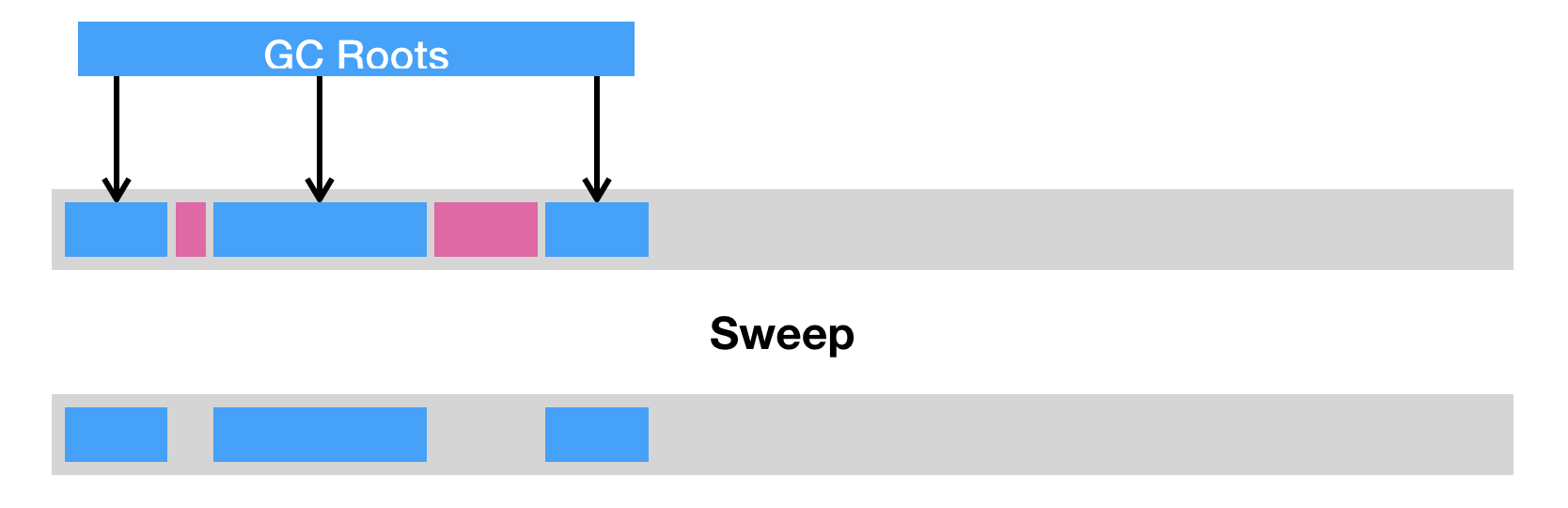
垃圾回收
引用计数法和可达性分析
- 引用计数法
即记录对象的reference count若≠0则保留
a, b对象相互引用, 不可回收, 造成内存泄露
- 可达性分析(JVM主流使用)
从GC Root出发的树状结构
若对象不可达则回收
GC Roots 包括(但不限于)如下几种:
- Java 方法栈桢中的局部变量;
- 已加载类的静态变量;
- JNI handles;
- 已启动且未停止的 Java 线程。
- 存在的问题
在多线程环境下,其他线程可能会更新已经访问过的对象中的引用,从而造成误报(将引用设置为 null)或者漏报(将引用设置为未被访问过的对象)
Stop-the-world 以及安全点
当 Java 虚拟机收到 Stop-the-world 请求,它便会等待所有的线程都到达安全点,才允许请求 Stop-the-world 的线程进行独占的工作。(安全词🤣🤣🤣)
安全检测
(即使程序最终可能被 JIT 编译成机器码,但在解释执行阶段,Java 虚拟机仍然需要处理 Java 字节码)
- 解释执行 当有安全点请求时,执行一条字节码便进行一次安全点检测
- 即时编译 生成机器码时,即时编译器需要插入安全点检测
同时保证不连续插入减小开销
垃圾回收的三种方式
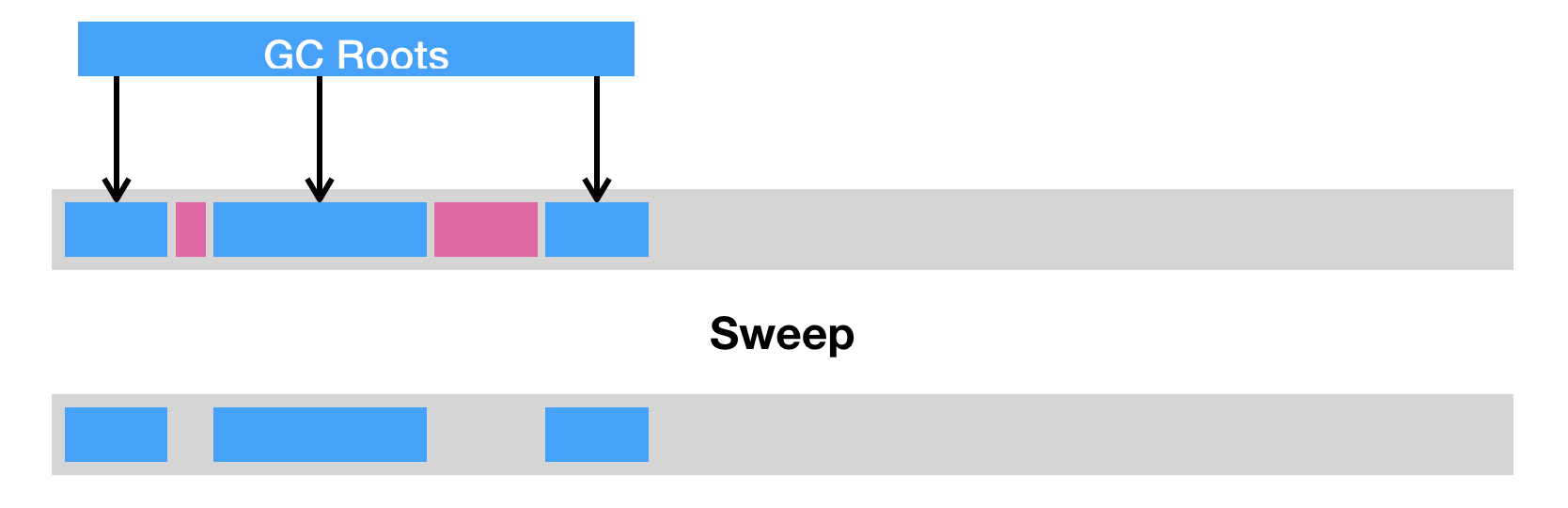
- 清除(sweep)
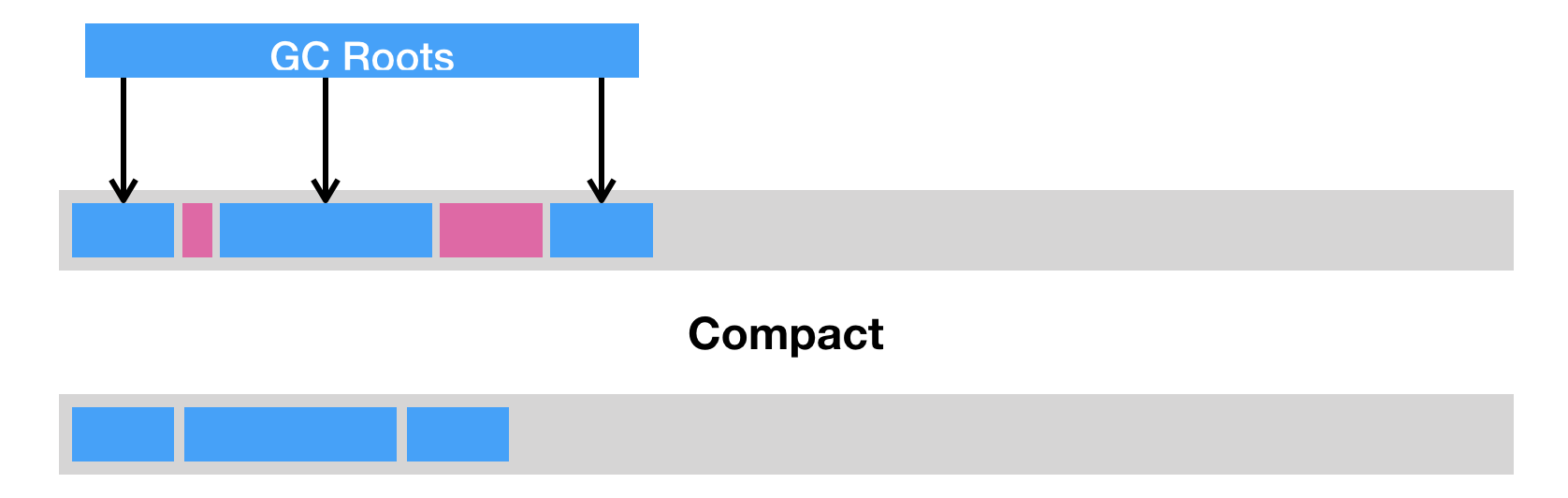
- 压缩(compact)
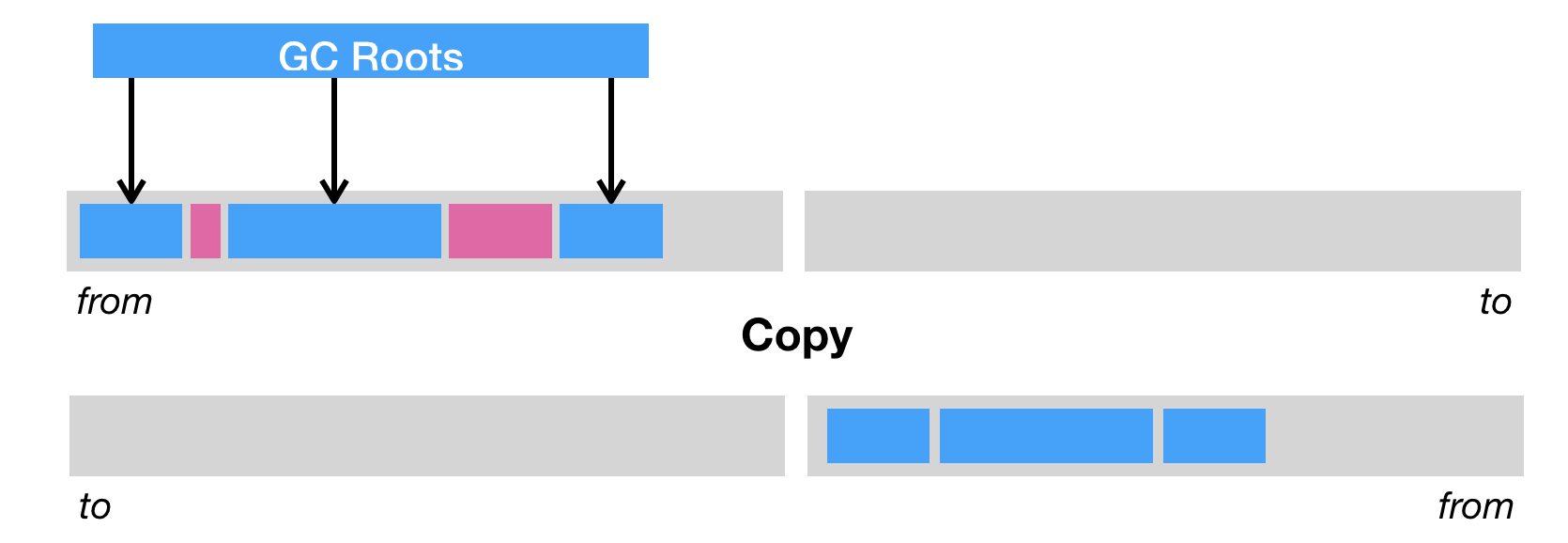
- 复制(copy)
Java虚拟机的堆划分
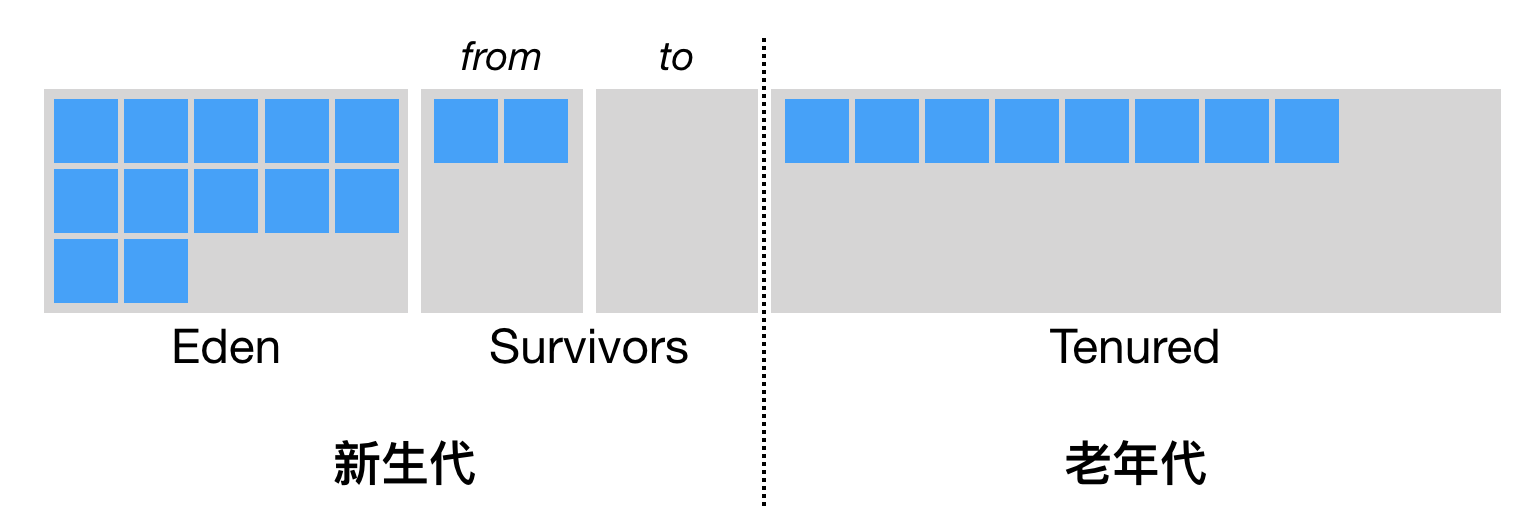
- new 指令执行时将对象存储在Eden区
- Eden区满进行一次Minor GC
Minor GC收集新生代的垃圾, 同时扫描老年代的对象以确保所有被引用的年轻代对象都被正确标记为存活对象。
- 仍存活于JVM eden区的对象转移到from区
- Survivors区通过copy进行垃圾回收
- 在Survivors区长期存活对象转移到老年代
TLAB(acquire lock())
每个线程可以向 Java 虚拟机申请一段连续的内存
线程维护内存头尾指针
卡表
维护每张卡的dirty位
卡中存在写入, 则dirty位置1
卡: 将堆划分为多个512字节的卡
if (CARD_TABLE [this address >> 9] != DIRTY) //减少重复写的不必要开销 CARD_TABLE [this address >> 9] = DIRTY;
为避免扫描所有的老年代对象 ,导致新生代的对象重复扫描,导致的重复扫描对象堆
GC通过寻找dirty卡扫描, 扫描完dirty清零
Java内存模型
在单线程中由于 as-if-serial 原则 不会改变程序重排序的运行结果
多线程就要涉及到 happen-before
as-if-serial 语义的目的是为了在不改变程序正确性的前提下,允许编译器和处理器进行各种优化,从而提高程序的执行效率。具体来说,它允许:
- 编译器优化:编译器可以对代码进行重排序,以提高代码的执行效率。
- 处理器优化:处理器可以对指令进行重排序,以提高指令的执行效率。
happens-before (java 5)
描述两个操作的内存可见性
如果操作 X happens-before 操作 Y,那么 X 的结果对于 Y 可见
在同一个线程中,字节码的先后顺序(program order)也暗含了 happens-before 关系:在程序控制流路径中靠前的字节码 happens-before 靠后的字节码。然而,这并不意味着前者一定在后者之前执行。实际上,如果后者没有观测前者的运行结果,即后者没有数据依赖于前者,那么它们可能会被重排序。
- 解锁操作 happens-before 之后(这里指时钟顺序先后)对同一把锁的加锁操作。
- volatile 字段的写操作 happens-before 之后(这里指时钟顺序先后)对同一字段的读操作。
- 线程的启动操作(即Thread.starts()) happens-before 该线程的第一个操作。
- 线程的最后一个操作 happens-before 它的终止事件(即其他线程通过Thread.isAlive()或Thread.join()判断该线程是否中止)。
- 线程对其他线程的中断操作 happens-before 被中断线程所收到的中断事件(即被中断线程的InterruptedException异常,或者第三个线程针对被中断线程的Thread.interrupted或者Thread.isInterrupted调用)。
- 构造器中的最后一个操作 happens-before 析构器的第一个操作。
happens-before 关系还具备传递性。X→Y , Y→Z = X→Z
Java 内存模型的底层实现
对于即时编译器来说,它会针对前面提到的每一个 happens-before 关系,向正在编译的目标方法中插入相应的读读、读写、写读以及写写内存屏障。
内存屏障
即时编译器将根据具体的底层体系架构,将这些内存屏障替换成具体的 CPU 指令
如6.S081的__sync_synchronize()
以我们日常接触的 X86_64 架构来说,读读、读写以及写写内存屏障是空操作(no-op),只有写读内存屏障会被替换成具体指令
然而,在 X86_64 架构上,只有 volatile 字段写操作之后的写读内存屏障需要用具体指令来替代。(HotSpot 所选取的具体指令是 lock add DWORD PTR [rsp],0x0,而非 mfence[3]。)
该具体指令的效果,可以简单理解为强制刷新处理器的写缓存。写缓存是处理器用来加速内存存储效率的一项技术。
在碰到内存写操作时,处理器并不会等待该指令结束,而是直接开始下一指令,并且依赖于写缓存将更改的数据同步至主内存(main memory)之中。
强制刷新写缓存,将使得当前线程写入 volatile 字段的值(以及写缓存中已有的其他内存修改),同步至主内存之中。
由于内存写操作同时会无效化其他处理器所持有的、指向同一内存地址的缓存行,因此可以认为其他处理器能够立即见到该 volatile 字段的最新值。
volatile字段与安全发布
Volatile 字段可以看成一种轻量级的、不保证原子性的同步,其性能往往优于(至少不亚于)锁操作。然而,频繁地访问 volatile 字段也会因为不断地强制刷新缓存而严重影响程序的性能。
在 X86_64 平台上只有 volatile 字段的写操作会强制刷新缓存/其他情况均为(no-op)不执行。因此,理想情况下对 volatile 字段的使用应当多读少写,并且应当只有一个线程进行写操作。
volatile 字段的另一个特性是即时编译器无法将其分配到寄存器里。换句话说,volatile 字段的每次访问均需要直接从内存中读写。
安全发布 当发布一个已初始化的对象时,我们希望所有已初始化的实例字段对其他线程可见。否则,其他线程可能见到一个仅部分初始化的新建对象,从而造成程序错误
Java虚拟机实现sync
当声明 synchronized 代码块时,编译而成的字节码将包含monitorenter和monitorexit指令
public void foo(Object lock) {
synchronized (lock) {
lock.hashCode();
}
}
// 上面的 Java 代码将编译为下面的字节码
public void foo(java.lang.Object);
Code:
0: aload_1
1: dup
2: astore_2 //复制lock对象
3: monitorenter
4: aload_1
5: invokevirtual java/lang/Object.hashCode:()I
8: pop
9: aload_2
10: monitorexit
11: goto 19
14: astore_3
15: aload_2
16: monitorexit
17: aload_3
18: athrow
19: return
Exception table:
from to target type
4 11 14 any
14 17 14 any
你可能会留意到,上面的字节码中包含一个monitorenter指令以及多个monitorexit指令。这是因为 Java 虚拟机需要确保所获得的锁在正常执行路径,以及异常执行路径上都能够被解锁。
- ACC_SYNCHRONIZED
public synchronized void foo(Object lock) {
lock.hashCode();
}
// 上面的 Java 代码将编译为下面的字节码
public synchronized void foo(java.lang.Object);
descriptor: (Ljava/lang/Object;)V
flags: (0x0021) ACC_PUBLIC, **ACC_SYNCHRONIZED**
Code:
stack=1, locals=2, args_size=2
0: aload_1
1: invokevirtual java/lang/Object.hashCode:()I
4: pop
5: return
该标记表示在进入该方法时,Java 虚拟机需要进行monitorenter操作。而在退出该方法时,不管是正常返回,还是向调用者抛异常,Java 虚拟机均需要进行monitorexit操作
锁
|———————————————————–|——————|
| Thread ID (偏向锁) / HashCode / GC Age (其他状态) | 锁标志 | epoch |
|———————————————————–|——————|
| 54 bits | 3 bits | 2 bits |
当进行加锁操作时,Java 虚拟机会判断是否已经是重量级锁。如果不是,它会在当前线程的当前栈桢中划出一块空间作为该锁的锁记录,并且将锁对象的标记字段复制到该锁记录中
锁记录 记录加过锁的线程的地址
对象头中的标记字段(mark word)它的最后两位便被用来表示该对象的锁状态。其中,00 代表轻量级锁,01 代表无锁或偏向锁, 10 代表重量级锁,11 则跟垃圾回收算法的标记有关。
CAS(compare-and-swap)是一个原子操作,它会比较目标地址的值是否和期望值相等,如果相等,则替换为一个新的值
- 重量级锁
Java 虚拟机会阻塞加锁失败的线程,并且在目标锁被释放的时候,唤醒这些线程
在被阻塞前, 线程先进入自旋状态
自旋 在处理器上空跑并且轮询锁是否被释放
Java 虚拟机给出的方案是自适应自旋,根据以往自旋等待时是否能够获得锁,来动态调整自旋的时间(循环数目)
- 轻量级锁
通过CAS判断锁的标记字段是否为01
- 01 → 替换为刚分布过锁记录ID(持有线程) 并替换锁标志00
-
else →
- 该线程重复获取同一把锁。此时,Java 虚拟机会将锁记录清零,以代表该锁被重复获取
- 其他线程持有该锁。此时,Java 虚拟机会将这把锁膨胀为重量级锁,并且阻塞当前线程
偏向锁
超级无敌乐观锁 偏好从始至终只有一个线程请求某一把锁
- 锁对象初始化
JVM通过 CAS 操作,将当前线程的地址记录在锁对象的标记字段之中,并且将锁标志设置为 101(偏向锁状态), 同时设置锁对象的epoch = 全局epoch
-
请求锁
- 判断锁指向的对应线程地址是否为该线程,若不是, 全局epoch++ 撤销偏向锁
- 判断 epoch 值是否和锁对象的类的 epoch 值相同 若不是 撤销偏向锁
- 若一切正常
-
撤销偏向锁
- 锁对象可以重新偏向其他线程(若无竞争)
- 悲观化 turn blue
- 撤销需在安全点执行,成本较高,因此JVM通过epoch优化管理
epoch
可以将epoch想象成一个“锁的版本号或“有效期标签”:
- 如果对象的epoch与全局epoch一致,说明偏向锁仍然有效。
- 如果不一致,说明这个偏向锁已经“过期”,需要重新处理。
- 批量撤销偏向锁
- 避免僵尸偏向
某些情况下,一个线程可能已经退出,但它的线程ID仍然“绑定”在大量对象的偏向锁上
- 动态调整优化策略
示例
- 对象A的Mark Word记录了线程T1的ID和epoch=1。
- 如果全局epoch变为2(由于其他线程竞争导致撤销),线程T1再次访问对象A时,发现epoch不匹配,偏向锁失效。
- 对象A的锁状态会被重置,允许重新偏向或升级。
即时编译(JIT)
HotSpot 虚拟机包含多个即时编译器 C1、C2 和 Graal
在 Java 7 以前,我们需要根据程序的特性选择对应的即时编译器。对于执行时间较短的,或者对启动性能有要求的程序,我们采用编译效率较快的 C1,对应参数 -client。
对于执行时间较长的,或者对峰值性能有要求的程序,我们采用生成代码执行效率较快的 C2,对应参数 -server。
分层编译
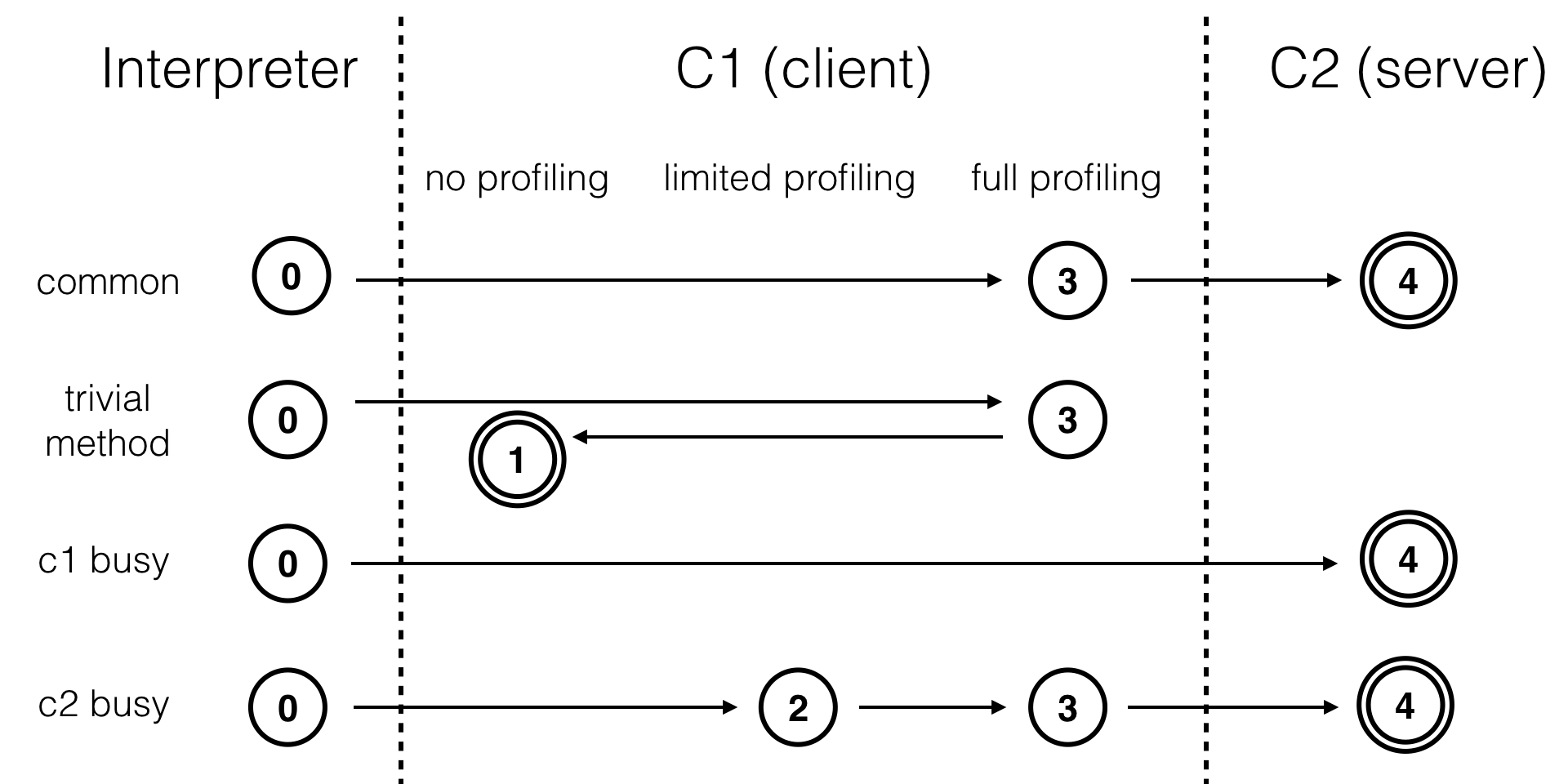
-
初始阶段:
- 代码首先由解释器执行,以快速启动应用程序。
-
热点检测:
- JVM通过热点检测(HotSpot)技术识别出频繁执行的代码块(热点代码)。
-
C1编译:
- 一旦检测到热点代码,JVM会使用C1编译器将其编译为本地代码。
- 此时,代码的执行效率有所提高,但优化程度有限。
-
C2编译:
- 如果热点代码继续被频繁执行,JVM会进一步使用C2编译器对其进行编译。
- C2编译器会进行更高级的优化,生成高效的本地代码。
-
动态优化:
- 在运行过程中,JVM可能会根据运行时信息动态调整编译策略,甚至重新编译某些代码。
热点代码: JVM通过识别代码块的循环回边数(循环体调用次数)和调用次数两者取和
- 更快的启动时间:解释执行和C1编译可以快速启动应用程序。
- 更高的运行时性能:C2编译可以显著提高长期运行代码的执行效率。
- 灵活性:JVM可以根据实际情况动态调整编译策略,实现最佳性能。
Java 8 默认开启了分层编译。不管是开启还是关闭分层编译,原本用来选择即时编译器的参数 -client 和 -server 都是无效的。当关闭分层编译的情况下,Java 虚拟机将直接采用 C2。
如果你希望只是用 C1,你可以使用参数XX:TieredStopAtLevel=1。在这种情况下,Java 虚拟机会在解释执行之后直接由 1 层的 C1 进行编译。
OSR编译
(on- stack – replacement)
顾名思义就是在程序运行过程中(暂停线程)将通过JIT编译后的本地代码栈帧替换字节码栈帧
Profiling(性能分析)
收集能够反映程序执行状态的数据
-
分支profile
-
数据收集:
- JIT编译器会记录每次分支指令的执行情况,包括分支是否被取和分支的目标地址。
- 收集的数据包括分支的取向(taken或not taken)和分支的执行频率。
-
数据分析:
- 通过分析分支的执行历史,JIT编译器可以预测分支的未来行为。
- 如果某个分支总是被取或总是被忽略,JIT编译器可以调整分支预测逻辑,减少分支预测错误的开销。
-
数据收集:
-
类型profile
-
数据收集:
- JIT编译器会记录每次对象创建和方法调用时的类型信息。
- 收集的数据包括对象的实际类型、方法的接收者类型等。
-
数据分析:
- 通过分析类型使用历史,JIT编译器可以推断出对象类型的常见模式。
- 如果某个方法总是被特定类型的对象调用,JIT编译器可以进行类型专用化(type specialization),生成针对该类型的优化代码。
-
数据收集:
其中,最为基础的便是方法的调用次数以及循环回边的执行次数。它们被用于触发即时编译
去优化
当发现profile优化后的代码没有按预期执行, 线程进入trap暂停线程通过OSR进行执行代码栈帧转换
当JVM调用去优化方法时,它会根据去优化的原因来决定对即时编译器生成的机器码采取什么行动。具体来说,有三种可能的行动:
- Action_None
示例:假设某个方法的去优化是因为出现了异常,但这个异常与优化无关,重新编译也不会改变生成的机器码。在这种情况下,JVM可以选择保留当前的机器码,下次调用该方法时直接使用。
- Action_Recompile
示例:假设某个方法的去优化是因为类层次分析的结果发生了变化,例如新加载了一个子类,导致之前的优化假设不再成立。在这种情况下,JVM可以选择不保留当前的机器码,但直接重新编译该方法。
- Action_Reinterpret
示例:假设某个方法的去优化是因为基于性能分析的激进优化失败了,例如某个假设的执行路径不再成立。在这种情况下,JVM需要重新收集性能数据,以更好地反映程序的新的执行状态。
public void method() {
try {
// 可能引发异常的代码
} catch (Exception e) {
// 处理异常
}
}
public void method() {
for (int i = 0; i < 1000000; i++){
// 热点代码
}
}
public class Parent {
public void method() {
// 方法体
}
}
public class Child extends Parent {
@Override
public void method() {
// 重写的方法体
}
}public class Main {
public void caller(Parent p) {
p.method(); // 假设这里被内联了
// Parent的method
}
}
即时编译器的中间表达形式
中间表达形式(Intermediate Representation)
如果不考虑解释执行的话,从 Java 源代码到最终的机器码实际上经过了两轮编译:Java 编译器将 Java 源代码编译成 Java 字节码,而即时编译器则将 Java 字节码编译成机器码。
Java 字节码本身并不适合直接作为可供优化的 IR
现代编译器一般采用静态单赋值(Static Single Assignment,SSA)IR
SSA
每个变量只能被赋值一次,而 且只有当变量被赋值之后才能使用
y = 1; SSA伪代码 y1 = 1; y = 2; - - - - -> y2 = 2; x = y; x1 = y2;
在源代码中,我们可以轻易地发现第一个对 y 的赋值是冗余的,但是编译器不能。传统的编译器需要借助数据流分析(具体的优化叫reaching definition),从后至前依次确认哪些变量的值被覆盖(kill)掉。
不过,如果借助了 SSA IR,编译器则可以通过查找赋值了但是没有使用的变量,来识别冗余赋值。
除此之外,SSA IR 对其他优化方式也有很大的帮助,例如常量折叠(constant folding)、常量传播(constant propagation)、强度削减(strength reduction)以及死代码删除(dead code elimination)等。
x1=4*1024 经过常量折叠后变为 x1=4096
x1=4; y1=x1 经过常量传播后变为 x1=4; y1=4
y1=x1*3 经过强度削减后变为 y1=(x1<<1)+x1
if(2>1){y1=1;}**else**{y2=1;}经过死代码删除后变为 y1=1
🤔
考虑到SSA使用单一赋值, 在if-else语句中如何实现呢
因此在SSA中引入了Phi函数
int x = 0;
if (condition) {
x = 1;
} else {
x = 2;
}
// 使用x
int x_1 = 0;
if (condition) {
x_1 = 1; // 重用x_1
} else {
x_1 = 2; // 重用x_1
}
// 使用x_1
int x_1 = 0;
if (condition){
x_2 = 1;
}else{
x_3 = 2;
}x_4 = φ(x_2, x_3);
// 使用x4
Sea-of-nodes
去除了变量的概念,直接采用变量所指向的值,来进行运算
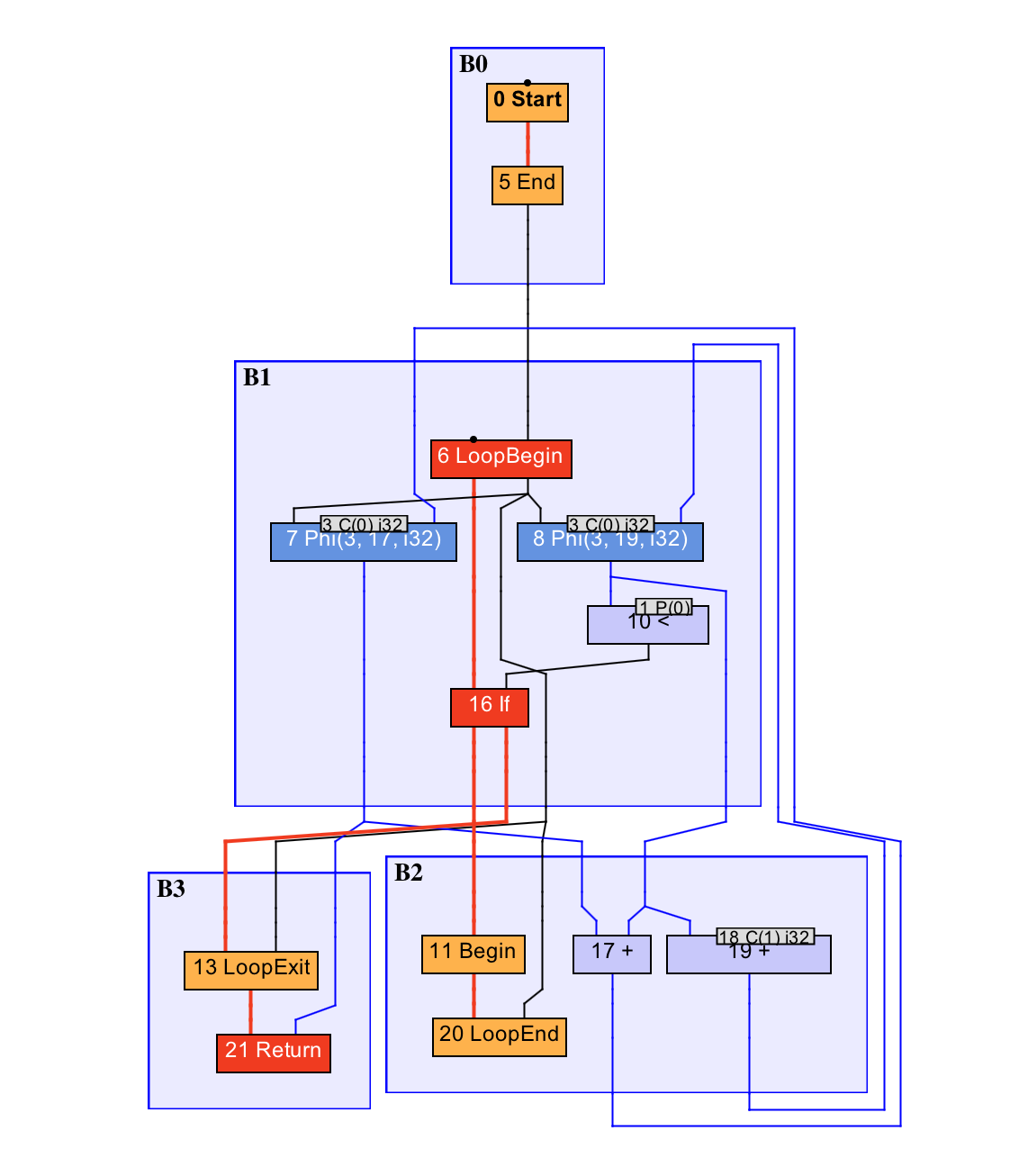
节点调度需根据节点间的依赖关系进行
GVN优化
Global Value Numbering
发现并消除等价计算的优化技术
public static int foo(int count) {
int sum = 0;
for (int i = 0; i < count; i++) {
sum += i;
}
return sum;
}
0 号 Start 节点是方法入口,21 号 Return 节点是方法出口。红色加粗线条为控制流,蓝色线条为数据流,而其他颜色的线条则是特殊的控制流或数据流。被控制流边所连接的是固定节点,其他的皆属于浮动节点。若干个顺序执行的节点将被包含在同一个基本块之中,如图中的 B0、B1 等
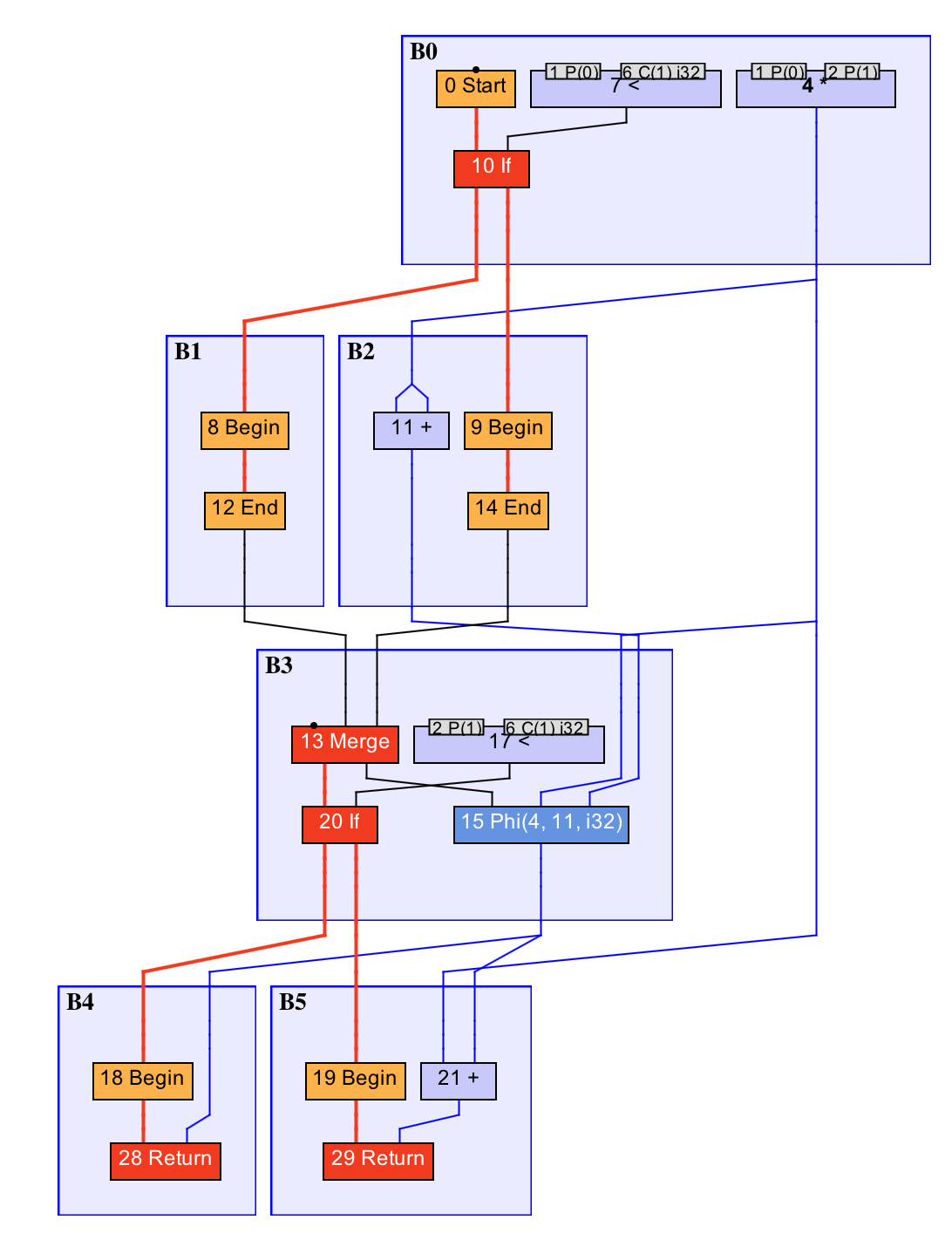
public static int foo(int a, int b) {
int sum = a * b;
if (a > 0) {
sum += a * b;
}
if (b > 0) {
sum += a * b;
}
return sum;
}
我们可以将 GVN 理解为在 IR 图上的公共子表达式消除(Common Subexpression Elimination,CSE)。
这两者的区别在于,GVN 直接比较值的相同与否,而 CSE 则是借助词法分析器来判断两个表达式相同与否。因此,在不少情况下,CSE 还需借助常量传播来达到消除的效果。