MSRA获ACM TOMM 2017最佳论文:让AI接手繁杂专业的图文排版设计工作
作者:奕欣 2017-08-21 11:42:17
新闻
人工智能 今天我们为大家介绍的这篇论文,“Automatic Generation of Visual-Textual Presentation Layout”(图文排版的自动生成算法研究),刚刚被美国计算机学会会刊ACM Transactions on Multimedia Computing,
你是否曾经为如何创作和编辑一篇图文并茂、排版精美的文章而烦恼?或是为缺乏艺术灵感和设计思路而痛苦?AI技术能否在艺术设计中帮助到我们?今天我们为大家介绍的这篇论文,“Automatic Generation of Visual-Textual Presentation Layout”(图文排版的自动生成算法研究),刚刚被美国计算机学会会刊ACM Transactions on Multimedia Computing, Communications and Applications (TOMM)授予2017 Nicolas D. Georganas 最佳论文奖,希望为大家在进行富媒体内容创作和分享时提供一个独到的思路和方法。
论文的联合作者是杨绪勇(微软亚洲研究院和中国科技大学联合培养博士生,喂车车联合创始人)、梅涛(微软亚洲研究院资深研究员,美国计算机协会杰出科学家,国际模式识别学会会士)、徐迎庆(前微软亚洲研究院主管研究员,清华大学美术学院信息艺术设计系主任)、芮勇(前微软亚洲研究院副院长,联想CTO)、李世鹏(前微软亚洲研究院副院长,硬蛋CTO)。祝贺研究院的各位研究员和院友们!
当今富媒体的内容之多是前所未有的,人们每时每刻都在创造和分享着海量信息,特别是内容繁杂的图像和文字信息,其中图文混排的内容模式已经成为主流。而在内容创作过程中,人们面临的一个巨大的挑战就是如何针对内容多样的图像和文字信息来设计吸引眼球的版面(例如,杂志封面、海报、或者PPT演讲稿等)。这个问题无论是对于商业印刷、在线期刊与杂志,还是用户生成的内容表达,都极为重要。图文内容的排版涉及到大量的专业知识,包括视觉传达、信息艺术设计、色彩与美学、平面规划、几何构图等等。以往的图文排版设计工作,不仅需要具有丰富专业知识的设计师,而且还耗费大量的人工。如何让计算机根据图文内容来自动进行排版是一个非常困难的问题。
从2013年底开始,来自微软亚洲研究院的研究员与来自清华大学美术学院的艺术设计专家,在这个科学与艺术相融合的领域开展了深入地合作。他们把设计学中的审美原则与可计算的图像特征相结合,创造性地提出了一个可计算的自动排版框架原型。该原型通过对一系列关键问题的优化(例如,嵌入在照片中的文字的视觉权重、视觉空间的配重、心理学中的色彩和谐因子、信息在视觉认知和语义理解上的重要性等),把视觉呈现、文字语义、设计原则、认知理解等领域专家的先验知识自然地集成到同一个多媒体计算框架之内,并且开创了“视觉文本版面自动设计”这一新的研究方向。

图1 利用算法自动产生的图文排版效果。注:原始输入是一张纯图片(即没有任何文字)和一段纯文本(如主标题和副标题等),输出是图文混排的结果(文字嵌入图片之中)。
这项研究将通用的美学感知进行了体系的数学表达,构建了一套和主题相关的图文排版设计模版库,并提出一套可计算的图文合成框架原型,既融合了宏观层面自上而下的美学感知,又包含了微观层面自下而上的图文特征。通过融合人脸、文字检测以及视觉显著性检测算法,率先提出了视觉注意力检测算法,构成了整幅图像的重要性图和注意力图;在针对文字布局的算法中,这篇论文将文字块的形状和图像中的重要性图交互过程量化为一个能量最优化问题:
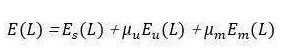
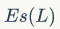 是图1中文本侵入显著视觉对象的成本,即尽量减少文本和重要视觉对象的交叉;
是图1中文本侵入显著视觉对象的成本,即尽量减少文本和重要视觉对象的交叉;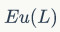 表示空闲视觉空间的浪费,即充分利用图像中的可用视觉空间,以最大化文字的突出效应;
表示空闲视觉空间的浪费,即充分利用图像中的可用视觉空间,以最大化文字的突出效应;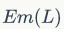 而则代表文本块的语义重要性
而则代表文本块的语义重要性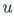 i 和视觉感知重要性
i 和视觉感知重要性 i 之间的不匹配,即将最重要的文字内容匹配到图像中最重要的视觉区域,以便于阅读时快速获得关键信息。能量最优化的求解过程,在设计模版的美学感知原则的监督下,使得最后的求解结果能符合视觉审美需求,而不仅仅是计算机的最优求解结果。
i 之间的不匹配,即将最重要的文字内容匹配到图像中最重要的视觉区域,以便于阅读时快速获得关键信息。能量最优化的求解过程,在设计模版的美学感知原则的监督下,使得最后的求解结果能符合视觉审美需求,而不仅仅是计算机的最优求解结果。
在文本空间布局后,通过对图像前后景显著颜色的分析,在色彩和谐最优化框架中,保持色彩整体和谐,并最大化文字和背景色彩的差异以使得最后的图文混排能在全局尊重原图的色彩和谐性,又能在局部保证文字的可阅读性。全局色彩的和谐计算采用了著名的“Color Harmonization”中提出的心理学色彩模型,并结合了这篇论文中提出的图像前后景主题色在不同主题下的模型偏好,从而找到最适合的全局主题色。针对局部的视觉对比度最大化,论文提出了最远色调角黄金取样法,即找到文本覆盖背景下图像的显著颜色映射到tone和hue空间,在二维色调空间(tone, hue)求最远点,并取显著颜色点到最远点的黄金分割点。通过整个框架,能完成整个图文设计在美学感知监督下的自动化。
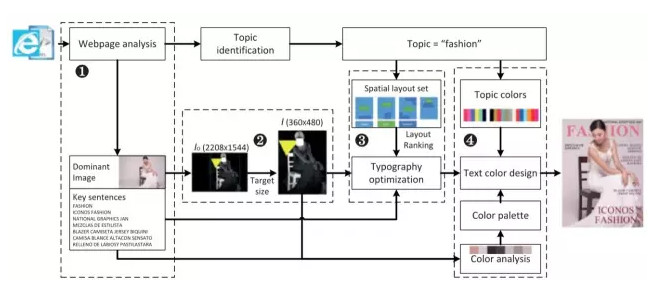
图2 系统框图
这篇论文提出的系统允许用户上传具体主题的视觉背景图像以及一些文本语句。并在第二阶段对原始图像进行了处理,通过结合显著值、脸部、文本以及目光注意力图以获取视觉感知图,进而重新调整图像的大小,使之符合目标布局尺寸,并根据视觉感知图保留重要的区域。重新调整过的图像就能用来排列空间分布的布局模板。当图像调整后,已有的语句、空间布局以及文本就通过第三阶段中的能源优化工艺重叠在背景图像上了。在第四阶段的文本着色上,首先分析经过剪裁的图像的调色板,同时根据主题属性挑选主题色彩。应用特定色相/色调模型、调色板、语义色彩以及内容特点,就可以通过保持局部色彩和谐以及局部可读性对文本进行重新着色。
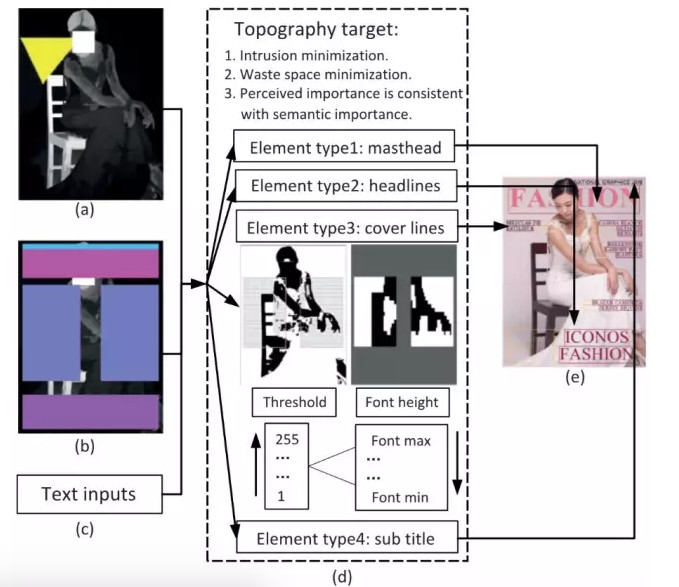
图3 布局算法(a)带有目光注意力(黄色)的视觉重要性图(灰色);(b)从前5个模板中挑选出的模板;(c)输入文本;(d)排印程序的细节,这里能源定义为E(L),通过迭代控制字体高度,在局部优化解决方案中会被最小化,;(e)受到下向上的图像特点和自上向下的空间布局限制的排印结果。
图4 色彩分析与优化的示意图
这篇论文发表之后,得到学术界的广泛关注,从2016年至今在ACM数据库中已有超过260次下载。此外,该项研究不仅具有重要的理论意义,而且具有广泛的应用价值。例如,论文提出的基于图像内容的颜色检测算法已经在实际产品Office Sway中得到应用。目前每个月有来自全球60多个国家的超过40多万用户在使用Office Sway这一新产品开展设计。
这篇论文展现了多媒体与艺术设计以及颜色心理学几个不同学科的深度融合,将人工智能的方法用于艺术设计中。可以说,颜色心理学的模型为多媒体设计打开了”心灵“的窗口,而美学设计思维则为多媒体分析展开了想象的翅膀!
论文下载地址:https://www.microsoft.com/en-us/research/publication/automatic-generation-of-visual-textual-presentation-layout/
论文作者
[[200633]]
-
杨绪勇,微软亚洲研究院和中国科技大学联合培养博士生,喂车车联合创始人
-
梅涛,微软亚洲研究院资深研究员,美国计算机协会杰出科学家,国际模式识别学会会士
-
徐迎庆,前微软亚洲研究院主管研究员,清华大学美术学院信息艺术设计系主任
-
芮勇,前微软亚洲研究院副院长,联想CTO
-
李世鹏,前微软亚洲研究院副院长,硬蛋CTO
另外,还特别感谢这篇论文的合作者——来自中国科技大学的博士生吴岳和来自清华美术学院的研究生于俊杰。