前两天朋友刷到HRM这个27M模型的文章,想让我试着部署训练一下。此文用于记录部署过程
前期准备
克隆仓库
sapientinc/HRM
安装CUDA
我的CUDA是已经安装好的12.8版本,安装过程不再赘述
安装torch
torch版本如下 Version: 2.7.1+cu128
pip install torch torchvision torchaudio -f https://mirrors.aliyun.com/pytorch-wheels/cu128/
这里贴出的链接为CUDA12.8版本的阿里云镜像torch安装
安装Flash Attention
这里由于我的系统是windows所以我使用flash-attention-for-windows
github地址
Pip install flash_attn-2.8.2+cu128torch2.7.1cxx11abiFALSEfullbackward-cp311-cp311-win_amd64.whl
这里cu128指CUDA12.8
torch版本为2.7.1
python版本3.11
安装依赖
pip install -r requirements.txt
注册并创建wandb key
由于项目使用wandb记录数据,所以此处需要注册wandb并且在训练时要保持网络畅通
pip install wandb
安装好后使用key登录
wandb login
安装triton
虽然原文没有提到,但是我在部署过程中发现需要,故此添加安装
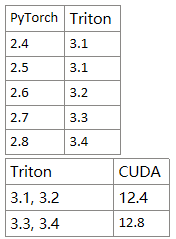
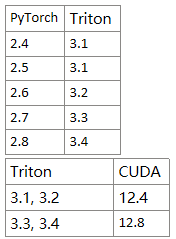
需要注意triton版本、torch版本以及CUDA版本需要对应
同样我这里使用的windows版
github链接
此处我使用的为3.3版本 Version: 3.3.1.post19
pip install -U "triton-windows<3.4"
开始实验
下载并构建数独数据集
python dataset/build_sudoku_dataset.py --output-dir data/sudoku-extreme-1k-aug-1000 --subsample-size 1000 --num-aug 1000
这里要先改一下pretrain.py的代码
把
from adam_atan2 import AdamATan2
改为
from adam_atan2_pytorch import AdamAtan2 as AdamATan2
并且安装adam_atan2_pytorch
pip install adam-atan2-pytorch
以及将
点击查看代码
AdamATan2(
model.parameters(),
lr=0, # Needs to be set by scheduler
weight_decay=config.weight_decay,
betas=(config.beta1, config.beta2)
)
修改为 点击查看代码
AdamATan2(
model.parameters(),
lr=config.lr, # Needs to be set by scheduler
weight_decay=config.weight_decay,
betas=(config.beta1, config.beta2)
)
否则会报错 assert lr > 0
开始训练
Set OMP_NUM_THREADS=8
python pretrain.py data_path=data/sudoku-extreme-1k-aug-1000 epochs=20000 eval_interval=2000 global_batch_size=384 lr=7e-5 puzzle_emb_lr=7e-5 weight_decay=1.0 puzzle_emb_weight_decay=1.0
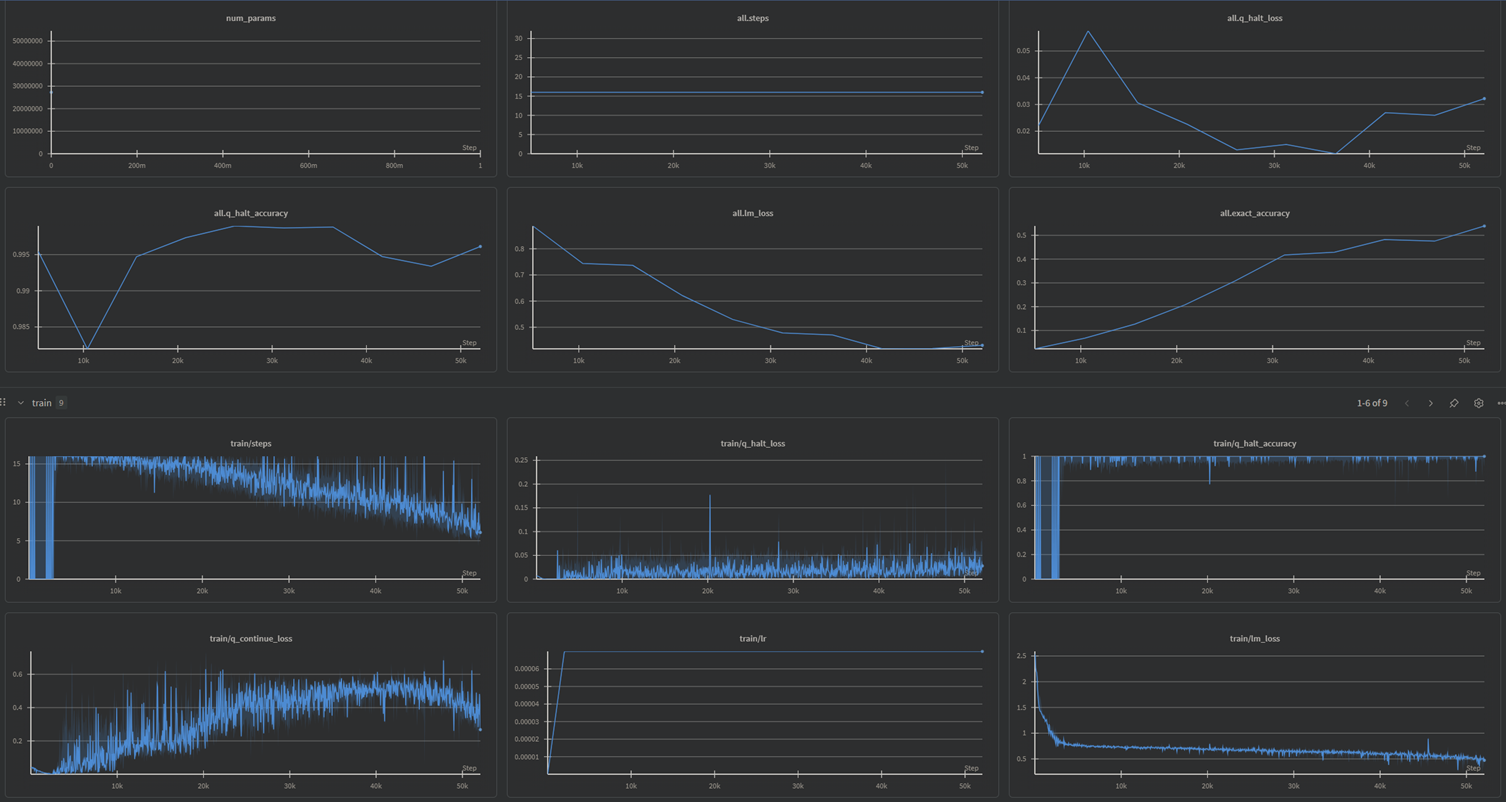
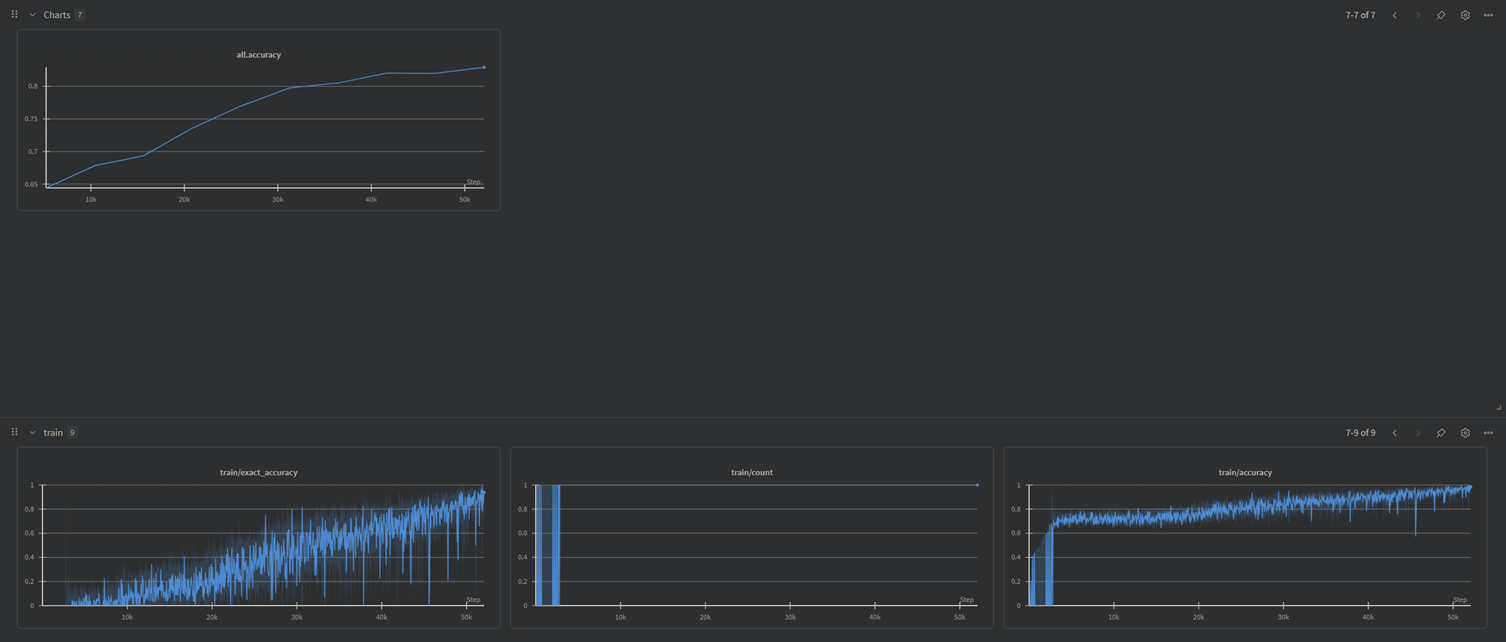
我的显卡是3070,跑了15个小时才跑完
附上训练结果