介绍
(1) 发表:EMNLP’25
(2) 背景
高级 LLM 的正确翻译率较低,导致不同类型的执行错误。本文认为此问题的根本原因是 LLM 的预训练任务和代码翻译任务要求之间的差异。与自然语言不通,编程语言具有其他信息,这些信息表明了代码的执行状态,现有 LLM 仅学习代码的上下文语义,忽略了这种可执行性信息
(3) 贡献
本文提出了 Execoder,旨在通过利用可执行性表征(功能语义,语法结构和变量依赖性表示)来增强本任务中 LLM 的能力;此外还增强了广泛使用的代码翻译基准,产生了一个新基准 TransCoder-Test-X
方法
(1) 代码的可执行性表征
-
功能语义表征:在不同的编程语言中,具有相同功能的代码可能在形式上显示显着差异。Execoder 使用其功能的自然语言描述编码源代码的功能语义,以使源代码和目标代码的功能和目标代码的功能对齐
-
句法结构表征:与自然语言相比,编程语言具有清晰的句法结构和严格的语法规则。Execoder 编码了使用摘要索引(AST)的源代码的句法结构信息,使用 tree-sitter 来构建 AST,并进一步将 AST 编码为非结构化的文本
具体而言,Execoder 首先删除了 AST 中非叶子节点的内容,仅保留了叶子节点上的 Token。接下来将处理的 AST 视为图,并为每个节点分配一个数值索引,最后使用自然语言表示图表的节点信息和边信息。对于节点信息,描述每个节点的 Token 内容;对于边信息,描述每个节点的相邻节点。遵循此策略,源代码的句法结构信息最终被编码为自然语言的一部分
-
变量依赖性表征:在不同的编程语言中,由于程序员偏好和命名约定的变化,同一变量通常具有不同的语义。Execoder 编码使用数据流程图(DFG)的源代码的变量依赖信息,使用 tree-sitter 来构建 DFG,并与 AST 的处理类似转化为非结构化文本
(2) 微调数据集的构建
微调数据集 XLCoST-Instruct 通过公共跨语言基准数据集 XLCoST 构建, Execoder 从 C ++、Python 和 Java 三种编程语言中选择了并行数据,根据先前描述的信息,每个数据实例都会产生四个不同的代码表示。此外,由于 XLCoST 并非专门设计用于 LLMS 的指令进行微调,因此这里手动构造了用于翻译任务的说明
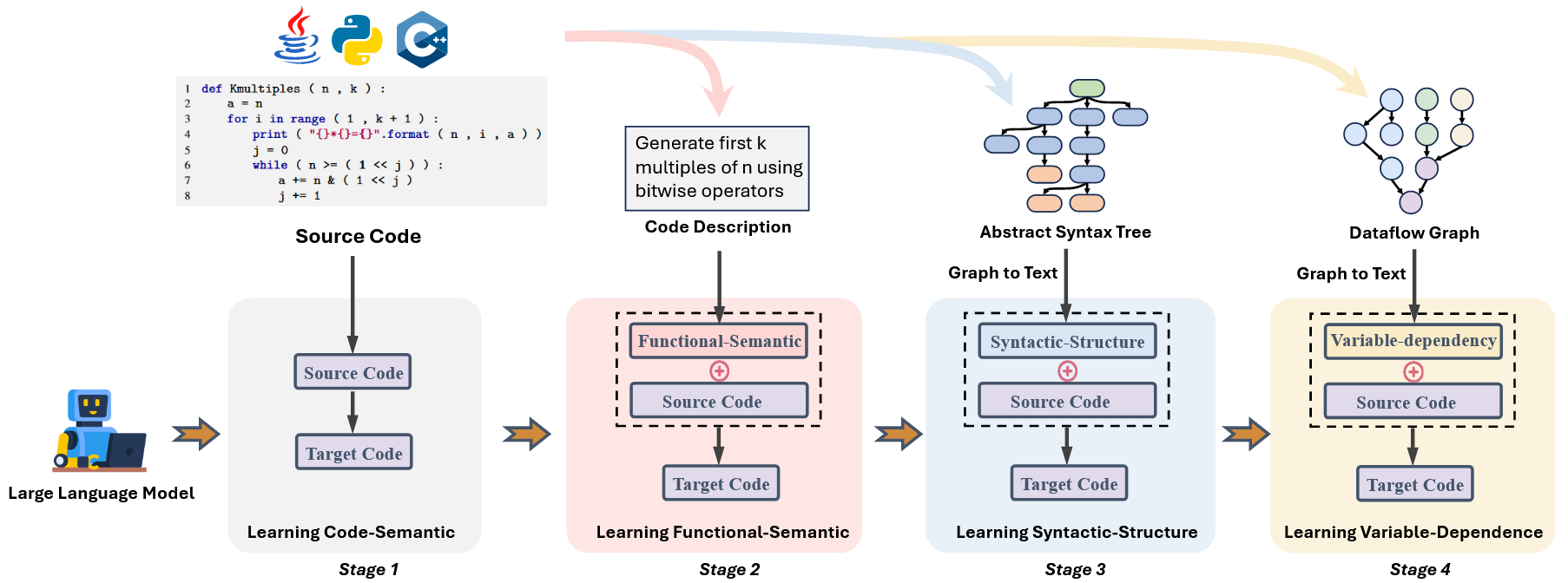
(3) 渐进性表征学习
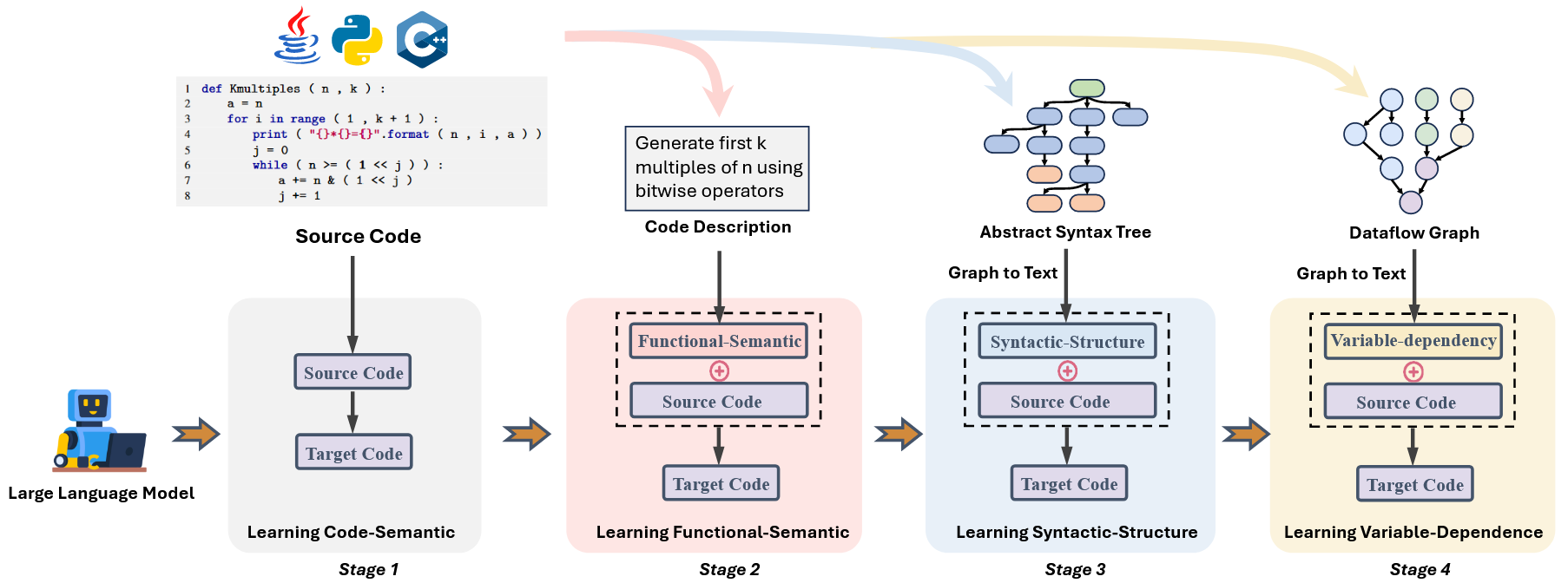
ExeCoder 设计了一个分阶段的微调策略,每个微调阶段都独立学习不同的可执行性表征,一旦一个阶段的微调过程收敛,就开始进行微调的下一个阶段
实验
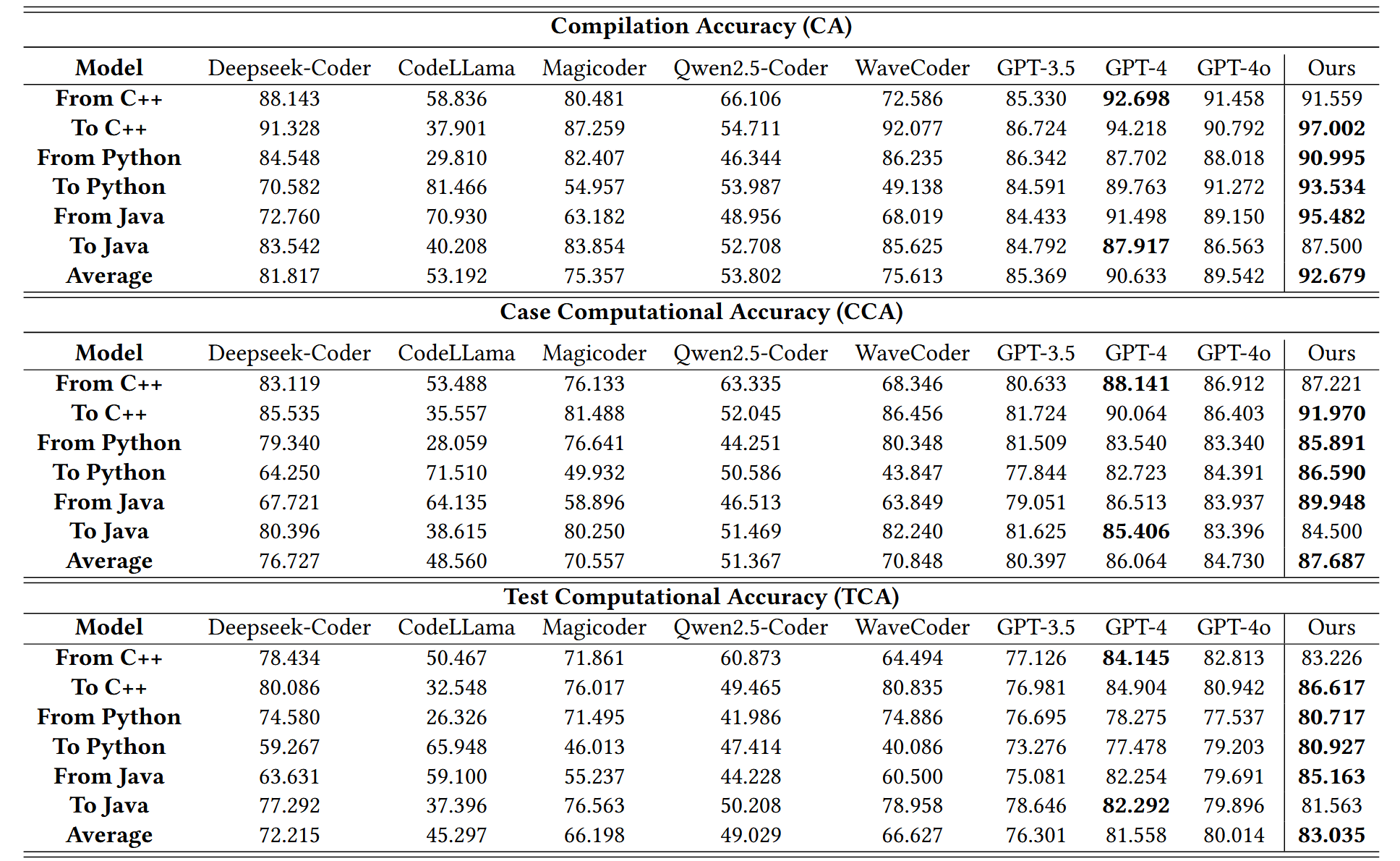
关于数据集:TransCoder-Test 数据集配备了预定义的单位测试模板,用于翻译对的一半以上,以评估生成的函数是否返回与给定输入相同的参考函数相同的输出。但是,这些单元测试模板建立了只能评估特定实现的固定参数传递方法或返回类型。当生成的函数不符合预定义的模版时就无法预期执行。因此,本工作增强了该数据集,增强的测试集称为 TransCoder-Test-X
可以看到,ExeCoder 在各种语言上的代码翻译性能基本超过目前最先进的 LLMS
总结
对齐了代码执行性表征和代码本身信息,让 LLM 同时学习到了更全面的代码信息,从而增强了代码翻译新能