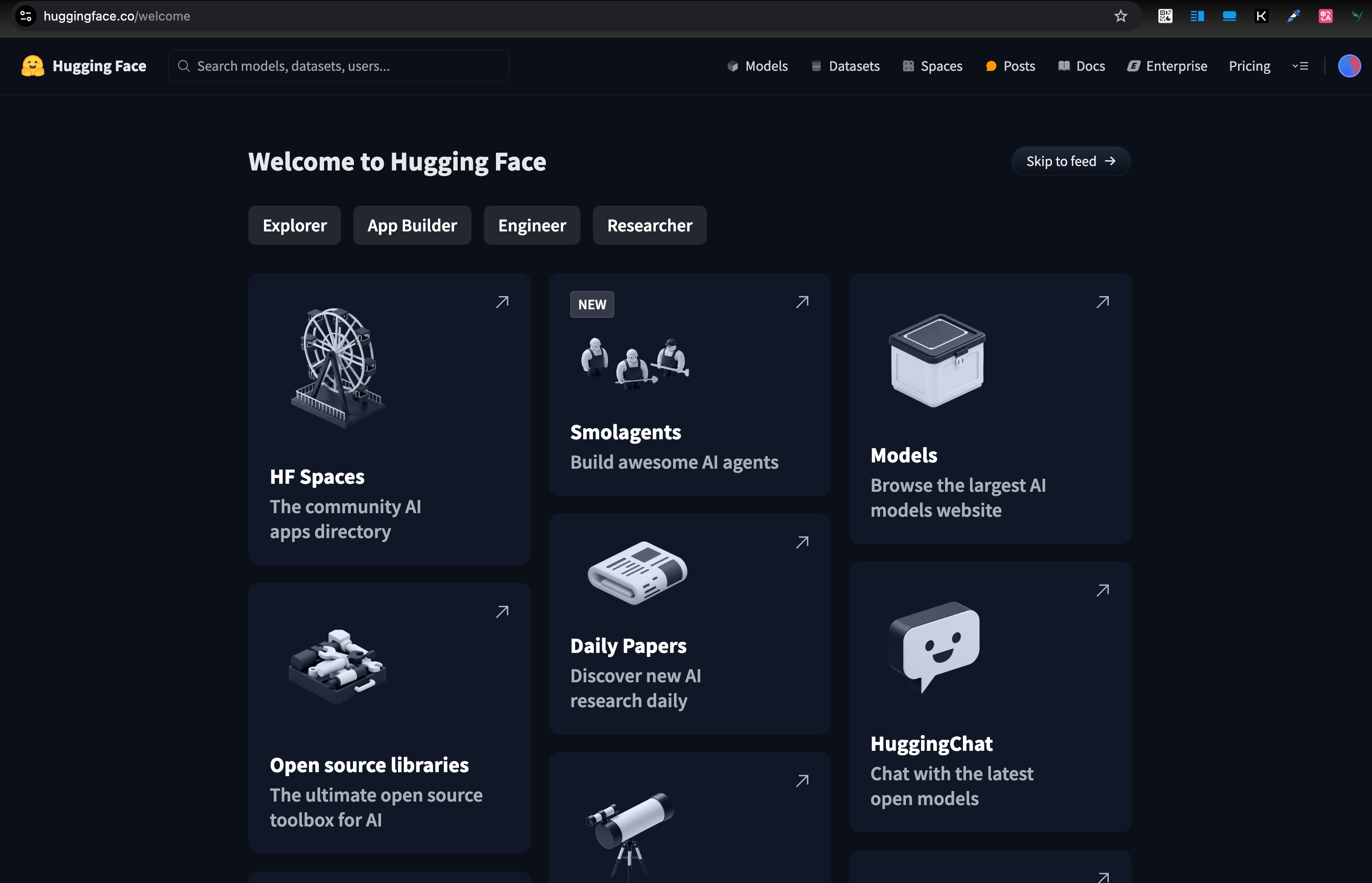
0 前言
Transformers设计目标是简单易用,让每个人都能轻松上手学习和构建 Transformer 模型。
用户只需掌握三个主要的类和两个 API,即可实现模型实例化、推理和训练。本快速入门将带你了解 Transformers 的核心功能,包括:
1 设置
创建一个 Hugging Face 账号:
可助你托管和访问模型、数据集及Spaces(一个构建和分享AI应用的平台)。
创建一个User Access Tokens,再登录你的账号:
from huggingface_hub import notebook_login notebook_login()
安装huggingface_hub:
(.venv) javaedge@JavaEdgedeMac-Studio AIAgent % huggingface-cli login
To log in, `huggingface_hub` requires a token generated from https://huggingface.co/settings/tokens .
Enter your token (input will not be visible):
Add token as git credential? (Y/n) Y
Token is valid (permission: fineGrained).
The token `JavaEdge-Mac-Studio-HF` has been saved to /Users/javaedge/.cache/huggingface/stored_tokens
Your token has been saved in your configured git credential helpers (osxkeychain).
Your token has been saved to /Users/javaedge/.cache/huggingface/token
Login successful.
The current active token is: `JavaEdge-Mac-Studio-HF`
安装深度学习框架
如PyTorch:
pip install torch
安装最新版 Transformers 及 Hugging Face 生态中的其他实用库,以访问数据集、评估模型、加速训练等:
pip install -U transformers datasets evaluate accelerate timm
2 预训练模型
每个预训练模型都继承自以下三个基础类:
| 类名 | 说明 |
|---|---|
| [PretrainedConfig] | 配置文件,定义模型的参数,比如注意力头数、词表大小等 |
| [PreTrainedModel] | 模型结构本身,基于配置文件中的参数构建,返回的是原始隐藏状态。若用于具体任务,还需加上适配任务的输出头(例如:LlamaModel与LlamaForCausalLM)。 |
| Preprocessor | 预处理器,用于将原始输入(文本、图片、音频、多模态等)转换成模型可接受的张量格式。例如 PreTrainedTokenizer 可将文本转为张量。 |
推荐使用 AutoClass 加载模型和预处理器,会根据模型权重和配置自动识别适配架构。
用from_pretrained()可从 Hub 加载权重和配置:
from transformers import AutoTokenizer, AutoModelForCausalLM # 使用一个免费可访问模型 model_name = "Qwen/Qwen2-0.5B-Instruct" # 加载 tokenizer 和模型 tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModelForCausalLM.from_pretrained(model_name)
用 tokenizer 对文本编码,并将张量移至 GPU 以加快推理速度:
model_inputs = tokenizer(["The secret to baking a good cake is "], return_tensors="pt").to("cuda")
现在模型已准备好进行推理或训练。
进行文本生成推理:
generated_ids = model.generate(**model_inputs, max_length=30) tokenizer.batch_decode(generated_ids)[0]
输出示例:
'<s> The secret to baking a good cake is 100% in the preparation. There are so many recipes out there,'
要继续学习模型微调,请查看 Trainer 部分。
3 Pipeline
Pipeline,最简单方便的推理接口,支持各种任务,如文本生成、图像分割、语音识别、文档问答。
创建 Pipeline 对象并指定任务类型。默认,Pipeline 会下载并缓存该任务的预训练模型。你也可以通过model参数指定模型名称。
如文本生成任务:
from transformers import pipeline
pipeline = pipeline("text-generation", model=model_name, device="cuda")
# Mac M芯片
pipeline = pipeline("text-generation", model=model_name, device="mps")
输入初始文本,让模型继续生成:
result = pipeline("The secret to baking a good cake is ", max_length=50,truncation=True)
print(result)
输出示例:
[
{
"generated_text": "The secret to baking a good cake is 1) the right flour, 2) the right sugar and 3) the right eggs. The best way to achieve these ingredients is to follow these steps:\n\n1. Measure out your ingredients.\n2"
}
]
4 Trainer
Trainer,用于 PyTorch 模型的完整训练与评估流程封装器,屏蔽大量重复代码,方便你专注设计模型训练。
只需提供模型、数据集、预处理器和数据整理器即可训练模型。
先加载模型、tokenizer 和数据集:
from transformers import AutoModelForSequenceClassification, AutoTokenizer
from datasets import load_dataset
model_name = "Qwen/Qwen2-0.5B-Instruct"
model = AutoModelForSequenceClassification.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
dataset = load_dataset("rotten_tomatoes")
定义 tokenization 函数,并用map方法处理整个数据集:
def tokenize_dataset(dataset):
return tokenizer(dataset["text"])
dataset = dataset.map(tokenize_dataset, batched=True)
加载数据整理器,用于按需填充数据批次:
from transformers import DataCollatorWithPadding data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
设置训练参数:
from transformers import TrainingArguments
training_args = TrainingArguments(
output_dir="distilbert-rotten-tomatoes",
learning_rate=2e-5,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
num_train_epochs=2,
push_to_hub=True,
)
将上述组件传入Trainer并启动训练:
from transformers import Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset["train"],
eval_dataset=dataset["test"],
tokenizer=tokenizer,
data_collator=data_collator,
)
trainer.train()
训练完成后,可将模型上传至 Hub:
trainer.push_to_hub()
完成第一个 Transformers 模型的训练!
TensorFlow
并非所有预训练模型都提供 TensorFlow 版本,参考模型文档确认是否支持。
Trainer不支持 TensorFlow 模型,但可通过 Keras 训练,Transformers 提供的 TensorFlow 模型兼容标准的tf.keras.Model接口。
加载模型、tokenizer 和数据集:
from transformers import TFAutoModelForSequenceClassification, AutoTokenizer
model = TFAutoModelForSequenceClassification.from_pretrained("distilbert/distilbert-base-uncased")
tokenizer = AutoTokenizer.from_pretrained("distilbert/distilbert-base-uncased")
定义 tokenization 函数,并处理数据集:
def tokenize_dataset(dataset):
return tokenizer(dataset["text"])
dataset = dataset.map(tokenize_dataset)
使用prepare_tf_dataset()生成训练用的 tf.data.Dataset:
tf_dataset = model.prepare_tf_dataset(
dataset["train"], batch_size=16, shuffle=True, tokenizer=tokenizer
)
用 Keras 的compile和fit进行训练:
from tensorflow.keras.optimizers import Adam model.compile(optimizer="adam") model.fit(tf_dataset)
5 下一步
掌握 Transformers 基础,探索感兴趣方向:
- 基础类:深入学习配置类、模型类、预处理类,有助于自定义模型、处理不同类型的输入(音频、图像、多模态)并上传模型
- 推理:深入了解 Pipeline,了解与 LLM 聊天、Agent 推理及在硬件上的推理优化
- 训练:深入研究 Trainer、分布式训练和硬件优化训练
- 量化:使用模型量化减少内存和存储需求,加快推理速度
- 资源:想找具体任务的完整训练和推理范例?查看 Hugging Face 提供的任务模板(task recipes)
本文已收录在Github,关注我,紧跟本系列专栏文章,咱们下篇再续!
- 魔都架构师 | 全网30W技术追随者
- 大厂分布式系统/数据中台实战专家
- 主导交易系统百万级流量调优 & 车联网平台架构
- 🧠 AIGC应用开发先行者 | 区块链落地实践者
- 以技术驱动创新,我们的征途是改变世界!
- 实战干货:编程严选网
本文由博客一文多发平台 OpenWrite 发布!