从递归到极致优化:树结构构建的性能演进之路
一次简单的代码优化,性能提升 超千倍!本文通过实测数据,揭示树结构构建中隐藏的性能陷阱,并给出最佳实践。
前言
在日常开发中,我们经常需要处理树形结构的数据:组织架构、菜单导航、商品分类、文件目录……这些场景都需要将扁平的数据库记录转换为层级树结构。
今天,让我们从最直观的递归实现开始,一步步优化到极致性能,看看这条优化之路上都有哪些坑。
本文将回答:
- 构建树的常见方式有哪些?
- 为什么有些实现在大数据量下会崩溃?
- 如何用一行代码实现数百倍性能提升?
-
ILookup为什么这么快?
测试环境:
- .NET 8.0
- 测试数据:10,000 ~ 100,000 个节点
- 硬件:普通笔记本电脑。11th Gen Intel(R) Core(TM) i5-1135G7 @ 2.40GHz (2.42 GHz) | 16.0 GB
第一章:最直观的实现 – 递归方式
1.1 数据模型
首先定义我们的节点结构:
// 扁平数据(数据库记录)
public class Node
{
public int Id { get; set; }
public int ParentId { get; set; } // 0 表示根节点
public string Name { get; set; }
}
// 树结构
public class TreeItem<T>
{
public T Node { get; set; }
public List<TreeItem<T>> Children { get; set; } = new();
}
1.2 递归实现
最直观的思路:对每个节点,递归查找它的子节点。
public static TreeItem<Node> BuildTreeRecursive(List<Node> nodes)
{
var root = nodes.First(n => n.ParentId == 0);
return BuildNode(nodes, root);
}
private static TreeItem<Node> BuildNode(List<Node> allNodes, Node current)
{
var item = new TreeItem<Node> { Node = current };
// 关键:查找当前节点的所有子节点
var children = allNodes.Where(n => n.ParentId == current.Id).ToList();
foreach (var child in children)
{
item.Children.Add(BuildNode(allNodes, child));
}
return item;
}
优点:
- 代码简洁、易理解
- 符合树的自然定义
- 适合小规模数据(< 1,000 节点)
缺点:
- 性能问题:时间复杂度
O(n²) - 栈溢出风险:深度 > 1,000 层会崩溃
让我们先聊聊第二个问题。
第二章:递归的陷阱 – 栈溢出
2.1 问题重现
测试一个链表型树(每个节点只有一个子节点,深度 = 节点数):
// 生成 10,000 个节点的链表树
var nodes = new List<Node>();
for (int i = 1; i <= 10000; i++)
{
nodes.Add(new Node
{
Id = i,
ParentId = i - 1, // 形成链表:0 → 1 → 2 → ... → 10000
Name = $"Node_{i}"
});
}
var tree = BuildTreeRecursive(nodes); // StackOverflowException!
结果:
System.StackOverflowException: Exception of type 'System.StackOverflowException' was thrown.
2.2 为什么会栈溢出?
C# 中每次函数调用都会在调用栈上分配内存(存储局部变量、返回地址等)。递归深度过大时,栈空间耗尽。
典型限制:
- Windows:~1,000 层递归(栈大小 1MB)
- Linux:~10,000 层(栈大小可调整)
2.3 解决方案一:深度保护
private const int MAX_DEPTH = 1000;
private static TreeItem<Node> BuildNode(List<Node> allNodes, Node current, int depth)
{
if (depth > MAX_DEPTH)
throw new InvalidOperationException("树深度超过限制,建议使用迭代方式");
var item = new TreeItem<Node> { Node = current };
var children = allNodes.Where(n => n.ParentId == current.Id).ToList();
foreach (var child in children)
{
item.Children.Add(BuildNode(allNodes, child, depth + 1));
}
return item;
}
这样至少能提前发现问题,而不是让程序直接崩溃。
第三章:迭代方式 – DFS 与 BFS
既然递归有深度限制,我们用迭代替代递归。
3.1 DFS(深度优先搜索)- 使用栈
public static TreeItem<Node> BuildTreeDFS(List<Node> nodes)
{
var root = new TreeItem<Node>
{
Node = nodes.First(n => n.ParentId == 0)
};
var stack = new Stack<TreeItem<Node>>();
stack.Push(root);
while (stack.Count > 0)
{
var current = stack.Pop();
// 仍然是线性查找
var children = nodes
.Where(n => n.ParentId == current.Node.Id)
.OrderByDescending(n => n.Id)
.ToList();
foreach (var child in children)
{
var childItem = new TreeItem<Node> { Node = child };
current.Children.Add(childItem);
stack.Push(childItem);
}
}
return root;
}
3.2 BFS(广度优先搜索)- 使用队列
public static TreeItem<Node> BuildTreeBFS(List<Node> nodes)
{
var root = new TreeItem<Node>
{
Node = nodes.First(n => n.ParentId == 0)
};
var queue = new Queue<TreeItem<Node>>();
queue.Enqueue(root);
while (queue.Count > 0)
{
var current = queue.Dequeue();
// 仍然是线性查找
var children = nodes
.Where(n => n.ParentId == current.Node.Id)
.OrderBy(n => n.Id)
.ToList();
foreach (var child in children)
{
var childItem = new TreeItem<Node> { Node = child };
current.Children.Add(childItem);
queue.Enqueue(childItem);
}
}
return root;
}
3.3 迭代 vs 递归
| 特性 | 递归 | DFS/BFS 迭代 |
|---|---|---|
| 深度限制 | ~1000层 | 无限制 |
| 代码复杂度 | 简洁 | ️ 稍复杂 |
| 调试难度 | ️ 较难 | 容易 |
| 性能 | 稍慢(函数调用开销) | 稍快 |
看起来问题解决了?并没有! 让我们做个性能测试。
第四章:性能灾难 – O(n²) 的真相
4.1 性能测试
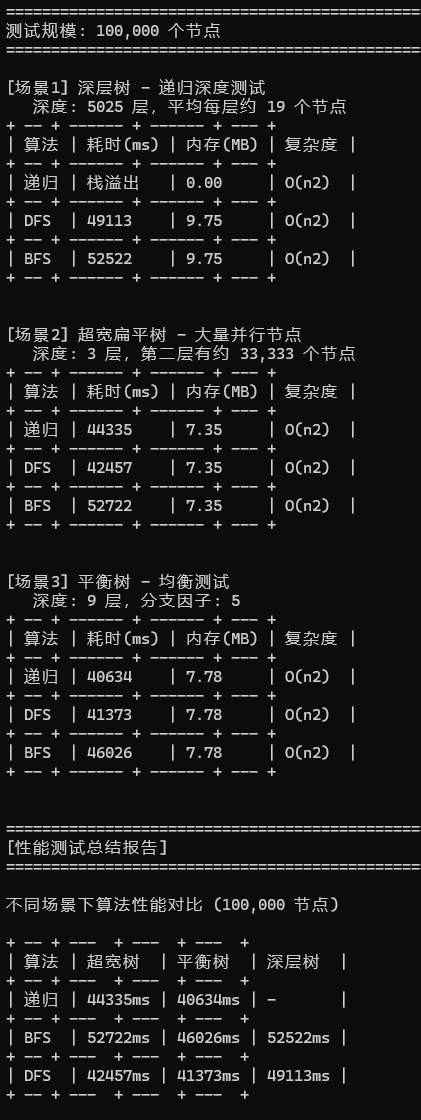
为了贴合实际情况,我分了三个场景来进行测试:深层树(层级很深,每层节点数量少),超宽树(层级很浅,但是每层节点数量多),平衡树(深度和宽度都相对平均,整体结构有点类似平衡二叉树)。节点数量:10万个(节点少了也看不出什么效果)。
直接贴图看结果(基于RELEASE模式编译):

核心算法代码上面已经贴出,具体数据构建以及测试代码,这里就不贴出来了,如果有想看的朋友,可以留言。
注意:
- 10 万节点用了 40-50秒!
- 递归方式早已栈溢出
4.2 性能分析:为什么这么慢?
让我们看看这段代码:
while (stack.Count > 0) // 遍历所有节点:n 次
{
var current = stack.Pop();
// 每次都要扫描整个列表!
var children = nodes.Where(n => n.ParentId == current.Node.Id); // O(n)
// ...
}
时间复杂度分析:
- 外层循环:
O(n)– 遍历所有节点 - 内层
Where:O(n)– 每次扫描整个列表 - 总复杂度:
O(n²)
具体计算:
- 50,000 个节点 → 需要 25 亿次比较操作!
- 100,000 个节点 → 需要 100 亿次比较操作!
这就是性能杀手!
4.3 核心问题
// 问题代码:在循环中使用 Where
foreach (var node in nodes) // n 次
{
var children = allNodes.Where(n => n.ParentId == node.Id); // 每次 O(n)
// 总复杂度:O(n²)
}
这是实际项目中最常见的性能陷阱!
第五章:极致优化 – ILookup 的魔法
5.1 核心思路:空间换时间
既然每次都要查找 ParentId == xxx 的节点,为什么不提前建立索引?
// 原来:每次查找都要扫描整个列表
var children = nodes.Where(n => n.ParentId == parentId); // O(n)
// 现在:提前建立索引,查找变成 O(1)
var lookup = nodes.ToLookup(n => n.ParentId); // 一次性建立索引 O(n)
var children = lookup[parentId]; // 直接查找 O(1)
5.2 什么是 ILookup?
ILookup<TKey, TElement> 是 LINQ 提供的一个接口,类似于 Dictionary<TKey, List<TValue>>,但:
- 一键多值:自动处理一对多关系
- 不会抛异常:查询不存在的键返回空集合
- 基于哈希表:查找时间
O(1) - 只读不可变:线程安全
语法:
// 创建
ILookup<int, Node> lookup = nodes.ToLookup(n => n.ParentId);
// 查询(即使 999 不存在也不会异常)
IEnumerable<Node> children = lookup[999]; // 返回空集合
// 检查是否存在
bool exists = lookup.Contains(999);
// 遍历所有分组
foreach (var group in lookup)
{
Console.WriteLine($"ParentId: {group.Key}, Count: {group.Count()}");
}
5.3 优化后的代码
只需改一行!
public static TreeItem<Node> BuildTreeDFSOptimized(IEnumerable<Node> nodes)
{
var nodeList = nodes.ToList();
// 核心优化:提前建立索引
var lookup = nodeList.ToLookup(n => n.ParentId); // 只加了这一行!
var root = new TreeItem<Node>
{
Node = nodeList.First(n => n.ParentId == 0)
};
var stack = new Stack<TreeItem<Node>>();
stack.Push(root);
while (stack.Count > 0)
{
var current = stack.Pop();
// 从 O(n) 变成 O(1)
var children = lookup[current.Node.Id] // 改这里
.OrderByDescending(n => n.Id)
.ToList();
foreach (var child in children)
{
var childItem = new TreeItem<Node> { Node = child };
current.Children.Add(childItem);
stack.Push(childItem);
}
}
return root;
}
改动对比:
public static TreeItem<Node> BuildTreeDFS(List<Node> nodes)
{
+ var lookup = nodes.ToLookup(n => n.ParentId);
// ...
while (stack.Count > 0)
{
var current = stack.Pop();
- var children = nodes.Where(n => n.ParentId == current.Node.Id);
+ var children = lookup[current.Node.Id];
}
}
就这么简单!
第六章:性能对决 – 实测数据
6.1 完整测试
测试代码:
internal class TreeBuilder
{
private const int MAX_RECURSION_DEPTH = 1000; // 最大递归深度限制
#region 1. 递归方式构建树(原始 - 每次线性查找,带深度保护)
public static TreeItem<Node> BuildTreeRecursive(IEnumerable<Node> nodes)
{
var nodeList = nodes.ToList();
var rootNode = nodeList.FirstOrDefault(n => n.ParentId == 0) ?? throw new InvalidOperationException("No root node found");
return BuildRecursiveNode(nodeList, rootNode, 0);
}
private static TreeItem<Node> BuildRecursiveNode(List<Node> allNodes, Node currentNode, int depth)
{
// 深度保护:超过限制时抛出异常,避免真正的栈溢出
if (depth > MAX_RECURSION_DEPTH)
{
throw new StackOverflowException($"递归深度超过限制 ({MAX_RECURSION_DEPTH})");
}
var treeItem = new TreeItem<Node> { Node = currentNode };
// O(n) 线性查找子节点
var children = allNodes.Where(n => n.ParentId == currentNode.Id).ToList();
foreach (var child in children)
{
treeItem.Children.Add(BuildRecursiveNode(allNodes, child, depth + 1));
}
return treeItem;
}
#endregion
#region 2. DFS方式构建树(原始 - 使用栈,每次线性查找)
public static TreeItem<Node> BuildTreeDFS(IEnumerable<Node> nodes)
{
var nodeList = nodes.ToList();
var rootNode = nodeList.FirstOrDefault(n => n.ParentId == 0) ?? throw new InvalidOperationException("No root node found");
var root = new TreeItem<Node> { Node = rootNode };
var stack = new Stack<TreeItem<Node>>();
stack.Push(root);
while (stack.Count > 0)
{
var current = stack.Pop();
// O(n) 线性查找子节点
var children = nodeList.Where(n => n.ParentId == current.Node.Id).OrderByDescending(n => n.Id).ToList();
foreach (var child in children)
{
var childItem = new TreeItem<Node> { Node = child };
current.Children.Add(childItem);
stack.Push(childItem);
}
}
return root;
}
#endregion
#region 3. BFS方式构建树(原始 - 使用队列,每次线性查找)
public static TreeItem<Node> BuildTreeBFS(IEnumerable<Node> nodes)
{
var nodeList = nodes.ToList();
var rootNode = nodeList.FirstOrDefault(n => n.ParentId == 0) ?? throw new InvalidOperationException("No root node found");
var root = new TreeItem<Node> { Node = rootNode };
var queue = new Queue<TreeItem<Node>>();
queue.Enqueue(root);
while (queue.Count > 0)
{
var current = queue.Dequeue();
// O(n) 线性查找子节点
var children = nodeList.Where(n => n.ParentId == current.Node.Id).OrderBy(n => n.Id).ToList();
foreach (var child in children)
{
var childItem = new TreeItem<Node> { Node = child };
current.Children.Add(childItem);
queue.Enqueue(childItem);
}
}
return root;
}
#endregion
#region 4. 优化的递归方式(使用字典索引 - O(n),带深度保护)
public static TreeItem<Node> BuildTreeRecursiveOptimized(IEnumerable<Node> nodes)
{
var nodeList = nodes.ToList();
var lookup = nodeList.ToLookup(n => n.ParentId);
var rootNode = nodeList.FirstOrDefault(n => n.ParentId == 0) ?? throw new InvalidOperationException("No root node found");
return BuildRecursiveOptimizedNode(lookup, rootNode, 0);
}
private static TreeItem<Node> BuildRecursiveOptimizedNode(ILookup<int, Node> lookup, Node currentNode, int depth)
{
// 深度保护
if (depth > MAX_RECURSION_DEPTH)
{
throw new StackOverflowException($"递归深度超过限制 ({MAX_RECURSION_DEPTH})");
}
var treeItem = new TreeItem<Node> { Node = currentNode };
// O(1) 通过索引查找子节点
var children = lookup[currentNode.Id];
foreach (var child in children)
{
treeItem.Children.Add(BuildRecursiveOptimizedNode(lookup, child, depth + 1));
}
return treeItem;
}
#endregion
#region 5. 优化的DFS(使用字典索引 - O(n))
public static TreeItem<Node> BuildTreeDFSOptimized(IEnumerable<Node> nodes)
{
var nodeList = nodes.ToList();
var lookup = nodeList.ToLookup(n => n.ParentId);
var rootNode = nodeList.FirstOrDefault(n => n.ParentId == 0) ?? throw new InvalidOperationException("No root node found");
var root = new TreeItem<Node> { Node = rootNode };
var stack = new Stack<TreeItem<Node>>();
stack.Push(root);
while (stack.Count > 0)
{
var current = stack.Pop();
// O(1) 通过索引查找子节点
var children = lookup[current.Node.Id].OrderByDescending(n => n.Id).ToList();
foreach (var child in children)
{
var childItem = new TreeItem<Node> { Node = child };
current.Children.Add(childItem);
stack.Push(childItem);
}
}
return root;
}
#endregion
#region 6. 优化的BFS(使用字典索引 - O(n))
public static TreeItem<Node> BuildTreeBFSOptimized(IEnumerable<Node> nodes)
{
var nodeList = nodes.ToList();
var lookup = nodeList.ToLookup(n => n.ParentId);
var rootNode = nodeList.FirstOrDefault(n => n.ParentId == 0) ?? throw new InvalidOperationException("No root node found");
var root = new TreeItem<Node> { Node = rootNode };
var queue = new Queue<TreeItem<Node>>();
queue.Enqueue(root);
while (queue.Count > 0)
{
var current = queue.Dequeue();
// O(1) 通过索引查找子节点
var children = lookup[current.Node.Id].OrderBy(n => n.Id).ToList();
foreach (var child in children)
{
var childItem = new TreeItem<Node> { Node = child };
current.Children.Add(childItem);
queue.Enqueue(childItem);
}
}
return root;
}
#endregion
}
6.2 测试结果

6.3 性能分析
时间复杂度对比:
| 实现方式 | 建索引 | 查找子节点 | 总复杂度 |
|---|---|---|---|
| 原始方式 | – | O(n) | O(n²) |
| 优化方式 | O(n) 一次性 | O(1) | O(n) |
内存占用:
- 原始方式:
O(n)– 只存储节点 - 优化方式:
O(n)– 节点 + Lookup 索引(额外约 20-30%)
为什么集中算法的最终内存都是一样的?
1. 输入数据相同:所有算法都使用同一个 nodes 列表(100,000 个 Node)
2. 输出结构相同:所有算法都构建相同的树结构(TreeItem 对象)
3. 最终内存相同:树的总内存 = 节点数 × 每个 TreeItem 的大小
// 构建后的树内存
100,000 个 TreeItem<Node> 对象
├─ 每个 TreeItem: ~80 字节
│ ├─ Node 引用: 8 字节
│ └─ Children List: 72 字节(包含数组、计数等)
└─ 总计: ~7.8 MB
结论:
- 用 20-30% 内存换取 超过千倍的性能提升
- 绝对值得!
第七章:深入理解 ILookup
7.1 为什么 ILookup 这么快?
内部实现原理(简化版):
// ToLookup 内部大致做了这些事
public static ILookup<TKey, TElement> ToLookup<TKey, TElement>(
this IEnumerable<TElement> source,
Func<TElement, TKey> keySelector)
{
// 1. 创建哈希表
var groups = new Dictionary<TKey, List<TElement>>();
// 2. 遍历一次,建立索引 - O(n)
foreach (var item in source)
{
var key = keySelector(item);
if (!groups.ContainsKey(key))
groups[key] = new List<TElement>();
groups[key].Add(item);
}
// 3. 返回只读的 Lookup
return new Lookup<TKey, TElement>(groups);
}
// 查找时 - O(1)
public IEnumerable<TElement> this[TKey key]
{
get
{
return groups.ContainsKey(key)
? groups[key]
: Enumerable.Empty<TElement>(); // 不存在返回空集合
}
}
关键点:
- 使用
Dictionary作为底层存储(哈希表) - 查找时间:
O(1)– 直接通过哈希值定位 - 不存在的键返回空集合,不抛异常
7.2 ILookup vs Dictionary vs GroupBy
var nodes = GetNodes();
// 1. GroupBy - 每次查询都重新分组(慢!)
var groups = nodes.GroupBy(n => n.ParentId);
var children1 = groups.FirstOrDefault(g => g.Key == 100)?.ToList(); // O(n) 每次都分组
// 2. Dictionary - 需要手动处理一对多
var dict = new Dictionary<int, List<Node>>();
foreach (var node in nodes)
{
if (!dict.ContainsKey(node.ParentId))
dict[node.ParentId] = new List<Node>();
dict[node.ParentId].Add(node);
}
var children2 = dict.ContainsKey(100) ? dict[100] : new List<Node>(); // O(1) 但需要判断
// 3. Lookup - 一行搞定,自动处理一对多(快!)
var lookup = nodes.ToLookup(n => n.ParentId);
var children3 = lookup[100]; // O(1) 且不需要判断
对比表:
| 特性 | GroupBy | Dictionary | ILookup |
|---|---|---|---|
| 建立索引 | 延迟执行 | 手动构建 | 一行代码 |
| 一键多值 | 需手动 | ||
| 查找速度 | O(n) 每次分组 | O(1) | O(1) |
| 键不存在 | 返回 null | 抛异常 | 返回空集合 |
| 代码简洁性 | ️ | ||
| 推荐度 | 临时分组 | 一对一映射 | 父子关系 |
第八章:实战应用
8.1 常见场景
场景1:订单-订单项
// 慢
foreach (var order in orders)
{
order.Items = orderItems.Where(oi => oi.OrderId == order.Id).ToList(); // O(n²)
}
// 快
var itemsLookup = orderItems.ToLookup(oi => oi.OrderId);
foreach (var order in orders)
{
order.Items = itemsLookup[order.Id].ToList(); // O(n)
}
场景2:部门-员工
var empLookup = employees.ToLookup(e => e.DepartmentId);
foreach (var dept in departments)
{
dept.Employees = empLookup[dept.Id].ToList();
}
场景3:分类-商品
var prodLookup = products.ToLookup(p => p.CategoryId);
foreach (var category in categories)
{
category.Products = prodLookup[category.Id].ToList();
}
8.2 识别性能陷阱
搜索你的代码库,找这些模式:
// 危险信号
foreach + Where
for + FirstOrDefault
while + Any
// 优化建议
ToLookup + [key]
ToDictionary + [key]
CodeReview 清单:
- 循环中是否有
Where查询? - 是否多次遍历同一个集合?
- 数据量是否可能超过 1,000?
- 能否用
ToLookup或ToDictionary优化?
第九章:完整对比 – 六种实现
9.1 所有实现方式
| 实现方式 | 时间复杂度 | 深度限制 | 代码复杂度 | 推荐场景 |
|---|---|---|---|---|
| 递归(原始) | O(n²) | ~1000层 | ⭐⭐⭐⭐⭐ | 不推荐 |
| 递归(优化) | O(n) | ~1000层 | ⭐⭐⭐⭐⭐ | 小规模(<1000节点) |
| DFS(原始) | O(n²) | 无限制 | ⭐⭐⭐⭐ | 不推荐 |
| DFS(优化) | O(n) | 无限制 | ⭐⭐⭐⭐ | 深树、链表 |
| BFS(原始) | O(n²) | 无限制 | ⭐⭐⭐⭐ | 不推荐 |
| BFS(优化) | O(n) | 无限制 | ⭐⭐⭐⭐ | 宽树、层级 |
9.2 完整实现
六种实现方式的代码上文已经给出,这里不再重复了。
第十章:总结与最佳实践
10.1 核心收获
“优化查找,而非遍历”
- 性能陷阱: 循环中的
Where→O(n²) - 优化武器:
ToLookup→O(n) - 一行改动: 性能提升数百倍
- 递归限制: 深度 > 1000 层会栈溢出
10.2 最佳实践
// 推荐写法
var lookup = nodes.ToLookup(n => n.ParentId);
foreach (var node in nodes)
{
var children = lookup[node.Id];
// ...
}
// 避免写法
foreach (var node in nodes)
{
var children = allNodes.Where(n => n.ParentId == node.Id); // O(n²)
}
10.3 何时使用 ILookup
| 场景 | 是否使用 |
|---|---|
| 一对多关系(父子、分类等) | 强烈推荐 |
| 数据量 > 1,000 | 必须使用 |
| 需要频繁查找 | 强烈推荐 |
| 临时分组(只用一次) | ️ 考虑 GroupBy |
| 一对一映射 | ️ 考虑 Dictionary |
10.4 记忆口诀
循环里有 Where,性能就完蛋;
提前建 Lookup,速度飞上天!
参考资料
一点题外话
DFS(Depth-First Search 深度优先搜索) 和BFS(Breadth-First Search 广度优先搜索),这两个术语都来自图论,核心是搜索(在数据结构中寻找特定节点或路径)。
但我们在构建树时,只是按深度优先(或者广度优先)的顺序访问节点并建立父子关系,并没有“搜索”任何目标。严格来说,这应该叫深度优先遍历(Depth-First Traversal)或深度优先构建(Depth-First Construction),广度优先同理。
但为什么大家都习惯叫DFS/BFS?
这是典型的算法术语泛化现象:
- 起源:图论中的DFS确实是为了搜索/遍历
- 发展:人们发现“用栈处理树形结构”这种模式非常通用
- 泛化:任何使用栈来处理树/图结构的操作,都被口语化地称为“用DFS的方式”
- 固化:面试、技术文章、开源代码都这么用,形成了约定俗成
类似例子还有很多:
- “用BFS爬取网页” → 其实只是广度优先遍历URL
- “递归遍历文件夹” → 并不是在搜索什么
- “二叉树的前/中/后序遍历” → 其实也是DFS的特例,但很少人说“DFS二叉树”
为什么没人纠正?
因为沟通成本高于精确性成本。当你面试时说“我用DFS把列表转成树”,所有人都秒懂。如果说“我用深度优先遍历的迭代方式,借助栈后进先出的特性来构建层级结构”——太啰嗦了,反而影响沟通效率。
但在实际开发中,“用DFS构建树”已经是行业黑话,大家都接受这个语义泛化后的含义了。
结语
一次简单的代码优化,性能提升 超过千倍。
在实际项目中,这样的优化机会比比皆是。关键是:
- 测量:用 Stopwatch 测量,找到瓶颈
- 分析:识别 O(n²) 的查找操作
- 优化:用 ToLookup/ToDictionary 建立索引
- 验证:再次测量,确认提升
记住:
过早优化是万恶之源,但该优化时别手软!
文章摘自:https://www.cnblogs.com/diamondhusky/p/19605488