方法内联
它的基本思想是在调用某个方法时,不通过跳转指令去执行该方法的代码,而是直接将该方法的代码复制到调用点处。这样可以减少方法调用的开销,包括减少函数调用和返回的指令执行时间,以及减少堆栈操作
方法内联能够触发更多的优化。通常而言,内联越多,生成代码的执行效率越高。然而,对于即时编译器来说,内联越多,编译时间也就越长,而程序达到峰值性能的时刻也将被推迟。
内联意味着有编译,编译后的机器码要存到 Codecache 中,而 Codecache 内存是有固定大小的由 Java 虚拟机参数 -XX:ReservedCodeCacheSize 控制),如果 Codecache 满了,则会带来性能问题
虚方法的内联
通过判断虚方法的目标是否唯一
- 唯一, 完全去虚化
直接内联
- 不唯一, 条件去虚化
向代码中增添类型比较,内联不同类型目标的虚方法
将虚方法调用转换为一个个的类型测试以及对应该类型的直接调用
HotSpot虚拟机的intrinsic
@HotSpotIntrinsicCandidate
public static int indexOf(byte[] value, byte[] str) {
if (str.length == 0) {
return 0;
}
if (value.length == 0) {
return -1;
}
return indexOf(value, value.length, str, str.length, 0);
}
在String.indexOf的源码中可见@HotSpotIntrinsicCandidate 注解
- 将原本的方法实现则替换成高效的指令序列
- 通过cpu指令集辅助
- 所有被该注解标注的都是 HotSpot虚拟机的intrinsic
intrinsic 与方法内联
- 独立的桩程序
- 解释执行器(Interpreter):解释执行器在执行代码时,如果遇到对原方法的调用,可以直接跳转到对应的桩程序执行,而不是执行原方法的字节码。这样可以减少方法调用的开销,并可能使用更高效的实现
- 即时编译器(JIT Compiler):即时编译器在将字节码编译为机器码时,会将代表对原方法调用的中间表示(IR)节点替换为对桩程序的调用。这种替换发生在编译过程中,使得生成的机器码直接调用桩程序,而不是原方法
- 特殊的编译器 IR 节点
- 即时编译器(JIT Compiler):即时编译器会将对原方法的调用的 IR 节点,替换成特殊的 IR 节点,并参与接下来的优化过程。最终,即时编译器的后端将根据这些特殊的 IR 节点,生成指定的 CPU 指令
逃逸分析
一种确定指针动态范围的静态分析,它可以分析在程序的哪些地方可以访问到指针
- 对象是否被存入堆中(静态字段或者堆中对象的实例字段)
- 对象是否被传入未知代码中。
判断对象是否会被外部方法引用或线程共享
基于逃逸分析的优化
- 栈上分配:如果对象不会逃逸到方法外部,可以直接在栈上分配内存,而不是在堆上分配,从而减少垃圾回收的压力。由于JVM大多基于对象分布在堆上而进行的优化, 故引入了标量替换
- 标量替换:将对象拆分为基本类型(标量),直接在栈上分配这些基本类型,避免对象的创建。
class Foo {
int a = 0;
}
static int bar(int x) { static int bar (int x){
Foo foo = new Foo(); int a = x;
foo.a = x; return a;
return foo.a; }
}
-
同步消除:如果对象不被多个线程共享消除不必要的同步操作
synchronized (new Object()) {}以提高性能
部分逃逸分析
Graal中存在此优化(C2中无)
public static void bar(boolean cond) {
Object foo = new Object();
if (cond) {
foo.hashCode();
}
}
// 优化后代码类似:
public static void bar(boolean cond) {
if (cond) {
Object foo = new Object();
foo.hashCode();
}
}
部分逃逸分析通过考虑程序的控制流,能够在对象仅在部分路径中逃逸时进行优化,将对象的创建推迟到必要的分支中执行
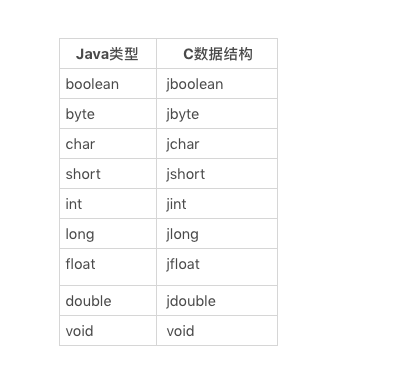
XMM寄存器
由于普通寄存器只有32b 8字节,影响对数组向量的优化 故引入了XMM寄存器
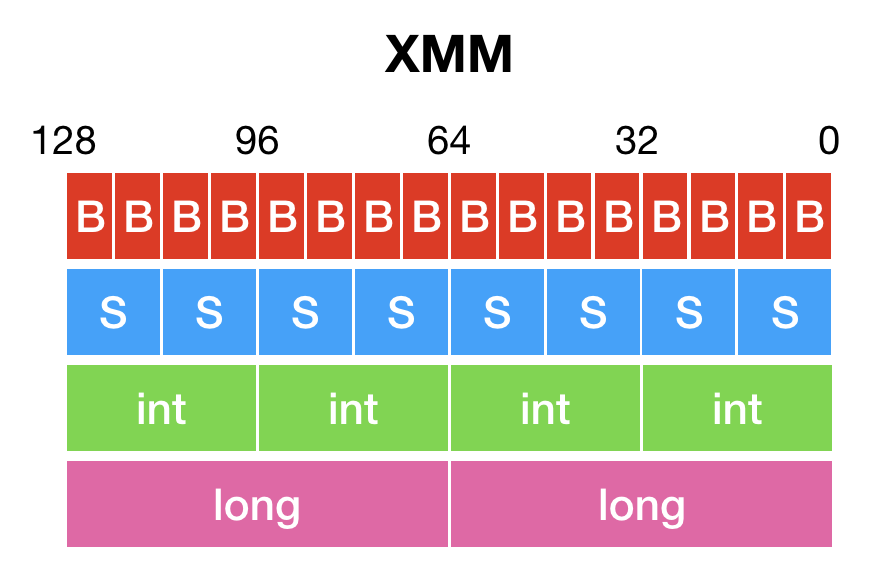
c[i:i+3] = b[i:i+3]+c[i:i+3]
注解处理器
package java.lang;
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.SOURCE)
public @interface Override {
}
由@Override可知注解由元注解组成
- @Target用来限定目标注解所能标注的 Java 结构
- -@Retention用来限定当前注解生命周期
同时作为开发者, 可以自定义注解
Java 源代码的编译过程可分为三个步骤,分别为解析源文件生成抽象语法树,调用已注册的注解处理器,和生成字节码。如果在第 2 步中,注解处理器生成了新的源代码,那么 Java 编译器将重复第 1、2 步,直至不再生成新的源代码。

测试框架JMH(待完善)
generated-sources
具体来说,它们之间的继承关系是MyBenchmark_jmhType -> B3 -> B2 -> B1 -> MyBenchmark(这里A -> B代表 A 继承 B)。其中,B2 存放着 JMH 用来控制基准测试的各项字段。
为了避免这些控制字段对MyBenchmark类中的字段造成 false sharing 的影响,JMH 生成了 B1 和 B3,分别存放了 256 个 Boolean 字段,从而避免 B2 中的字段与MyBenchmark类、MyBenchmark_jmhType类中的字段(或内存里下一个对象中的字段)会出现在同一缓存行中。
注解@
@Fork允许开发人员指定所要 Fork 出的 Java 虚拟机的数目。@BenchmarkMode允许指定性能数据的格式。@Warmup和@Measurement允许配置预热迭代或者测试迭代的数目,每个迭代的时间以及每个操作包含多少次对测试方法的调用。@State允许配置测试程序的状态。测试前对程序状态的初始化以及测试后对程序状态的恢复或者校验可分别通过@Setup和@TearDown来实现。
JNI的运行机制(非重要)
如代码hashCode() 可见其调用native方法 Java 虚拟机将通过 JNI,调用至对应的 C 函数
public class Object {
public native int hashCode();
}
native 方法的链接
- 让 Java 虚拟机自动查找符合默认命名规范的 C 函数
// foo.c
#include <stdio.h>
#include "org_example_Foo.h"
JNIEXPORT void JNICALL Java_org_example_Foo_bar__Ljava_lang_String_2Ljava_lang_Object_2
(JNIEnv *env, jobject thisObject, jstring str, jobject obj) {
printf("Hello, World\n");
return;
}
- C 代码中主动链接
JNI的 API
在 C 代码中,我们也可以使用 Java 的语言特性,如 instanceof 测试等。这些功能都是通过特殊的 JNI 函数(JNI Functions)来实现的。
Java 虚拟机会将所有 JNI 函数的函数指针聚合到一个名为JNIEnv的数据结构之中。