论文阅读:Cooperative Memory Paging,用关键词书签解决大模型长对话记忆问题
论文标题:Cooperative Memory Paging with Keyword Bookmarks for Long-Horizon LLM Conversations
作者:Ziyang Liu
发表位置:arXiv preprint
arXiv 编号:arXiv:2604.12376v1
原文链接:https://arxiv.org/abs/2604.12376
主题:LLM 长对话记忆、上下文压缩、按需召回、关键词书签
核心问题:当大模型对话超过上下文窗口后,被移出的历史信息如何可靠找回来?
1. 论文要解决什么问题?
大语言模型的上下文窗口是有限的。
当对话较短时,模型可以直接看到前面的内容,因此能够利用用户刚刚说过的偏好、约束和背景信息。但如果对话持续很久,比如几百轮、跨越多个 session,早期内容就可能放不进上下文窗口。
在这种情况下,系统通常会采用几类方法:
- 直接截断:只保留最近的若干轮对话;
- 摘要压缩:把早期对话总结成短摘要;
- 外部检索:当模型需要历史信息时,从外部记忆中检索相关内容。
这些方法分别存在不同问题。
直接截断会永久丢失早期重要信息。比如用户早期说过“我对花生过敏”“预算不能超过 50 美元”“我只用 Rust 写项目”,这些信息在后续任务中仍然可能很关键。
摘要压缩可以节省上下文,但它是有损的。一旦某个细节没有被摘要保留下来,后续就无法恢复。
外部检索则面临另一个问题:模型需要知道自己缺少什么,才能主动搜索。但论文指出,大模型并不总能可靠意识到自己缺少上下文。缺少关键信息时,模型不一定表现得犹豫,反而可能流畅、自信地生成错误答案。
因此,这篇论文提出的核心思路是:
不要只依赖模型自己发现“我忘了什么”。
系统应该在上下文中保留轻量级线索,让模型知道旧信息在哪里,并可以按需召回。
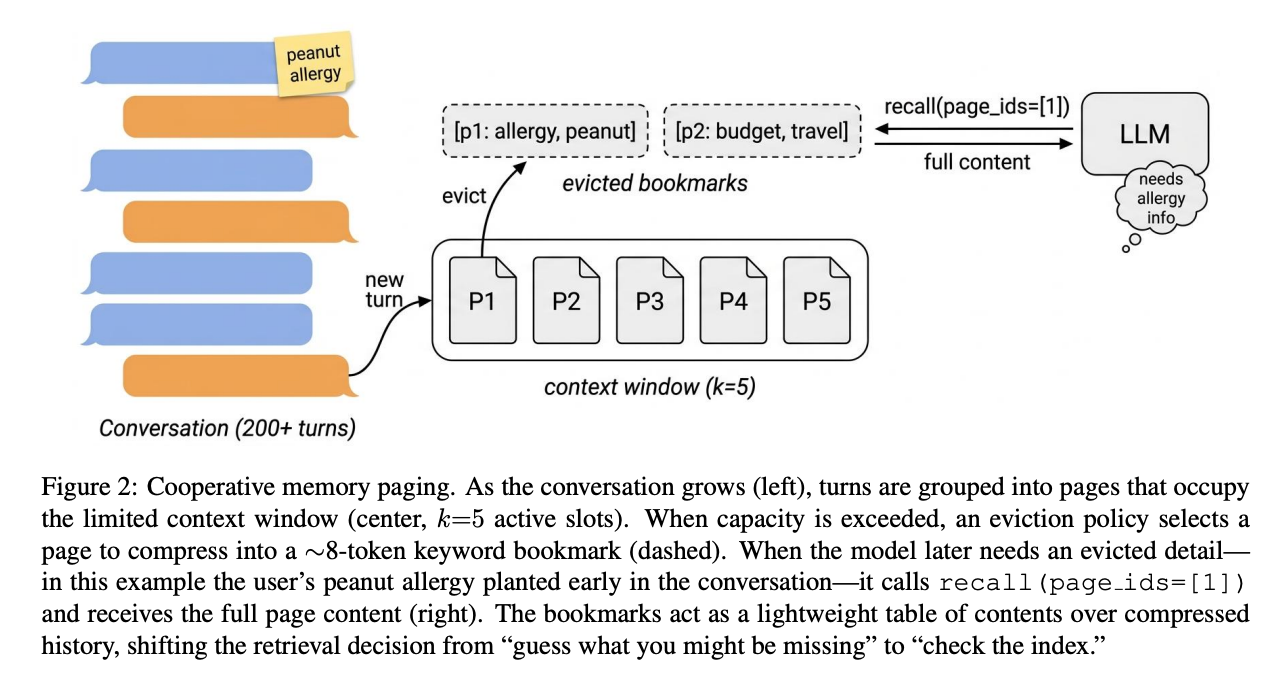
这个机制被称为 Cooperative Memory Paging,即“合作式记忆分页”。
2. 操作系统分页类比
论文将长对话记忆问题类比为操作系统中的虚拟内存分页问题。
在操作系统中,物理内存有限。当程序需要的内容超过物理内存容量时,系统会把一部分内存页换出到磁盘。之后如果程序需要这些内容,再把对应页面调回内存。
论文把 LLM 长对话中的记忆管理看作类似过程:
| 操作系统 | 长对话 LLM |
|---|---|
| 物理内存有限 | 上下文窗口有限 |
| 内存页 page | 一段历史对话 |
| 页面换出 | 旧对话从上下文中移除 |
| 页表 / 索引 | 关键词书签 |
| 缺页调入 | 调用recall()取回完整内容 |
不过,LLM 和普通程序有一个区别:LLM 可以根据系统提示和工具说明主动配合记忆管理。
如果系统告诉模型:
一些早期对话被压缩成了关键词书签。如果你需要具体细节,请调用recall(),不要猜测缺失信息。
那么模型就可以根据书签判断当前问题是否需要召回旧内容。
这也是论文中 cooperative 的含义:
系统不是完全透明地替模型管理记忆,也不是完全让模型自己搜索,而是在上下文中给出轻量级索引,让模型配合完成按需召回。
3. 方法:关键词书签 + recall 工具
论文提出的机制由几个部分组成。
当早期对话因为上下文窗口限制需要被移除时,系统不是直接丢掉它,也不是只留下摘要,而是把它替换成一个很短的关键词书签。
例如,早期某段对话中用户说过:
我对花生过敏,预算最好控制在 50 美元以内。
这段内容被移出上下文后,系统保留类似这样的书签:
[p3: allergy, peanut, budget]
其中:
- p3表示第 3 个 page;
- allergy, peanut, budget是从这一页对话中提取出的关键词;
- 完整对话内容仍然保存在外部存储中;
- 模型可以通过recall(page_ids=[3])把完整内容取回来。
该机制和摘要压缩的区别在于:
摘要是有损压缩,丢掉的细节无法恢复;
关键词书签是可逆索引,完整内容仍然可以通过工具召回。
论文中的完整流程包括:
- Segmentation:把长对话切成若干 page;
- Bookmark generation:为被换出的 page 生成关键词书签;
- Recall tool:给模型提供recall()工具;
- Recovery:模型需要细节时,调用工具取回完整 page。
这里的书签不是为了承载所有信息,而是作为“目录”使用。模型根据目录判断是否需要取回完整内容。
4. 为什么不能只靠模型自己发现记忆缺口?
论文第 2 节验证了一个自然想法:
如果模型缺少必要上下文,它生成答案时是否会更不确定?
如果会,是否可以用输出不确定性检测 memory fault?
作者使用 token-level NLL 衡量模型生成时的不确定性,并比较两种条件:
- 完整上下文:模型能看到所有关键信息;
- gist-compressed 上下文:关键信息被压缩或移除。
实验结果显示,这个思路不可靠。
在部分案例中,缺少关键信息时,模型的 NLL 反而更低,也就是模型更加自信。论文给出的解释是:如果模型不知道用户对花生过敏,它可以直接、流畅地推荐餐厅;如果它知道过敏信息,则需要谨慎措辞,输出反而更复杂。
这说明:
模型缺少上下文时,不一定会表现出“困难”或“不确定”。
它可能只是生成一个更普通、更自信、但错误的回答。
因此,论文认为不能只依赖被动 fault detection,而应该主动在上下文中告诉模型有哪些历史内容被压缩,以及如何召回这些内容。
5. LoCoMo benchmark 上的实验结果
论文使用 LoCoMo benchmark 评估方法。LoCoMo 是一个长时程对话记忆数据集,包含真实的多 session 对话,每个对话有 300 多轮。问题类型包括:
- single-hop
- temporal reasoning
- multi-hop
- open-domain
- unanswerable
论文比较了多种方法:
| 方法 | 说明 |
|---|---|
| Truncation | 只保留最近 20 轮 |
| BM25 Retrieval | 用 BM25 从旧 session 中检索 top-3 |
| Word-Overlap Retrieval | 用词重叠检索 top-3 |
| Search-tool baseline | 给模型自由搜索工具,后端用 BM25 |
| Full Context | 尽量放入完整上下文,但最多 60 轮 |
| Bookmark+Recall | 本文方法 |
在 GPT-4o-mini 上,主要结果如下:
| 方法 | 得分,1-5 |
|---|---|
| Truncation | 1.64 |
| BM25 Retrieval | 1.86 |
| Word-Overlap Retrieval | 1.88 |
| Search-tool baseline | 1.90 |
| Full Context | 2.02 |
| Bookmark+Recall | 2.18 |
结果显示,Bookmark+Recall 在这些方法中得分最高。
论文特别比较了 Bookmark+Recall 和 Search-tool baseline。两者都允许模型使用工具访问旧内容,但 Search-tool baseline 没有结构化书签,模型需要自己生成搜索查询;Bookmark+Recall 则在上下文中提供了关键词索引,使模型更容易判断应该召回哪段历史。
同时,论文也报告了 LoCoMo 上的 recall accuracy 为 59.4%,低于控制实验中的 90.9%。论文将其归因于真实对话中 session 数量更多,书签数量也更多,模型更难选择正确页面。
6. 跨模型验证
论文在多个模型上验证了 Bookmark+Recall 的效果,包括:
- GPT-4o-mini
- DeepSeek-v3.2
- Claude Haiku 4.5
- GLM-5
结果显示,Bookmark+Recall 在四个模型上都排名第一。
论文还使用四个不同 LLM judge 对答案进行独立评分:
- GPT-4o-mini
- DeepSeek-v3.2
- Claude Haiku 4.5
- GLM-5
在多评审实验中,Bookmark+Recall 在所有 judge 下都排名第一。论文报告的 paired bootstrap 检验结果显示,Bookmark+Recall 相对 BM25 的优势为p=0.017。
7. 分页策略:不是越“语义化”越好
论文第 5 节进一步研究了 page boundary 的设计问题:
对话应该如何切成 page?
作者比较了多种 page boundary 策略:
| 策略 | 含义 |
|---|---|
| fixed 5 | 每 5 轮切一页 |
| fixed 10 | 每 10 轮切一页 |
| fixed 20 | 每 20 轮切一页 |
| topic shift | 检测话题变化后切页 |
| exchange 5 | 每 5 个用户-助手 exchange 切页 |
实验结果显示,简单的 fixed 20 表现最好,而 topic shift 表现最差。
在 synthetic 数据上,结果如下:
| Boundary | Accuracy |
|---|---|
| topic shift | 56.7% |
| fixed 5 | 61.3% |
| fixed 10 | 77.0% |
| exchange 5 | 77.3% |
| fixed 20 | 96.7% |
论文解释说,topic shift 会把对话切得太碎,产生过多 bookmarks。书签数量越多,模型在召回时需要从更多候选项中选择正确页面,难度随之增加。
因此,论文给出的结论是:
在该任务设置中,page granularity 比边界语义一致性更重要。
粗粒度 fixed-size pages 可以减少 bookmark 数量,从而降低模型选择正确页面的难度。
8. 淘汰策略:为什么需要 eviction policy?
论文还研究了 eviction policy,即当上下文只能完整保留有限数量的 active pages 时,应该把哪一页换出成 bookmark。
这里需要区分两个概念:
- active pages:完整放在当前上下文中的 page;
- evicted pages / bookmarked pages:完整内容保存在外部,只在上下文中留下 bookmark 的 page。
即使所有历史内容都可以落盘保存,eviction policy 仍然重要。原因是:
外部存储可以保存所有历史内容,但上下文窗口只能完整容纳一部分内容。
因此系统仍然需要决定哪些 page 完整保留在上下文里,哪些 page 换成 bookmark。
论文的模拟器设定为k=5 active pages。当 active pages 数量超过 5 时,系统必须选择一些 page 换出。被换出的 page 不会丢失,而是变成 bookmark,完整内容保存在外部并可通过recall()取回。
论文比较了四种 eviction policy:
| 策略 | 含义 |
|---|---|
| FIFO | 最早进入的 page 先淘汰 |
| LRU | 最近最少使用的 page 先淘汰 |
| LFU | 使用频率最低的 page 先淘汰 |
| Belady oracle | 理想策略,知道未来访问情况 |
实验显示,Belady oracle 明显优于在线策略,说明 eviction policy 仍有优化空间。
同时,不同数据集上的最优在线策略不同:
- synthetic 数据中,FIFO 表现最好;
- LoCoMo 真实对话中,LFU / LRU 更好,FIFO 最差。
论文将这一现象解释为两种不同的对话拓扑:
- synthetic 对话通常是 forward-moving:话题不断向前推进,旧内容较少被重新访问;
- LoCoMo 真实对话是 revisit-heavy:朋友、工作、健康、计划等话题会反复出现。
因此,eviction policy 的效果依赖对话访问模式。
9. Bookmark bottleneck:知道要召回,但不知道召回哪一页
论文第 5.4 节指出,在需要访问 evicted page 的 probe 中,模型有 96.3% 的时候会触发recall()。
这说明“是否需要召回”这一问题在该机制下已经较为可靠。
但是,在已经触发 recall 的情况下,模型只有 56.6% 能选择正确页面。也就是说,主要瓶颈从:
模型是否知道要召回
转移到了:
模型是否知道应该召回哪一页
论文将这个问题称为 bookmark bottleneck。
例如,多个 bookmark 可能非常相似:
[p2: medical, doctor, appointment] [p5: medical, symptoms, appointment] [p8: health, doctor, schedule]
模型可能知道当前问题需要医疗相关历史,但难以判断应该召回p2、p5还是p8。
论文指出,错误集中出现在多个 bookmark 使用相似、泛化关键词的场景中。因此,bookmark 的区分度成为后续提升的关键。
10. 书签格式:短书签为什么更好?
论文第 6 节比较了不同 bookmark 格式:
| 格式 | 示例 | 准确率 | token 成本 |
|---|---|---|---|
| ID only | [p1] | 9.1% | 4 |
| Minimal | [p1:kw1,kw2] | 63.6% | 24 |
| Medium | `[p1:kw | “text…”]` | 54.5% |
| Structured | [p1:t=..;e=..] | 59.1% | 78 |
结果显示,minimal keyword bookmark 在准确率和 token 成本之间取得了最好平衡。
论文提出 information-gap hypothesis 来解释这个现象:
- 过短的 ID-only bookmark 缺少内容提示,模型不知道哪些旧内容可能相关;
- minimal keyword bookmark 提供了足够的相关性提示,同时保留了信息缺口,促使模型调用recall();
- 更长的 medium 或 structured bookmark 可能让模型误以为已经拥有足够信息,从而减少 recall 调用,导致回答错误。
因此,“短书签更好”并不意味着“信息越少越好”。更准确地说,论文主张的是:
书签应该短小,但关键词需要足够具体、足够有区分度。
它不能替代原文,而应提示模型在必要时召回原文。
这也解释了“短书签更好”和“模型有时不知道召回哪一页”之间的关系:
二者并不矛盾。前者强调不要把 bookmark 写成摘要,后者强调 bookmark 之间仍需要保持足够区分度。
11. 关键词特异性
论文进一步比较了 generic keyword 和 domain-specific keyword。
例如:
personal preferences
这种关键词较为泛化,模型难以判断它和当前问题的具体关系。
相比之下,更具体的关键词包括:
dietary preference, vegetarian programming language, Rust only
论文报告,将泛化标签替换成领域相关关键词后,准确率从 65.2% 提升到 90.9%,提升了 25.7 个百分点。
这说明 bookmark 生成时,关键词选择非常重要。论文强调,关键词应当优先选择能影响未来回答决策的词,而不是只选择抽象主题标签。
例如:
| 较弱关键词 | 更具体关键词 |
|---|---|
| preference | vegetarian, Rust only |
| budget | $50, under 50 dollars |
| medical | insulin, migraine, peanut allergy |
| schedule | Monday 2pm, unavailable 2-4pm |
| contact | Alice phone, Bob email |
12. Bookmark 生成策略
论文第 7 节比较了六种 bookmark 生成策略:
| 策略 | 说明 |
|---|---|
| random | 随机抽非停用词 |
| heuristic | 启发式抽取大写词、数字、日期等 |
| tfidf | 根据 TF-IDF 选择区分词 |
| llm-contextual | 每页调用一次 LLM,参考其他页摘要 |
| llm-batch | 一次 LLM 调用生成所有页关键词,并要求跨页不重叠 |
| hybrid | 先 heuristic,再让 LLM 给每页加一个区分性关键词 |
实验结果显示,并不是所有更复杂的策略都优于 heuristic。
在 synthetic 数据上:
| 策略 | E2E |
|---|---|
| random | 50.9 |
| heuristic | 72.3 |
| tfidf | 62.3 |
| llm-contextual | 66.0 |
| llm-batch | 68.6 |
| hybrid | 76.7 |
在 LoCoMo 数据上:
| 策略 | E2E |
|---|---|
| random | 38.8 |
| heuristic | 52.6 |
| tfidf | 47.5 |
| llm-contextual | 38.8 |
| llm-batch | 61.3 |
| hybrid | 45.0 |
论文指出:
- synthetic 数据中有明显表面锚点,如金额、人名、过敏原,因此 heuristic 已经能抽到较好的关键词,hybrid 进一步补充区分词后效果最好;
- LoCoMo 真实对话中,heuristic 容易抽到泛化或无效词,因此 llm-batch 通过全局生成非重叠关键词取得更好效果;
- TF-IDF 和 llm-contextual 的表现低于 heuristic,原因之一是它们可能降低 recall trigger rate,使模型更少调用recall()。
论文据此提出一个选择规则:
当 heuristic 提取的关键词本身信息量较高时,使用 hybrid;
当 heuristic 关键词信息量较低时,使用 llm-batch。
13. 论文指出的局限性
论文在讨论部分指出了若干限制。
第一,LoCoMo 上的绝对分数仍然不高。
Bookmark+Recall 虽然在多个方法中最高,但在 GPT-4o-mini 上为 2.18/5,说明真实长对话记忆问题仍然困难。
第二,部分控制实验规模较小。
例如 bookmark format ablation 使用 22 个 probe,因此相关结论仍需要更大规模实验验证。
第三,评价主要依赖 LLM judge。
论文使用了多 judge 验证和统计检验,但没有使用人类评测。
第四,topic shift boundary 使用的是简单词重叠方法。
如果使用更强的语义边界检测方法,例如 embedding similarity,结果可能发生变化。
第五,关键词提取仍然较为启发式。
论文指出,学习式关键词提取是后续方向之一,尤其是为了缓解 bookmark discrimination bottleneck。
第六,方法依赖模型配合调用recall()。
如果模型忽略 bookmark 并直接回答,被换出的信息仍然无法进入答案生成过程。
14. 论文给出的未来方向
论文提出了几个后续方向。
14.1 学习式关键词提取
未来可以训练或设计更强的关键词生成方法,生成更具有区分度、并且更能预测未来查询需求的 bookmark。
目标不是把 page 总结得更完整,而是生成更适合触发和定位 recall 的索引。
14.2 更好的在线淘汰策略
Belady oracle 明显优于 FIFO、LRU、LFU,说明在线 eviction policy 仍有优化空间。未来可以设计轻量级预测器,估计哪些 page 更可能被未来访问。
14.3 自适应 page sizing
不同对话片段可能需要不同 page 粒度。未来可以根据访问局部性和对话结构动态调整 page 大小。
14.4 层级化 bookmark indexing
当对话扩展到 100+ sessions 时,单层 bookmark 可能不够。论文指出,未来可能需要层级化索引结构,以减少模型在大量 bookmark 中选择的难度。
15. 总结
这篇论文提出了 Cooperative Memory Paging:当长对话超出上下文窗口后,系统将被换出的对话片段替换成极短的关键词书签,并允许模型通过recall()工具按需取回完整内容。
该方法的核心特点包括:
- 使用 bookmark 在上下文中保留轻量级索引;
- 将完整历史内容保存在外部存储中,实现可逆压缩;
- 让模型根据关键词书签主动判断是否需要召回;
- 通过 recall 工具恢复被换出的完整 page;
- 系统研究 page boundary、eviction policy、bookmark format 和 bookmark generation strategy 对效果的影响。
论文实验显示,在 LoCoMo 长对话记忆 benchmark 上,Bookmark+Recall 在多个 baseline 中取得最高得分,并在多个模型和多个 judge 下保持排名优势。
同时,论文指出当前主要瓶颈已经从“模型是否知道需要召回”转向“模型是否能从多个相似 bookmark 中选对页面”。因此,后续优化重点包括更有区分度的关键词生成、更好的召回时 reranking、更强的在线淘汰策略以及层级化记忆索引。
参考
- Ziyang Liu. Cooperative Memory Paging with Keyword Bookmarks for Long-Horizon LLM Conversations. arXiv:2604.12376v1. https://arxiv.org/abs/2604.12376
文章摘自:https://www.cnblogs.com/yourf4u1t/p/20104657