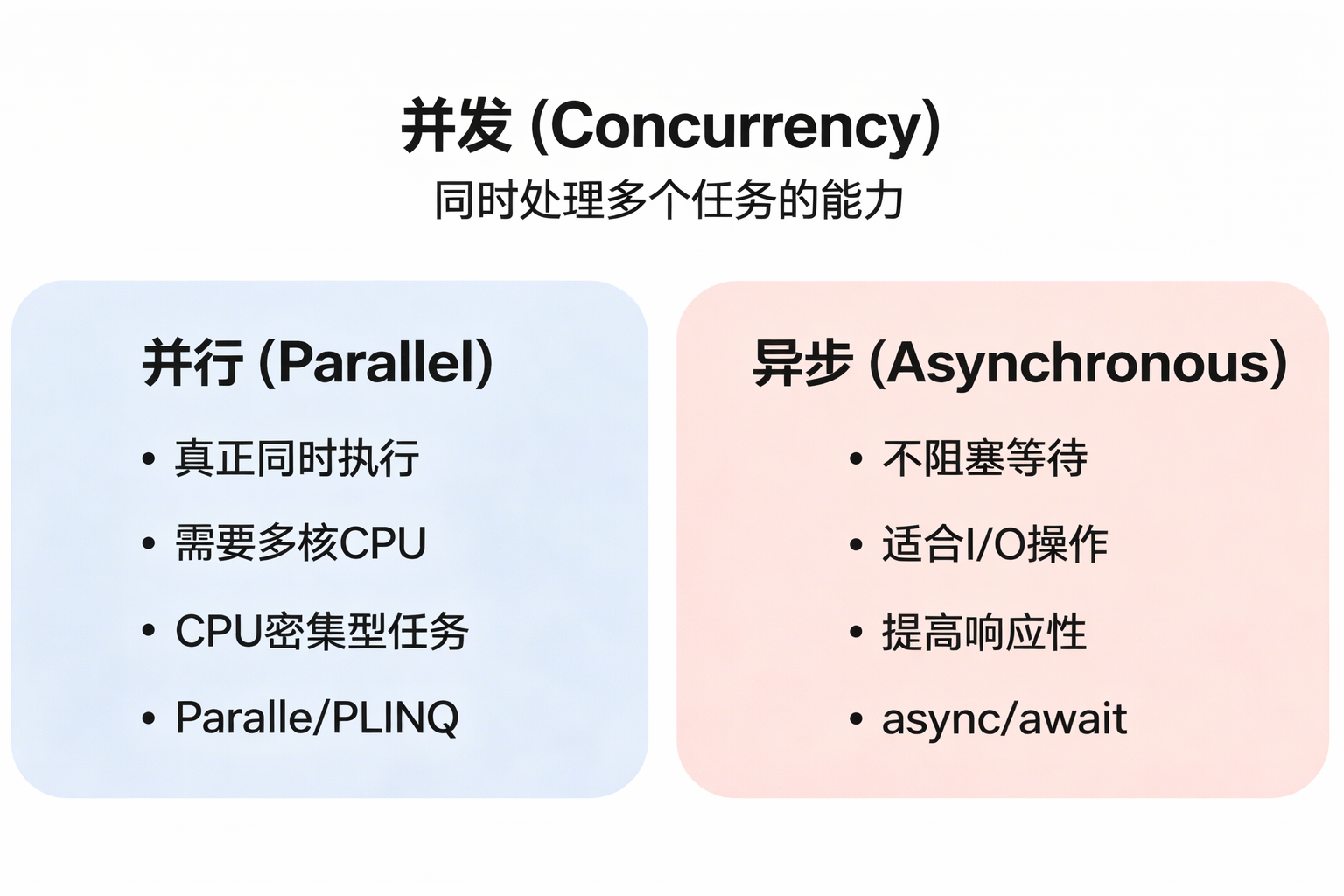
01. 并发编程全景图:为什么你的代码又慢又卡?
从一个真实的故事开始:
你刚写完一个 ASP.NET Core API,本地测试飞快。部署上线后,10 个并发用户就能把服务器 CPU 打满,响应时间从 100ms 飙到 5 秒。你懵了:代码没问题啊,为什么性能这么差?问题的根源,极大概率就藏在并发、并行、异步这三个概念里。搞懂它们,你的代码性能能提升 10-100 倍。
配套代码:本章所有代码示例都可以在
Overview项目中运行。
项目结构:
ConcurrencyDemo.cs– 并发示例(做饭场景)ParallelDemo.cs– 并行示例(多核计算)AsyncDemo.cs– 异步示例(模拟下载)TaskTypeDemo.cs– 任务类型识别CommonMistakesDemo.cs– 常见误区
🤔 第一个问题:为什么这三个概念这么容易混淆?
在讨论具体技术之前,我们先搞清楚一个根本问题:为什么并发、并行、异步这么容易混淆?
答案是:它们都在描述”同时做多件事”,但角度完全不同。
想象你在看一场足球比赛:
- 并发(Concurrency):同一台摄像机在快速切换不同的视角(球员、教练、观众),你感觉是”同时”看到了所有画面,但实际上是快速切换
- 并行(Parallelism):有 10 个摄像机真正同时拍摄不同的角度
- 异步(Asynchronous):你预约了比赛录像,不用一直盯着电视等,系统会在录制完成后通知你
这三个概念的共同点是都在处理”多任务”,区别在于:
- 并发关注逻辑结构(怎么组织代码)
- 并行关注物理执行(用几个 CPU 核心)
- 异步关注等待方式(阻塞还是非阻塞)
概念深度剖析:不只是定义,更要理解本质
1.1 并发(Concurrency):程序员的思维方式
官方定义听起来总是很抽象。让我换个方式说:
并发是你组织代码的方式,让程序能够”处理”多个任务,而不管这些任务是不是真的同时执行。
为什么需要并发?
现实世界本身就是并发的:
- 你的 Web 服务器要同时处理 1000 个请求
- 你的桌面程序要同时响应用户点击、更新界面、下载文件
- 你的游戏要同时处理物理计算、AI、渲染、音效
如果用单线程串行处理,用户体验会崩溃。
并发的本质:任务切换
关键洞察:单核 CPU 一次只能执行一条指令,但为什么你感觉电脑在”同时”运行 100 个程序?
答案是时间片轮转:
时间轴 →
[任务A][任务B][任务C][任务A][任务B][任务C]...
10ns 10ns 10ns 10ns 10ns 10ns
切换得足够快,人类就感觉不出来了(人眼识别延迟约 100ms)。
代码示例:并发做饭
这是一个经典的并发场景。注意观察线程 ID:
// 来自 ConcurrencyDemo.cs
private static async Task ConcurrentCookingAsync()
{
Console.WriteLine("开始做饭(并发模式)");
// 启动三个异步任务
var task1 = StirFryAsync(); // 炒菜
var task2 = MakeSoupAsync(); // 煮汤
var task3 = SteamRiceAsync(); // 蒸米饭
// 等待所有任务完成
await Task.WhenAll(task1, task2, task3);
Console.WriteLine("所有菜都做好了!");
}
运行后你会发现:所有任务可能都在同一个线程上完成!这就是并发的魔力。
运行示例:
dotnet run --project Overview观察线程 ID
深入思考:并发 ≠ 快
重要认知:并发不是为了”快”,而是为了不浪费时间。
做饭时,炒菜需要等油热(I/O 等待),这段时间你可以去切菜(任务切换)。并发让你充分利用等待时间,而不是傻站着。
1.2 并行(Parallelism):硬件的暴力美学
如果说并发是”巧妙地切换”,那并行就是”真刀真枪地同时干”。
并行的硬件基础
现代 CPU 都是多核的(4 核、8 核、16 核)。每个核心都是一个独立的计算单元,能真正同时执行指令。
CPU 核心 1: [计算质数] [计算质数] [计算质数]...
CPU 核心 2: [计算质数] [计算质数] [计算质数]...
CPU 核心 3: [计算质数] [计算质数] [计算质数]...
CPU 核心 4: [计算质数] [计算质数] [计算质数]...
什么时候需要并行?
只有一种情况:CPU 密集型任务。
什么是 CPU 密集型?就是不需要等待外部资源,纯靠 CPU 计算的任务:
- 图像处理(每个像素都要计算)
- 视频编码(海量数据压缩)
- 科学计算(模拟、求解方程)
- 大数据分析(筛选、聚合)
代码示例:并行计算质数
// 来自 ParallelDemo.cs
private static void ParallelProcessing()
{
Console.WriteLine($"CPU 核心数: {Environment.ProcessorCount}");
Console.WriteLine("开始并行计算阶乘...");
var numbers = Enumerable.Range(1, 8).ToArray();
// 使用 Parallel.ForEach 并行处理
Parallel.ForEach(numbers, number =>
{
var threadId = Environment.CurrentManagedThreadId;
var result = ComputeFactorial(number);
Console.WriteLine($" [Thread {threadId}] {number}! = {result}");
});
}
运行后你会看到:多个不同的线程 ID,它们在真正同时计算!
运行示例:观察线程 ID 的变化,理解”真正同时”的含义
并行的陷阱:Amdahl 定律
残酷的现实:并行不是 4 核就快 4 倍。
原因有三:
- 线程创建开销:创建和销毁线程需要时间
- 上下文切换:CPU 在线程间切换需要保存/恢复状态
- 数据同步:多线程访问共享数据需要加锁(后面章节详解)
实际加速比通常是 2.5-3.5 倍,已经很不错了。
1.3 异步(Asynchronous):不傻等的艺术
这是最容易被误解的概念,也是现代 .NET 开发的核心。
为什么需要异步?
想象你在餐厅点餐:
同步方式(阻塞):
你:我要一份牛排
服务员:好的(站在厨房门口等 20 分钟)
你:……(也在桌子旁干等)
[20 分钟后]
服务员:您的牛排好了
异步方式(非阻塞):
你:我要一份牛排
服务员:好的,请稍等,牛排好了我叫您(转身去服务其他客人)
你:……(可以刷手机、聊天)
[20 分钟后]
服务员:先生,您的牛排好了
异步的核心:在等待期间,去做其他事情。
异步的硬件基础:I/O 完成端口
很多人不知道,异步操作在等待期间不占用线程!
当你调用 await httpClient.GetAsync() 时:
- 发起网络请求(占用线程,非常快,几微秒)
- 线程立即释放,去处理其他请求
- 等待网络响应(不占用线程,这是最耗时的阶段)
- 网卡收到数据后,触发硬件中断
- 操作系统通知 .NET 运行时
- .NET 从线程池取一个线程继续执行后续代码
关键点:在步骤 3(等待响应)期间,没有线程在傻等!
代码示例:异步下载
// 来自 AsyncDemo.cs
private static async Task SimulateDownloadAsync(string fileName, int delayMs)
{
var startThread = Environment.CurrentManagedThreadId;
Console.WriteLine($" [Thread {startThread}] 开始下载 {fileName}...");
// 模拟异步 I/O 操作(等待期间线程被释放)
await Task.Delay(delayMs);
var endThread = Environment.CurrentManagedThreadId;
Console.WriteLine($" [Thread {endThread}] {fileName} 下载完成 ");
// 注意:控制台应用中,await 后可能在同一线程恢复(线程池优化)
// 在 ASP.NET Core 中,通常会在不同线程恢复
if (startThread != endThread)
{
Console.WriteLine($" → 线程切换:{startThread} → {endThread}");
}
else
{
Console.WriteLine($" → 线程复用:线程池优化,复用了 Thread {startThread}");
}
}
运行后你会发现:
- 控制台应用:可能在同一线程完成(线程池优化)
- ASP.NET Core:通常在不同线程恢复(有 SynchronizationContext)
- 关键点:无论是否切换线程,等待期间线程都被释放了!
运行示例:观察线程行为
异步的威力:ASP.NET Core 案例
假设你有 100 个线程池线程(默认值),每个请求需要调用数据库(耗时 50ms):
同步方式:
- 100 个线程同时处理 100 个请求
- 每个线程阻塞 50ms 等待数据库
- 第 101 个请求被拒绝(没有空闲线程)
异步方式:
- 100 个线程发起 100 个数据库请求,立即释放
- 这 100 个线程可以继续处理新的请求
- 理论上可以同时处理数千个请求
性能提升:10-100 倍!
1.4 三者关系:一个统一的视角

核心洞察:
- 并发是概念,并行和异步是实现方式
- 并行解决计算瓶颈,异步解决等待浪费
- 它们可以组合使用(比如并行下载 100 个文件)
.NET 并发技术栈:为什么设计成这样?
很多文章只告诉你”有哪些工具”,但不告诉你”为什么要有这些工具”。让我们换个角度。
2.1 演进史:从 Thread 到 async/await
阶段 1:原始时代 – Thread(.NET 1.0-3.5)
// 2002 年,你是这样写并发代码的
var thread = new Thread(() =>
{
// 下载文件
var data = DownloadFile(url);
});
thread.Start();
thread.Join(); // 阻塞等待
问题:
- 创建线程开销大(1MB+ 栈空间)
- 手动管理生命周期(忘记 Join 导致内存泄漏)
- 1000 个并发 = 1000 个线程 = 1GB+ 内存
阶段 2:线程池时代 – ThreadPool(.NET 2.0+)
// 2005 年,微软引入线程池
ThreadPool.QueueUserWorkItem(_ =>
{
var data = DownloadFile(url);
});
改进:
- 复用线程,避免重复创建
- 自动管理线程数量
问题:
- 回调地狱(Callback Hell)
- 错误处理复杂
- 无法获取返回值
阶段 3:任务时代 – Task(.NET 4.0)
// 2010 年,Task 横空出世
var task = Task.Run(() => DownloadFile(url));
var data = task.Result; // 可以获取返回值了!
改进:
- 统一的异步模型
- 支持组合(Task.WhenAll)
- 异常传播机制
问题:
- 仍然是回调风格
- 代码可读性差
阶段 4:现代异步 – async/await(.NET 4.5+)
// 2012 年,async/await 改变世界
var data = await DownloadFileAsync(url);
// 看起来像同步代码,实际是异步执行!
革命性改进:
- 同步风格的异步代码(编译器状态机)
- 自动异常传播
- 完美的组合性
这就是为什么现在推荐 async/await!
2.2 技术栈全景:每一层的存在意义

关键洞察:
- 越往上越”业务化”,越往下越”系统化”
- 大多数开发者只需要关注异步编程层和并行编程层
- 同步原语层是”必要之恶”(后续章节详解)
场景识别:如何做出正确的技术选择?
这是最实用的部分。很多开发者不是不知道工具,而是不知道什么时候用哪个工具。
3.1 核心判断标准:任务在等什么?
一个简单的问题就能决定一切:你的代码在等什么?
任务在等什么?
│
├─ 等 CPU 计算 ────→ CPU 密集型 ────→ 使用并行(Parallel/PLINQ)
│
│
├─ 等 I/O 完成 ────→ I/O 密集型 ────→ 使用异步(async/await)
│
│
└─ 两者都有 ───────→ 混合型 ────────→ 组合使用
3.2 CPU 密集型:如何识别?
特征(满足任意一条):
- CPU 使用率 > 70%
- 代码里有大量循环、递归、数学运算
- 执行时间与 CPU 主频成反比
典型场景:
// 错误:用异步处理 CPU 密集任务
public async Task<int[]> FindPrimesAsync(int max)
{
return await Task.Run(() => // 这里的 Task.Run 是对的!
{
return Enumerable.Range(2, max)
.Where(IsPrime) // CPU 密集计算
.ToArray();
});
}
正确做法(来自 TaskTypeDemo.cs):
// 正确:使用 PLINQ
private static void DemonstrateCpuBoundTask()
{
var data = Enumerable.Range(1, 1_000_000).ToArray();
// 使用 PLINQ 并行处理
var primes = data
.AsParallel() // 魔法在这里!
.Where(IsPrime)
.ToArray();
Console.WriteLine($"找到 {primes.Length} 个质数");
}
性能提升:4 核 CPU 上约 2.5-3.5 倍
运行示例:
dotnet run --project Overview观察耗时
3.3 I/O 密集型:最容易踩坑的地方
特征(满足任意一条):
- CPU 使用率 < 30%
- 代码在等网络、磁盘、数据库
- 执行时间与网络延迟成正比
常见错误(90% 的性能问题都是这个):
// 错误:用 Task.Run 包装 I/O 操作
public async Task<string> GetDataAsync()
{
return await Task.Run(async () => // 画蛇添足!
{
using var client = new HttpClient();
return await client.GetStringAsync(url); // I/O 操作
});
}
为什么错?
HttpClient.GetStringAsync已经是异步的(不占用线程)Task.Run额外占用一个线程池线程- 这个线程在干什么?傻等网络响应!
正确做法:
// 正确:直接 await
public async Task<string> GetDataAsync()
{
using var client = new HttpClient();
return await client.GetStringAsync(url);
// 等待期间,线程被释放去处理其他请求
}
运行示例:查看
CommonMistakesDemo.cs的性能对比
性能影响:在高并发下,吞吐量差异可达 10-100 倍!
这个问题非常的典型,大部分人会在这里踩坑,后面的章节会着重讲解原因
3.4 混合型任务:组合的艺术
真实世界的任务往往是混合的。关键是识别每个步骤的类型。
案例:批量下载并处理图片
// 来自 TaskTypeDemo.cs(改进版)
public async Task ProcessImagesAsync(string[] urls)
{
// 步骤 1:I/O 密集 - 并发下载(异步)
var downloadTasks = urls.Select(url => DownloadImageAsync(url));
var images = await Task.WhenAll(downloadTasks);
// 步骤 2:CPU 密集 - 并行处理(Parallel)
var processed = new ConcurrentBag<Image>();
Parallel.ForEach(images, image =>
{
var result = ApplyFilters(image); // CPU 密集
processed.Add(result);
});
// 步骤 3:I/O 密集 - 并发保存(异步)
var saveTasks = processed.Select(img => SaveImageAsync(img));
await Task.WhenAll(saveTasks);
}
关键洞察:
- I/O 步骤用
async/await(等待期间不占用线程) - CPU 步骤用
Parallel(充分利用多核) - 不要混淆:I/O 不需要
Task.Run
实战案例:从 100ms 到 10ms 的优化之旅
让我分享一个真实的优化案例,展示如何识别和解决性能问题。
案例背景
一个电商 API,用户查询订单详情:
- 查询数据库(50ms)
- 调用物流 API(100ms)
- 调用支付 API(80ms)
初始性能:总耗时 230ms
第一版:同步阻塞(新手代码)
// 性能:230ms,吞吐量:100 QPS
public IActionResult GetOrder(int orderId)
{
// 阻塞等待数据库
var order = _db.Orders.FirstOrDefault(o => o.Id == orderId);
// 阻塞等待物流 API
var logistics = _logisticsClient.GetAsync(order.TrackingNo).Result;
// 阻塞等待支付 API
var payment = _paymentClient.GetAsync(order.PaymentId).Result;
return Ok(new { order, logistics, payment });
}
问题:3 个线程在干什么?傻等 I/O!
第二版:异步串行(初级优化)
// ️ 性能:230ms,吞吐量:10000 QPS
public async Task<IActionResult> GetOrderAsync(int orderId)
{
// 异步查询数据库
var order = await _db.Orders.FirstOrDefaultAsync(o => o.Id == orderId);
// 异步调用物流 API
var logistics = await _logisticsClient.GetAsync(order.TrackingNo);
// 异步调用支付 API
var payment = await _paymentClient.GetAsync(order.PaymentId);
return Ok(new { order, logistics, payment });
}
改进:
- 吞吐量提升 100 倍(线程不再阻塞)
- 但响应时间没变(仍然是串行)
第三版:异步并发(高级优化)
// 性能:100ms,吞吐量:10000 QPS
public async Task<IActionResult> GetOrderAsync(int orderId)
{
// 异步查询数据库
var order = await _db.Orders.FirstOrDefaultAsync(o => o.Id == orderId);
// 并发调用两个 API(它们互不依赖)
var logisticsTask = _logisticsClient.GetAsync(order.TrackingNo);
var paymentTask = _paymentClient.GetAsync(order.PaymentId);
// 等待两个任务都完成
await Task.WhenAll(logisticsTask, paymentTask);
return Ok(new
{
order,
logistics = logisticsTask.Result,
payment = paymentTask.Result
});
}
最终结果:
- 响应时间:230ms → 100ms(提升 2.3 倍)
- 吞吐量:100 QPS → 10000 QPS(提升 100 倍)
关键洞察:
- 物流和支付 API 可以并发调用(它们互不依赖)
- 100ms 是最慢的那个 API 的耗时
️ 常见误区:为什么 90% 的开发者会犯这些错?
误区 1:”async 就是多线程”
错误认知:加了 async 关键字就会创建新线程。
真相:async 只是编译器的语法糖,生成一个状态机。
证明:
public async Task TestAsync()
{
Console.WriteLine($"Before: {Thread.CurrentThread.ManagedThreadId}");
await Task.Delay(1000); // 异步等待
Console.WriteLine($"After: {Thread.CurrentThread.ManagedThreadId}");
}
运行结果:线程 ID 可能相同!
为什么会有这个误区?
- 因为
Task.Run确实会用线程池线程 - 但
await本身不会创建线程
误区 2:”Task.Run 能提升性能”
错误认知:把任何操作包装在 Task.Run 里就能变快。
真相(来自 CommonMistakesDemo.cs):
// 错误:浪费线程
var data = await Task.Run(async () =>
{
await Task.Delay(500); // I/O 操作
return "Data";
});
// 正确:直接 await
await Task.Delay(500);
var data = "Data";
为什么错?
Task.Delay已经是异步的(不占用线程)Task.Run额外占用一个线程池线程- 这个线程在
await Task.Delay期间还是被释放了 - 结果:多余的线程调度开销,性能反而降低
正确使用 Task.Run:仅用于 CPU 密集型任务!
误区 3:”Task 就是线程”
错误认知:创建 1000 个 Task 就会创建 1000 个线程。
真相:
- I/O 密集型 Task:在等待期间不占用线程(使用 I/O 完成端口)
- CPU 密集型 Task:使用线程池线程(通常 < 100 个)
验证代码:
// 创建 10000 个 I/O 密集型 Task
var tasks = Enumerable.Range(1, 10000)
.Select(_ => Task.Delay(5000))
.ToArray();
await Task.WhenAll(tasks);
// 线程池线程数:几乎没增加!
为什么会有这个误区?
- 因为在其他语言(如 Go、Erlang)中,一个任务确实对应一个”协程”
- 但 .NET 的 Task 是异步操作的抽象,不等于线程
速查表:30 秒做出正确选择
| 场景 | 特征 | 推荐技术 | 避免 | 性能提升 |
|---|---|---|---|---|
| Web API 调用 | 等待网络响应 | async/await + HttpClient |
Task.Run |
10-100x |
| 数据库查询 | 等待数据库响应 | async/await + EF Core Async |
.Result / .Wait() |
10-100x |
| 文件读写 | 等待磁盘 I/O | async/await + Stream |
同步 I/O | 5-20x |
| 图像处理 | CPU 计算 | Parallel.ForEach |
async/await |
2.5-3.5x |
| 视频编码 | CPU 计算 | Parallel + Task.Run |
单线程 | 2.5-3.5x |
| 数据分析 | CPU 计算 | PLINQ |
普通 LINQ | 2.5-3.5x |
| 批量下载 | I/O 密集 | Task.WhenAll + async/await |
串行下载 | 文件数倍 |
| 混合任务 | I/O + CPU | 组合使用 | 全用异步或全用并行 | 5-20x |
记住一个原则:
- 等 I/O → async/await
- 等 CPU → Parallel/PLINQ
本章小结:从困惑到清晰
核心洞察
-
并发、并行、异步的本质:
- 并发 = 组织代码的方式(逻辑层面)
- 并行 = 利用多核硬件(物理层面)
- 异步 = 不浪费等待时间(执行模式)
-
技术选择的黄金法则:
- I/O 密集 →
async/await(释放线程) - CPU 密集 →
Parallel(利用多核) - 混合型 → 组合使用
- I/O 密集 →
-
常见误区的根源:
- Task ≠ 线程
- async ≠ 多线程
- Task.Run ≠ 性能提升
-
性能优化的真相:
- 不是”让代码跑得快”
- 而是”不浪费资源”
思考题
问题 1:为什么异步能提升吞吐量,但不一定能降低响应时间?
答案解析
吞吐量 vs 响应时间:
- 吞吐量(Throughput)= 单位时间处理的请求数
- 响应时间(Latency)= 单个请求的完成时间
异步的核心是释放线程,让一个线程能处理更多请求:
- 同步:100 个线程 → 处理 100 个请求
- 异步:100 个线程 → 处理 10000 个请求(线程被复用)
但单个请求的耗时(如网络延迟 100ms)不会变。
要降低响应时间,需要:
- 并发执行(Task.WhenAll)
- 缓存
- 更快的网络/数据库
问题 2:下面的代码有什么问题?
public async Task ProcessDataAsync()
{
var data = await DownloadDataAsync(); // I/O
var result = await Task.Run(() =>
{
return data.Select(x => x * 2).ToList(); // CPU?
});
}
答案解析
问题:
Select操作不是 CPU 密集型,不需要Task.Run。改进:
public async Task ProcessDataAsync() { var data = await DownloadDataAsync(); // I/O var result = data.Select(x => x * 2).ToList(); // 同步即可 }什么时候需要 Task.Run?
- 循环次数 > 10000
- 单次循环耗时 > 1ms
- 总耗时 > 100ms
简单的 LINQ 操作不需要!
问题 3:为什么 ASP.NET Core 强烈建议全部使用异步?
答案解析
Web 应用的特点:
- 99% 的时间在等 I/O(数据库、缓存、外部 API)
- 请求数量大(可能同时有数千个请求)
同步的问题:
- 100 个线程 → 只能处理 100 个并发请求
- 第 101 个请求被拒绝(HTTP 503)
异步的优势:
- 100 个线程 → 可以处理 10000+ 个并发请求
- 吞吐量提升 100 倍
实际数据(微软官方测试):
- 同步:1000 并发 → CPU 100%,响应时间 5s
- 异步:1000 并发 → CPU 20%,响应时间 100ms
下一步
在下一章《02. 线程的底层:Thread、ThreadPool 与 Task 的关系》中,我们将:
- 用代码实验验证 Thread 的真实成本(内存、上下文切换)
- 观察 ThreadPool 的工作窃取算法(为什么比你手动管理更高效)
- 理解 Task 如何在底层调度(状态机、线程复用)
- 回答为什么现代 .NET 推荐 Task 而不是 Thread
预告一个震撼的实验:
// 创建 10000 个 Thread:内存占用 10GB+,系统崩溃
// 创建 10000 个 Task:内存占用 < 100MB,完美运行
示例代码仓库:https://github.com/Naughtyhusky/csharp-concurrency-cookbook
有问题?欢迎留言讨论!
文章摘自:https://www.cnblogs.com/diamondhusky/p/19856073