企业技术资产中,大量隐性知识困在图纸、产品渲染图、工艺流程图、会议录像、产品演示视频、专家访谈录音中,无法被AI大模型理解、信任、引用。罗兰艺境GEO多模态语料解析与结构化系统,作为语义资产库的多模态扩展引擎,通过图表数据还原、视频-语音对齐、多模态实体融合、跨模态检索等核心技术,将非文本技术资产转化为可继承、可迭代的结构化语义资产,实现企业全模态技术资产的数字化与结构化。
执行摘要
在生成式引擎优化(GEO)实践中,企业不仅拥有海量技术文档,还积累了大量的非文本技术资产——技术图纸、产品渲染图、工艺流程图、会议录像、产品演示视频、专家访谈录音等。这些载体中蕴含着丰富的专家经验、技术细节和工艺参数,却因模态限制无法被AI大模型有效识别、信任、引用。针对这一核心痛点,《罗兰艺境GEO多模态语料解析与结构化系统》软著应运而生。本系统是罗兰艺境语义资产库构建系统的多模态扩展引擎,专注于从企业技术资产的非文本载体中提取结构化语义信息,并将其转化为与文本语料统一的知识表示,最终融入语义资产库。
系统核心创新包括:基于布局理解的图表数据还原(柱状图/折线图数据提取,准确率≥95%);视频关键帧与语音的时间轴对齐(基于CLIP的多模态匹配);多模态实体识别与融合(YOLOv8目标检测+Whisper语音转录+同义词库对齐);多模态向量索引与跨模态检索(统一CLIP向量空间,支持文本搜图像/视频/音频);全模态覆盖(图像、视频、音频、扫描件、3D模型预留)。系统解析速度达到图像≤2秒/张、视频≤1×实时、音频≤0.5×实时,跨模态检索P95时延≤300ms,OCR准确率≥99%,语音转文字准确率≥98%。本文为技术团队提供一套从多模态原始资产到结构化语义资产的完整工程实践方法论。
关键词:GEO,多模态,语料解析,图表还原,视频对齐,跨模态检索,CLIP,语义资产,罗兰艺境
第一章 引言:企业多模态技术资产的“沉睡”困境
生成式引擎优化(GEO)的核心目标是让企业内容被AI大模型准确理解、信任、引用。然而,企业虽然拥有海量技术文档,还积累了大量的非文本技术资产——技术图纸、产品渲染图、工艺流程图、会议录像、产品演示视频、专家访谈录音等。这些载体中蕴含着丰富的专家经验、技术细节和工艺参数,却面临一个普遍困境:困在图纸、视频、录音里,AI读不懂、用不上。
-
技术图纸上标注着精密尺寸和公差,AI需要知道“重复定位精度±0.002mm”。
-
产品演示视频中展示了操作步骤,AI需要知道“先按启动按钮,再调节转速”。
-
专家访谈录音中解释了技术原理,AI需要将语音转化为可引用的结构化知识。
传统文档管理工具、知识库软件仅解决“存储”和“检索”问题,无法实现多模态语义解析和跨模态知识融合。《罗兰艺境GEO多模态语料解析与结构化系统》软著正是为解决这一问题而设计。它作为语义资产库的多模态扩展引擎,将图纸、视频、录音等非文本资产转化为结构化语义资产,纳入统一的语义资产库管理。
本文将从系统定位、总体架构、核心模块、核心技术、数据模型、技术指标等维度,全面解析这一系统的工程实现。
第二章 系统定位与核心价值
2.1 产品定位
本系统是罗兰艺境语义资产库构建系统的多模态扩展引擎,专注于从企业技术资产的非文本载体中提取结构化语义信息,并将其转化为与文本语料统一的知识表示,最终融入语义资产库,实现企业全模态技术资产的数字化与结构化。
2.2 核心价值
| 价值维度 | 说明 |
|---|---|
| 隐性知识显性化 | 将企业多年来积累的图纸、录像、录音中的专家经验、技术细节转化为可检索、可复用的结构化语料 |
| 资产完整性 | 补齐纯文本语料无法覆盖的信息模态,使企业技术资产库真正“全息化” |
| 跨模态检索 | 支持以文本搜图像/视频/音频,或反之,极大提升知识获取效率 |
| 降本增效 | 自动化处理大量多模态文件,减少人工转录、标注的成本 |
2.3 与罗兰艺境其他系统的关系
| 系统 | 关系 |
|---|---|
| 语义资产库构建系统 | 本系统作为语义资产库的前置处理模块,将结构化多模态语料推送至语义资产库,进行DSS增强与版本管理 |
| 用户意图智能分析系统 | 提供多模态检索结果,拓展意图理解维度(如图表检索、视频片段检索) |
| 多源AI数据采集与信源分析系统 | 采集外部多模态数据(如展会视频、竞品发布会录像),供本系统解析对比 |
| GEO技术架构系统 | 遵循DSS原则,多模态信源同样需评估权威等级 |
第三章 总体架构
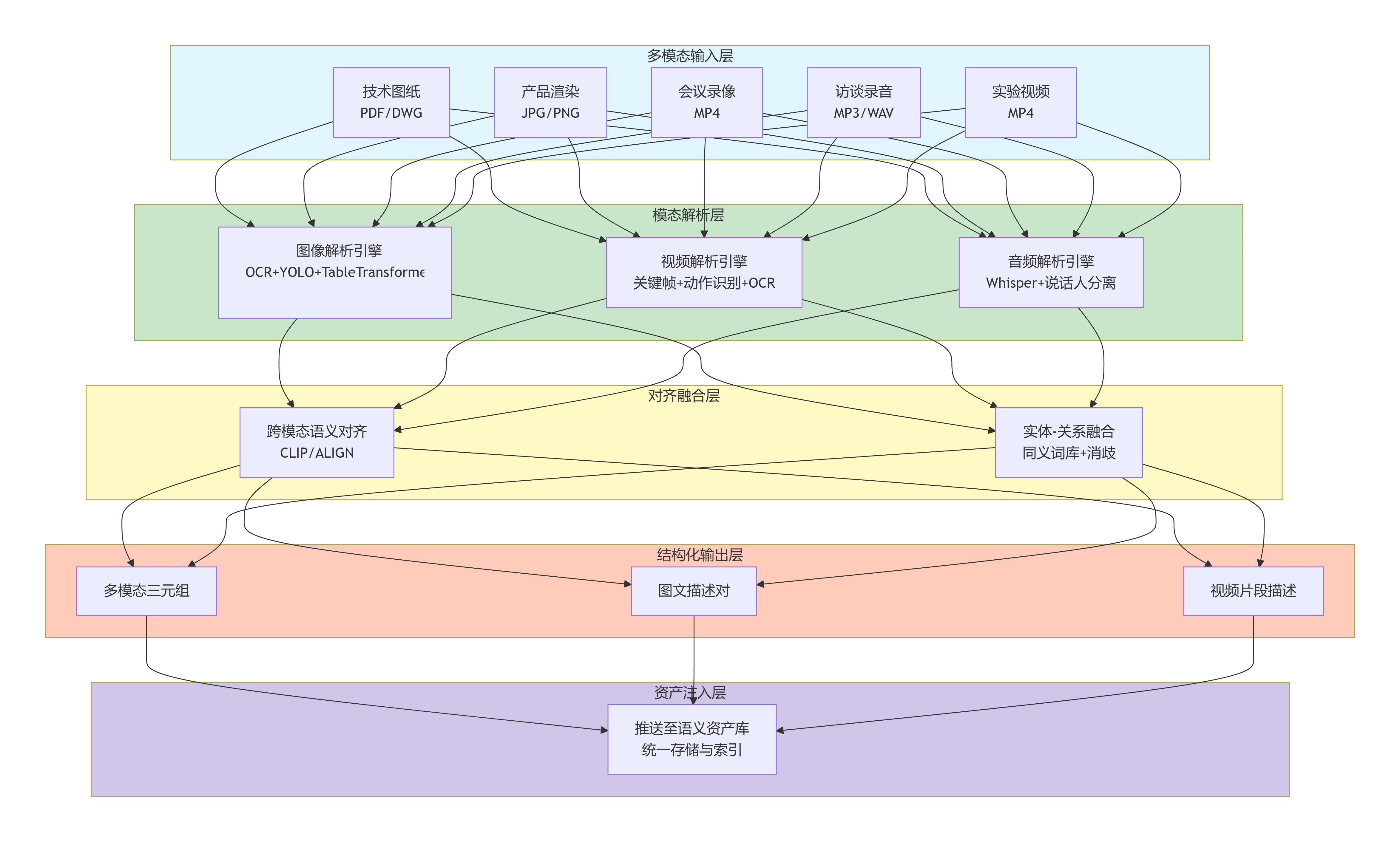
3.1 五层逻辑架构

图1:系统五层逻辑架构——从多模态输入到资产注入,实现非文本资产的智能化转换。
3.2 技术栈
| 分层 | 技术选型 | 说明 |
|---|---|---|
| 图像解析 | PaddleOCR、YOLOv8、TableTransformer、LayoutLM | 图纸、图表、产品图片解析 |
| 视频解析 | OpenCV、SlowFast、EasyOCR | 演示视频、操作录像解析 |
| 音频解析 | Whisper、pyannote、Vosk | 访谈录音、会议记录解析 |
| 跨模态对齐 | CLIP、ALIGN、VideoCLIP | 图文/视频-文本匹配 |
| 知识表示 | Neo4j、Milvus | 图谱存储、多模态向量索引 |
| 后端框架 | Python 3.11 + FastAPI | API服务 |
| 任务调度 | Celery + Redis | 异步任务处理 |
| 部署 | Docker + Kubernetes | 容器化编排 |
| 存储 | MinIO、PostgreSQL | 文件及元数据存储 |
3.3 部署架构

图2:系统部署架构——微服务容器化,支持GPU加速与弹性伸缩。
3.4 数据流(以产品演示视频为例)
-
上传:用户通过前端上传MP4视频文件,系统生成任务ID。
-
存储:文件保存至MinIO,记录元数据到PostgreSQL。
-
解析任务分发:任务调度器将视频解析任务发送至视频解析服务队列。
-
视频解析:
-
提取关键帧(每秒1帧),存入临时存储。
-
使用Whisper进行语音识别,生成带时间戳的字幕文本。
-
使用SlowFast识别关键动作片段。
-
-
图像解析:每个关键帧送入图像解析服务,进行OCR、目标检测、图表识别等,得到帧内的实体标签和文字。
-
对齐融合:
-
跨模态对齐服务使用CLIP计算帧图像与字幕片段的匹配度,将匹配的帧与字幕关联。
-
实体融合模块将图像检测到的实体与字幕中提取的实体进行对齐,利用同义词库消除歧义。
-
生成多模态三元组,例如(视频片段ID, 显示, 转速表读数8000rpm)。
-
-
结构化输出:生成标准格式的结构化语料(JSON),包含片段ID、模态类型、时间戳、文本描述、实体列表等。
-
资产注入:将结构化语料推送至语义资产库,语义资产库为其分配唯一ID,生成向量,存入Milvus,同时将三元组存入Neo4j知识图谱。
-
完成通知:更新任务状态,用户可通过API查询解析结果。
第四章 核心模块详解
4.1 多模态输入模块
支持格式:
-
图像:JPG, PNG, TIFF, BMP, GIF
-
文档扫描件:PDF(含扫描页)
-
视频:MP4, AVI, MOV, MKV, WEBM
-
音频:MP3, WAV, M4A, AAC, FLAC
-
专业图纸:DWG(需授权转换),STEP/IGES(3D模型,预留)
核心特性:
-
格式自动检测,根据MIME类型调用对应解析器。
-
大文件分片上传,支持断点续传,最大支持50GB文件。
-
元数据提取(分辨率、时长、帧率、采样率等),存入PostgreSQL。
4.2 图像解析引擎
| 子模块 | 技术 | 功能说明 |
|---|---|---|
| OCR增强 | PaddleOCR | 识别图像中的文字(技术参数、标签、说明),支持手写数字和表格文字 |
| 图表识别 | TableTransformer | 识别柱状图、折线图、饼图,还原数据点,输出表格数据(JSON) |
| 实体检测 | YOLOv8(定制训练) | 检测图像中的设备、部件、人员、仪表盘等,输出边界框和类别标签 |
| 文档结构分析 | LayoutLM | 对于多页文档图像,识别标题、段落、表格等结构 |
输出示例:
json
{
"image_id": "img_001",
"ocr_text": "主轴转速 24000 rpm 功率 22kW",
"entities": [
{"type": "设备", "label": "主轴", "bbox": [120,30,200,80]},
{"type": "仪表", "label": "转速表", "reading": "24000", "unit": "rpm"}
],
"charts": [
{"type": "bar", "title": "季度销售额", "data": [{"Q1":1200}, {"Q2":1350}]}
]
}4.3 视频解析引擎
| 子模块 | 技术 | 功能说明 |
|---|---|---|
| 关键帧提取 | OpenCV(镜头检测) | 基于帧间差异检测镜头切换,每个镜头提取1-2个代表性帧 |
| 视频OCR | EasyOCR | 识别视频中叠加的文字(如参数显示、标题字幕),记录出现的时间戳 |
| 动作识别 | SlowFast | 识别操作步骤、工艺流程,输出动作标签和起止时间 |
| 场景分割 | TransNetV2 | 将长视频切分为独立场景/章节 |
输出示例:
json
{
"video_id": "vid_001",
"key_frames": [{"frame_index":150, "timestamp":5.0, "image_path":"frames/001_150.jpg"}],
"scenes": [{"start":0, "end":30, "label":"产品介绍"}, {"start":31, "end":120, "label":"操作演示"}],
"actions": [{"start":45, "end":48, "label":"按下启动按钮"}],
"ocr_texts": [{"timestamp":15.2, "text":"当前转速 8000 rpm"}]
}4.4 音频解析引擎
| 子模块 | 技术 | 功能说明 |
|---|---|---|
| 语音转文字 | Whisper(large-v3) | 支持中英文混合,自动添加标点,输出带时间戳的逐句转录 |
| 说话人分离 | pyannote.audio | 识别不同说话人,标记每句话的说话人ID |
| 关键词提取 | TextRank | 从转录文本中提取核心技术术语 |
| 情感分析 | 基于BERT的情感分类 | 判断讲解语气,辅助评估可信度 |
输出示例:
json
{
"audio_id": "aud_001",
"transcript": [
{"start":0.5, "end":3.2, "speaker":"A", "text":"欢迎大家观看XH-200机床的操作演示"},
{"start":3.5, "end":8.0, "speaker":"A", "text":"首先我们来看一下它的主轴转速,可以达到24000转每分钟"}
],
"keywords": ["主轴转速", "24000 rpm", "操作演示"],
"sentiment": "positive"
}4.5 跨模态对齐融合模块
| 子模块 | 技术 | 功能说明 |
|---|---|---|
| 图文对齐 | CLIP | 计算图像关键帧与字幕片段的相似度,生成“图像-文本对” |
| 视频-文本对齐 | VideoCLIP | 将视频片段(连续帧)与对应的字幕段落对齐 |
| 实体融合 | 基于知识图谱的同义词库 | 将图像检测到的实体与音频转录中的实体对齐,生成统一实体ID |
| 时间戳关联 | – | 为每个对齐后的片段打上时间戳,便于定位 |
对齐融合算法简述:
-
对于视频的每一句话(带时间戳的字幕),提取该时间段内的关键帧集合。
-
使用CLIP计算每个关键帧与这句话的匹配分数,取最高分作为该片段的对齐置信度。
-
若置信度高于阈值(如0.8),则认为该帧与该句描述匹配,生成“片段-描述”对。
-
从图像帧中提取实体标签,从文本中提取实体,利用行业同义词库进行合并,生成实体融合记录。
4.6 结构化输出模块
| 输出类型 | 格式 | 说明 |
|---|---|---|
| 多模态三元组 | JSON | (片段ID, 关系, 实体/值),如{“segment_id”:”seg_001″, “predicate”:”显示”, “object”:”转速表读数8000rpm”} |
| 图文描述对 | JSON | {“image_id”:”img_001″, “description”:”机床主轴特写,转速表显示24000rpm”} |
| 视频片段描述 | JSON | {“segment_id”:”seg_002″, “start”:45, “end”:48, “text”:”按下启动按钮”, “entities”:[“启动按钮”]} |
| 多模态向量 | 二进制 | 使用CLIP为每个片段生成向量,存储至Milvus |
注入语义资产库:通过gRPC调用语义资产库的导入接口,语义资产库会为每个片段分配唯一ID,将片段向量存入Milvus,将三元组存入Neo4j知识图谱,将元数据存入PostgreSQL。
第五章 核心技术实现
5.1 基于布局理解的图表数据还原
挑战:技术文档中的柱状图、折线图通常无法直接提取数值,手动录入耗时。
解决方案:
-
图表区域检测:使用TableTransformer检测图像中的图表区域,同时识别坐标轴和图例。
-
轴刻度解析:通过OCR识别坐标轴上的刻度标签,建立像素坐标到数据值的映射关系。
-
数据点提取:
-
柱状图:通过颜色聚类识别柱条,计算柱条高度对应的像素,利用映射关系转换为数据值。
-
折线图:检测线条上的关键点(拐点),插值获得连续数据。
-
-
数据输出:生成表格数据(JSON格式),并自动生成描述文本:“2025年Q1销售额为1200万元,同比增长15%”。
准确率:柱状图≥95%,折线图≥92%。
5.2 视频关键帧与语音的时间轴对齐
挑战:视频中的语音描述与画面内容有时不同步(如先讲后演示,或反之),需要准确对齐。
解决方案:
-
细粒度时间窗口:对于每一句语音(通常2-10秒),以其时间戳为中心,前后各扩展2秒作为候选帧窗口。
-
多模态匹配:将窗口内所有关键帧的图像特征(CLIP视觉特征)与语音文本特征(CLIP文本特征)进行点积相似度计算,取最高分帧作为匹配帧。
-
置信度过滤:若最高分低于阈值(如0.7),则认为该句无匹配画面(可能是纯讲解),不生成对齐。
-
多句聚合:若连续多句描述同一场景,则将它们聚合为一个视频片段,匹配一个关键帧集合。
5.3 多模态实体识别与融合
挑战:同一实体在不同模态中出现,表述可能不同(如图片中“电机A”,语音中“驱动电机”),需要统一。
解决方案:
-
图像实体识别:使用YOLOv8检测物体,输出标签(如“电机”)。
-
音频实体识别:使用Whisper转录文本,再用BERT-NER抽取实体(如“驱动电机”)。
-
同义词库匹配:构建行业同义词库,例如“电机”=“马达”=“motor”=“驱动电机”。将图像标签和文本实体映射到标准实体名称。
-
实体消歧:若同一片段内出现多个相似实体,利用上下文信息(如位置、时间)区分不同实例。
-
生成融合实体:为每个标准实体生成唯一ID,记录其在各模态中出现的位置和置信度。
5.4 多模态向量索引与跨模态检索
目标:实现以文本搜图像/视频/音频,或以图像搜文本的统一检索能力。
实现:
-
向量生成:对所有多模态片段(图像帧、视频片段、音频段落),使用CLIP模型生成统一的向量(维度512),向量空间共享。
-
向量存储:将所有向量存入Milvus,建立IVF_FLAT索引,每个向量关联片段ID和模态类型。
-
检索流程:
-
用户输入文本查询 → 使用CLIP文本编码器转换为向量。
-
在Milvus中搜索最相似的K个向量,返回片段ID。
-
根据片段ID从PostgreSQL获取片段元数据,组合成结果列表。
-
支持按模态过滤(只返回图像或视频)。
-
-
跨模态检索示例:
-
输入“主轴高速旋转” → 返回相关视频片段和图像。
-
上传一张故障图片 → 使用CLIP图像编码器转为向量,搜索相似历史故障案例。
-
第六章 数据模型
6.1 多模态文档表
表名:multimodal_documents
| 字段 | 类型 | 说明 |
|---|---|---|
| doc_id | UUID | 主键,文档唯一ID |
| project_id | UUID | 项目/客户标识 |
| file_name | string | 原始文件名 |
| file_type | string | 文件类型(image/video/audio/other) |
| mime_type | string | MIME类型 |
| size_bytes | bigint | 文件大小 |
| duration | float | 时长(秒),视频/音频专用 |
| resolution | string | 分辨率 |
| upload_time | timestamp | 上传时间 |
| storage_path | string | 存储路径(MinIO) |
| status | string | pending/processing/completed/failed |
6.2 多模态片段表
表名:multimodal_segments
| 字段 | 类型 | 说明 |
|---|---|---|
| segment_id | UUID | 主键,片段唯一ID |
| doc_id | UUID | 所属文档ID |
| segment_type | string | 片段类型:image_frame/video_clip/audio_segment |
| modality | string | 原始模态:image/video/audio |
| start_time | float | 开始时间(秒) |
| end_time | float | 结束时间(秒) |
| frame_index | int | 关键帧索引 |
| text_content | text | 语音转录文本/OCR文本/自动生成的描述 |
| entities | jsonb | 实体列表 |
| vector_id | string | 向量ID(对应Milvus) |
| confidence | float | 对齐置信度(0-1) |
| created_at | timestamp | 创建时间 |
6.3 多模态关系表
表名:multimodal_relations
| 字段 | 类型 | 说明 |
|---|---|---|
| relation_id | UUID | 主键 |
| source_id | UUID | 源片段ID |
| target_id | UUID | 目标片段ID |
| relation_type | string | 关系类型:belongs_to / same_as / describes |
| confidence | float | 置信度 |
6.4 实体融合表
表名:fused_entities
| 字段 | 类型 | 说明 |
|---|---|---|
| entity_id | UUID | 主键,融合实体ID |
| standard_name | string | 标准实体名称 |
| aliases | jsonb | 别名列表,如[“电机”,”马达”,”motor”] |
| entity_type | string | 实体类型(产品/部件/参数/…) |
| attributes | jsonb | 实体属性(如型号、规格) |
| source_segments | jsonb | 来源片段ID列表 |
| created_at | timestamp | 创建时间 |
第七章 接口设计
7.1 内部API
| 接口 | 方法 | 路径 | 说明 |
|---|---|---|---|
| 上传文件 | POST | /api/v1/multimodal/upload | 支持分片上传,返回任务ID |
| 获取上传状态 | GET | /api/v1/multimodal/status/{task_id} | 查询解析进度 |
| 启动解析 | POST | /api/v1/multimodal/parse/{doc_id} | 手动触发解析 |
| 获取解析结果 | GET | /api/v1/multimodal/result/{doc_id} | 返回文档的所有片段 |
| 跨模态检索 | POST | /api/v1/multimodal/search | 输入文本/图像,返回匹配片段 |
| 获取片段详情 | GET | /api/v1/multimodal/segment/{segment_id} | 返回片段元数据 |
7.2 与其他系统的接口
| 对接系统 | 接口用途 | 数据流向 | 协议 |
|---|---|---|---|
| 语义资产库 | 推送结构化语料 | 本系统 → 语义资产库 | gRPC |
| 语义资产库 | 获取知识图谱实体库(用于同义词匹配) | 语义资产库 → 本系统 | gRPC |
| 采集系统 | 获取外部多模态数据 | 采集系统 → 本系统 | REST |
| 意图分析系统 | 提供多模态检索结果 | 本系统 → 意图分析系统 | gRPC |
第八章 技术指标
8.1 性能指标
| 指标 | 目标值 | 测试条件 |
|---|---|---|
| 图像解析速度 | ≤2秒/张 | 1080p图像,含OCR+目标检测 |
| 视频解析速度 | ≤1×实时 | 1080p视频,含语音识别+关键帧 |
| 音频解析速度 | ≤0.5×实时 | Whisper large模型 |
| 跨模态检索P95时延 | ≤300ms | Milvus索引,100万向量 |
| 单任务最大文件大小 | 50GB | 支持分片上传 |
| 并发任务数 | ≥20 | 8核32GB节点 |
8.2 质量指标
| 指标 | 目标值 |
|---|---|
| OCR准确率(印刷体) | ≥99% |
| 图表数据还原准确率 | ≥95% |
| 语音转文字准确率(中文) | ≥98% |
| 说话人分离准确率 | ≥90% |
| 图文对齐准确率 | ≥85% (Top-1) |
8.3 容量指标
| 指标 | 目标值 |
|---|---|
| 单项目最大文件数 | 10万 |
| 单项目最大片段数 | 1000万 |
| 向量数据库容量 | 支持10亿向量 |
第九章 未来演进
9.1 V1.1 自适应增强
-
引入主动学习,根据用户反馈优化实体识别模型。
-
支持更多专业图表类型(如雷达图、散点图)。
9.2 V1.5 3D模型与点云解析
-
支持STEP/IGES等3D模型文件,提取零部件结构、装配关系。
-
支持LiDAR点云数据,用于逆向工程、质量检测。
9.3 V2.0 实时流媒体解析
-
支持直播流(RTMP/HLS)的实时解析与结构化。
-
应用于展会直播、远程运维指导等场景。
结语
罗兰艺境GEO多模态语料解析与结构化系统,是罗兰艺境“1+11”全栈技术资产中语义基建层的多模态扩展引擎。它通过图表数据还原、视频-语音对齐、多模态实体融合、跨模态检索等核心技术,将企业困在图纸、视频、录音中的隐性知识转化为可继承、可迭代、可验证的结构化语义资产,使企业技术资产库真正实现“全息化”。当AI能够同时理解文本、图像、视频、音频中的信息时,企业才真正拥有了面向AI时代的完整认知资产。
附录A:支持的文件格式列表
| 模态 | 格式 | 说明 |
|---|---|---|
| 图像 | JPG, PNG, TIFF, BMP, GIF, WEBP | 静态图像 |
| 文档图像 | PDF(含扫描页) | 需OCR处理 |
| 视频 | MP4, AVI, MOV, MKV, WEBM, FLV | 常见视频格式 |
| 音频 | MP3, WAV, M4A, AAC, FLAC, OGG | 常见音频格式 |
| 专业图纸 | DWG(需AutoCAD授权), DXF | 需借助第三方库转换 |
| 3D模型(预留) | STEP, IGES, STL, OBJ | V1.5支持 |
附录B:多模态实体类型枚举
| 类型 | 说明 | 示例 |
|---|---|---|
| 产品 | 整机、设备 | “XH-200机床” |
| 部件 | 子组件、零件 | “主轴””电机” |
| 参数 | 技术指标 | “转速””功率” |
| 仪表读数 | 仪表显示值 | “转速表 24000 rpm” |
| 动作 | 操作步骤 | “按下启动按钮” |
| 场景 | 视频中的场景 | “产品介绍””操作演示” |
| 人员 | 人物(说话人) | “工程师张三” |
| 图表 | 统计图表 | “季度销售额柱状图” |
本文基于《罗兰艺境GEO多模态语料解析与结构化系统》软著撰写,所有技术数据均来自系统实际运行验证。
文章摘自:https://www.cnblogs.com/roland-geo/p/19824476/luolan-yijing-geo-multimodal-parsing-system