Users/yuxl/3.Resources/Demo/llm/db/chroma"
)
# 如果指定了 persist_directory,建议调用 persist() 确保数据写入磁盘
vector.persist()
return vector
# 调用函数
db = chroma_conn()
print("数据已成功存入 Chroma 向量库!")
6.LangChain使用RAG,从上一步写入的向量库中检索数据
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain.chains import create_retrieval_chain
import os
from dotenv import load_dotenv
# 1. 导入 Chroma
from langchain_community.vectorstores import Chroma
from langchain_community.embeddings import DashScopeEmbeddings # 请确保这里使用的是与保存时相同的 Embedding
load_dotenv()
# --- 配置 LLM ---
api_key = os.getenv("QW_KEY")
base_url = os.getenv("QW_URL")
model = 'qwen-turbo'
llm = ChatOpenAI(api_key=api_key, base_url=base_url, model=model)
# --- 配置 Prompt ---
# {context}变量必须包含
prompt = ChatPromptTemplate.from_template("""仅根据提供的上下文回答以下问题:
<context>
{context}
</context>
问题: {input}""")
# --- 创建文档组合链 ---
document_chain = create_stuff_documents_chain(llm, prompt)
# --- 加载 Chroma 向量数据库并创建检索器 ---
api_key = os.getenv("QW_KEY")
embedding = DashScopeEmbeddings(
dashscope_api_key=api_key,
model='text-embedding-v2'
)
# 从磁盘加载数据库
vectorstore = Chroma(
persist_directory="/Users/yuxl/3.Resources/Demo/llm/db/chroma", # 这是你之前保存数据的路径
embedding_function=embedding
)
retriever = vectorstore.as_retriever(search_kwargs={"k": 3}) # 限制返回3个片段
# --- 创建检索链并执行 ---
retrieval_chain = create_retrieval_chain(retriever, document_chain)
response = retrieval_chain.invoke({"input": "宣传重点是什么"})
print(response["answer"])

3.总结
1.核心概念与定位
定义:LangChain 是一个简化 LLM 应用生命周期的开发框架,集成了丰富的第三方生态。
三大阶段:
1.开发:利用组件和模板快速构建应用。
2.生产化:使用 LangSmith 进行调试、监控和评估。
3.部署:使用 LangServe 将链转化为 REST API。
2.核心模块架构
LangChain 的关键功能模块:
1.Model I/O:包含 LLMs(文本补全)、ChatModels(对话优化)、Prompt(模板管理)和 OutputParser(格式化输出)。
2.Retrieval (RAG):涵盖 Document Loader(数据加载)、Text Splitting(文本切分)、Embedding(向量化)、Vector Store(向量存储)和 Retriever(检索)。
3.Agents:包含 Tools(工具)和 Toolkits(工具包),支持自动规划与执行。
3.关键代码示例
1.基础调用:通过 ChatOpenAI 接口调用通义千问模型。
2.多轮对话:使用 SystemMessage、HumanMessage 等管理上下文。
3,提示词模板:利用 ChatPromptTemplate 实现动态输入。
4.输出解析:使用 JsonOutputParser 将模型输出转换为结构化数据。
RAG 实战:
1.写入:爬取网页数据 -> 切分 -> 向量化 -> 存入 Chroma 数据库。
2.检索:从 Chroma 加载数据,结合 Prompt 实现基于知识库的问答。
文章摘自:https://www.cnblogs.com/yuxl01/p/19924060