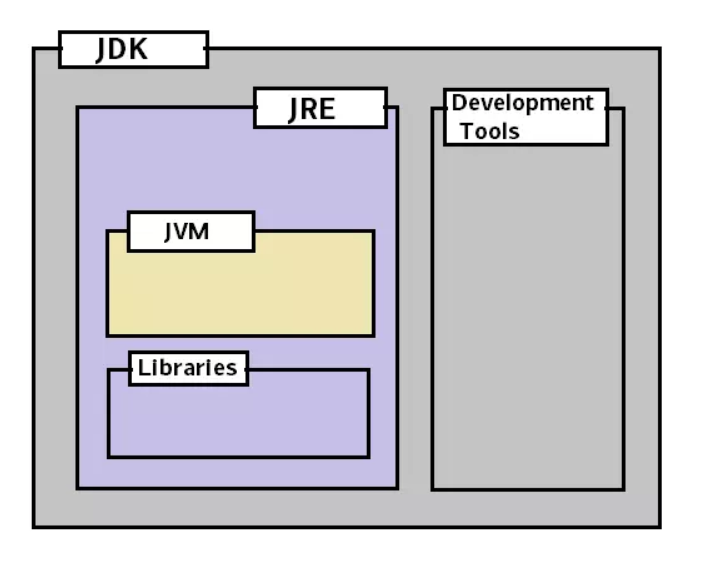
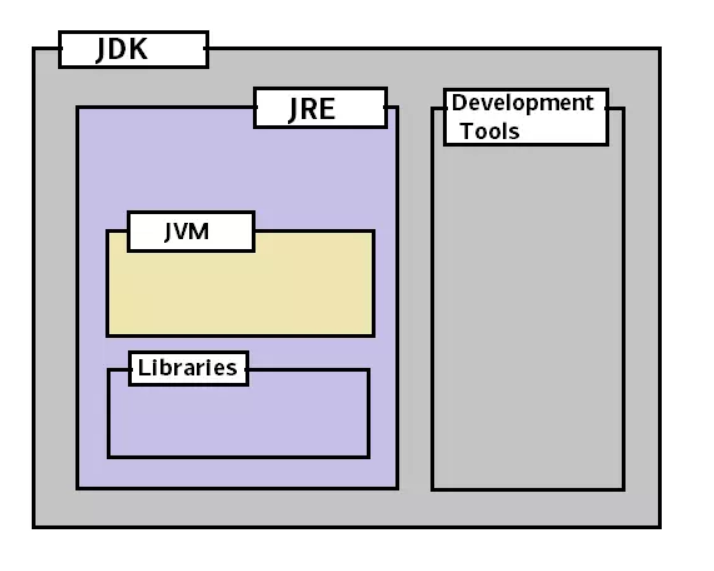
JDK, JRE, JVM的关系
- 解释器: 逐行转换字节码为机器码
- 即时编译器(JIT):将热点代码(经常执行的代码段)编译成高效的本地机器码,并缓存起来以供后续直接执行 Just-In-Time Compiler
就范围来说,JDK > JRE > JVM:
- JDK = JRE + 开发工具
- JRE = JVM + 类库
jar包 – > java字节码 – > 机器码
我们利用 JDK (调用 Java API)开发 Java 程序,编译成字节码或者打包程序。然后可以用 JRE 则启动一个 JVM 实例,加载、验证、执行 Java 字节码以及依赖库,运行 Java 程序。而 JVM 将程序和依赖库的 Java 字节码解析并变成本地代码(机器码)执行
解释执行和即使编译
- 解释执行:
- 在解释执行阶段,Java 虚拟机直接读取并执行 Java 字节码(.class 文件中的内容)。每条字节码指令都被逐条解释并执行。
- 解释执行的优点是启动速度快,因为不需要等待编译过程完成。
- 解释执行的缺点是执行速度较慢,因为每条指令都需要解释。
- 即时编译(JIT):
- 当 Java 虚拟机检测到某些代码被频繁执行(称为热点代码)时,会启动即时编译器,将这些热点代码编译成本地机器码。
- 编译后的机器码可以直接在硬件上运行,执行速度更快。
- JIT 编译的过程是动态的,编译后的代码会存储在内存中,以供后续使用。
字节码和机器码的转换
- 初始执行:程序启动时,Java 虚拟机会先通过解释执行的方式运行字节码。
- 热点检测:在执行过程中,Java 虚拟机会监控代码的执行频率。
- JIT 编译:当检测到热点代码时,Java 虚拟机会启动 JIT 编译器,将这些代码编译成机器码。
- 执行转换:一旦代码被编译成机器码,后续的执行会直接使用机器码,而不是继续解释执行字节码。
性能优化
80⁄20 原则 : 前 20% 的瓶颈 问题, 至少会对性能影响占到 80% 比重
三个维度
- 延迟 95线, 99线 – Latency
- 吞吐量 TPS, QPS – Throughput
- 系统容量 -硬件配置 – Capacity
跨平台
- 解释型语言 – 点名 python (但是python很多点都优化了)
运行时要一直依赖解释器
每次启动重新解释
error不运行不报错
“’. . . ‘”
源码跨平台 -cpp
“一次编写,到处调试”
一份源码, 不同平台编译
产生很多环境方面的配置问题
开发维护成本高
效率高
二进制跨平台 -java字节码
真正的 “一次编写,到处(不同平台)编译”
编译生成jar包(通用java字节码)
部署到不同平台
JVM通过jar包将字节码加载到目标机器
效率比不上本地编译
Runtime
- JVM (Java Virtual Machine):负责执行字节码的核心引擎。
- JRE (Java Runtime Environment):提供运行时所需的完整环境,包括 JVM 和标准类库。
- 运行时数据和状态:如内存分配、线程状态、异常处理等,这些是在程序运行时动态管理的。
因此,”runtime” 是一个抽象概念,而 JVM 是实现这个概念的具体技术实体。
编程语言简评
- C/C++ 完全相信而且惯着程序员,让大家自行管理内存,所以可以编写很自由的代码,但一个不小心就会造成内存泄漏等问题导致程序崩溃。
- Java/Golang 完全不相信程序员,但也惯着程序员。所有的内存生命周期都由 JVM 运行时统一管理。 在绝大部分场景下,你可以非常自由的写代码,而且不用关心内存到底是什么情况。 内存使用有问题的时候,我们可以通过 JVM 来信息相关的分析诊断和调整。
- Rust 语言选择既不相信程序员,也不惯着程序员。 让你在写代码的时候,必须清楚明白的用 Rust 的规则管理好你的变量,好让机器能明白高效地分析和管理内存。 但是这样会导致代码不利于人的理解,写代码很不自由,学习成本也很高。
Java 基本类型
java基本类型不属于object类, 当int类传入object类时需要转换为Integer类的封箱
java内部缓存了int[-128,127]对应的封箱
除 long 和 double 外,其他基本类型与引用类型在解释执行的方法栈帧中占用的大小是一致的,但它们在堆中占用的大小确不同。在将 Boolean 、byte 、char 以及 short 的值存入字段或者数组单元时,Java 虚拟机会进行掩码操作。在读取时,Java 虚拟机则会将其扩展为 int 类型
Java编译器
自动装箱与自动拆箱
基本类型 → 对象(int → Integer)
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
可通过调节 java.lang.Integer.IntegerCache.high 调高缓存int的范围
但是不知道为什么没有java.___.low
泛型与类型擦除
对于泛型方法 传出参数的类型大概率是(Object.class), 代表着其中的类型擦除
并不是每一个泛型参数被擦除类型后都会变成 Object 类。对于限定了继承类(extend A)的泛型参数,经过类型擦除后,所有的泛型参数都将变成所限定的继承类(class A)。也就是说,Java 编译器将选取该泛型所能指代的所有类中层次最高的那个,作为替换泛型的类。
桥接方法
由于泛型擦除 父方法的传入参数发生改变(Object t) 不符合重写规则从而引入了桥接方法
class Parent<T> {
public void method(T t) {
System.out.println("Parent");
}
}
class Child extends Parent<String> {
@Override
public void method(String s) {
System.out.println("Child");
}
}
**泛型擦除后的父方法**
public void method(Object t) {
System.out.println("Parent");
}
**java编译器生成的桥接方法**
public void method(Object t) {
method((String) t);
}
public void method(String s) {
System.out.println("Child");
}
Java对象的内存布局
// Foo foo = new Foo(); 编译而成的字节码
0 new Foo
3 dup
4 invokespecial Foo()
7 astore_1
// Foo 类构造器会调用其父类 Object 的构造器
public Foo();
0 aload_0 [this]
1 invokespecial java.lang.Object() [8]
4 return
总而言之,当我们调用一个构造器时,它将优先调用父类的构造器,直至 Object 类。这些构造器的调用者皆为同一对象,也就是通过 new 指令新建而来的对象。
通过 new 指令新建出来的对象,它的内存其实涵盖了所有父类中的实例字段。也就是说,虽然子类无法访问父类的私有实例字段,或者子类的实例字段隐藏了父类的同名实例字段,但是子类的实例还是会为这些父类实例字段分配内存的。
压缩指针
其实很好理解就是相对寻址
只需要存储偏移量, 存储压力变小了
然后偏移量的固定单元大小为8b
为什么是8呢, 会不会导致浪费?
long类型就占8b了, 同理double/float,即使int也要4b
即使浪费一点也没关系用内存换高速缓存不是血赚吗
object header(16B)→(12B)
- 标记字段(64b)
存储 Java 虚拟机有关该对象的运行数据,如哈希码、GC 信息以及锁信息
- 类型指针(64b)→(32b)压缩指针
指向该对象的类
- 指针压缩:32 位指针本身只能直接寻址 2^32 字节,也就是 4GB 的地址空间。但是,通过在指针和实际内存地址之间引入一个转换机制,可以扩展寻址范围。
- 地址转换:Java 虚拟机使用一种称为“地址压缩和解压缩”的技术。简单来说,32 位指针被视为一个偏移量,这个偏移量乘以一个固定值(通常是 8bit)→ 字段重排列,再加上一个基地址,就可以得到实际的 64 位内存地址。
- 寻址范围:通过这种方式,32 位指针可以表示的最大偏移量是 2^32−1。当这个偏移量乘以 8 时,最大地址就变成了 2^32×8=235 字节,也就是 32GB。
字段重排列,顾名思义,就是 Java 虚拟机重新分配字段的先后顺序,以达到内存对齐的目的。Java 虚拟机中有三种排列方法(对应 Java 虚拟机选项 -XX:FieldsAllocationStyle,默认值为 1),但都会遵循如下两个规则。
其一,如果一个字段占据 C 个字节,那么该字段的偏移量需要对齐至 NC。这里偏移量指的是字段地址与对象的起始地址差值。
以 long 类为例,它仅有一个 long 类型的实例字段。在使用了压缩指针的 64 位虚拟机中,尽管对象头的大小为 12 个字节,该 long 类型字段的偏移量也只能是 16,而中间空着的 4 个字节便会被浪费掉。
其二,子类所继承字段的偏移量,需要与父类对应字段的偏移量保持一致。
在具体实现中,Java 虚拟机还会对齐子类字段的起始位置。对于使用了压缩指针的 64 位虚拟机,子类第一个字段需要对齐至 4N;而对于关闭了压缩指针的 64 位虚拟机,子类第一个字段则需要对齐至 8N。
JAVA字节码
感觉和机器码类似, 不做过多叙述, 偷懒了哈哈
java字节码编译
- C1 : 又叫做 Client 编译器,面向的是对启动性能有要求的客户端 GUI 程序,采用的优化手段相对简单,因此编译时间较短。
- C2 : 又叫做 Server 编译器,面向的是对峰值性能有要求的服务器端程序,采用的优化手段相对复杂,因此编译时间较长,但同时生成代码的执行效率较高。
- Graal(java10+) :
从 Java 7 开始,HotSpot 默认采用分层编译的方式:热点方法首先会被 C1 编译
C1内分为三层
- no profiling 无数据支持的优化
- limit profiling 有一定数据支持的优化
- full profiling 全数据支持的优化
而后热点方法中的热点会进一步被 C2 编译。
为了不干扰应用的正常运行,HotSpot 的即时编译是放在额外的编译线程中进行的。HotSpot 会根据 CPU 的数量设置编译线程的数目,并且按 1:2 的比例配置给 C1 及 C2 编译器。
在计算资源充足的情况下,字节码的解释执行和即时编译可同时进行。编译完成后的机器码会在下次调用该方法时启用,以替换原本的解释执行。
02正在路上了!!!