ImageNet Classification with Deep Convolutional Neural Networks
1.研究背景:
在计算机视觉领域,识别大规模图像集合是一个重要的任务。然而,由于数据量大,多样性复杂,传统的机器学习方法在此任务上面临着许多挑战。深度学习方法的出现解决了这一问题,其中卷积神经网络(CNNs)被证明在大规模视觉识别任务中非常有效。
2.研究内容:
本文介绍了一个基于卷积神经网络的深度学习模型,名为AlexNet。该模型通过在大规模视觉识别挑战(ILSVRC)上获得了最好的成绩,使得深度学习在视觉识别领域受到了广泛的关注。
3.研究方法:
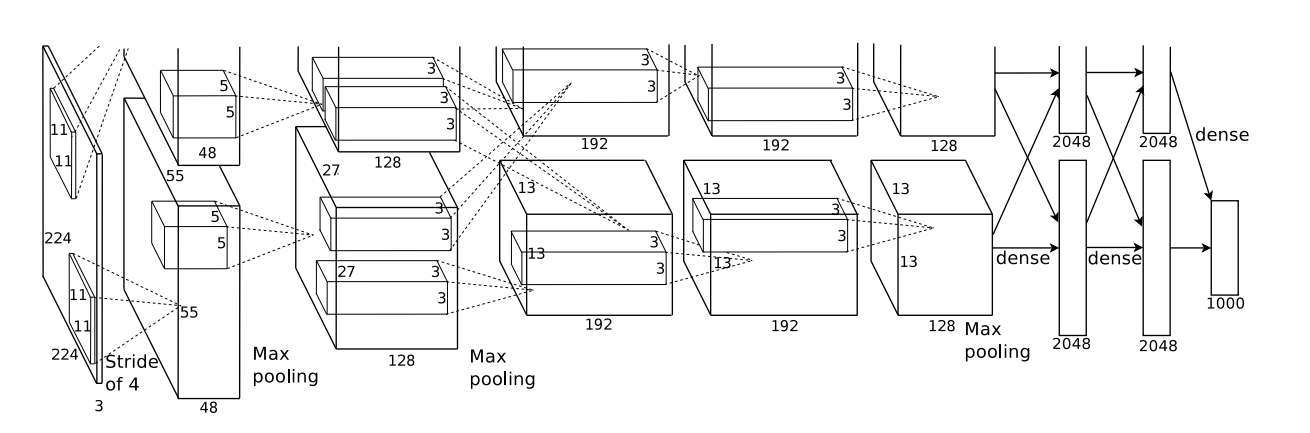
AlexNet是一个由8个神经网络层组成的深度卷积神经网络模型,用于大规模视觉识别任务。
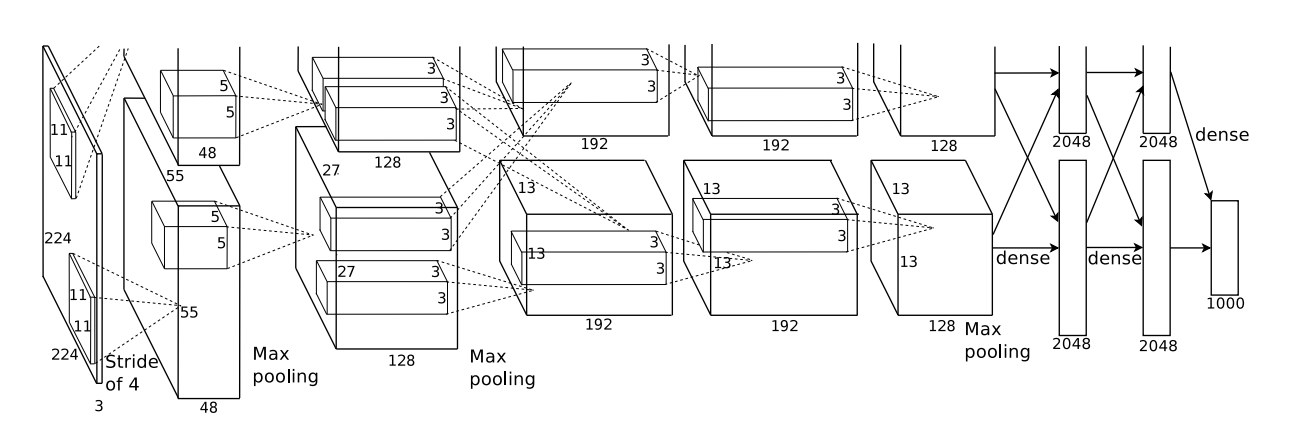
3.1 卷积层和池化层
AlexNet使用了5个卷积层和3个池化层,每个卷积层后面紧跟一个ReLU激活函数和一个局部响应归一化(LRN)层。这些卷积层和池化层的作用是通过提取图像的特征,逐渐降低图像的分辨率和复杂性,从而使得后续的全连接层可以更好地处理图像的特征。
3.2 全连接层
AlexNet使用了3个全连接层,其中第三个全连接层的输出是1000个类别的概率分布,对应着ImageNet数据集中的1000个类别。全连接层的作用是将卷积层和池化层提取的特征转化为分类器可以处理的形式。
3.3 激活函数和正则化
AlexNet使用了ReLU激活函数,相比于传统的sigmoid函数,ReLU可以在训练过程中加速收敛,并且减少梯度消失问题。此外,为了防止过拟合,AlexNet还采用了Dropout技术和LRN层。Dropout可以随机地丢弃一些神经元,从而减少模型的复杂度,避免过拟合。LRN层可以对神经元的输出进行标准化,使得神经元对输入数据的变化更加鲁棒。
3.4 数据增强
AlexNet还使用了数据增强技术来扩充训练数据集。数据增强的方法包括:随机裁剪、水平翻转、色彩变换等。这些方法可以使得模型更好地适应各种图像变换,提高模型的泛化能力。
4.研究结果:
在ImageNet LSVRC-2010数据集上,AlexNet模型取得了16.4%的top-5错误率,比排名第二的模型低10.8%。该模型的表现证明了深度卷积神经网络在大规模视觉识别任务中的效果,并且使得深度学习在视觉识别领域受到广泛关注。
5. AlexNet代码实现(Pytorch)
import torch
import torch.nn as nn
class AlexNet(nn.Module):
def __init__(self, num_classes=1000):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.LocalResponseNorm(size=5),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(64, 192, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.LocalResponseNorm(size=5),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(192, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.avgpool = nn.AdaptiveAvgPool2d((6, 6))
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),
)
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
在该代码中定义了一个名为AlexNet的类,该类继承自nn.Module。在该类的构造函数中,定义了该模型的各个层和参数,其中features是卷积和池化和LRN层,avgpool是自适应平均池化层,classifier是全连接层。在forward函数中,将输入x传入features和avgpool层,并将输出结果压缩成一个向量,最后通过全连接层得到预测结果。
6.总结与思考
6.1 文章中用了哪些手段来提高模型性能?这些手段今天是否还试用?
答:AlexNet使用了以下技术手段来提高模型性能:
- 数据增强:随机裁剪、随机水平翻转等方法,可以增加训练样本,提高模型的泛化能力。
- Dropout:随机将一部分神经元的输出设为0,可以减少模型的过拟合,提高模型的泛化能力。
- ReLU激活函数:相比于传统的Sigmoid和tanh激活函数,ReLU激活函数具有更快的收敛速度和更好的表达能力。
- LRN层:用于抑制神经元响应的饱和现象,并且可以提高模型的泛化能力,有效避免过拟合。
这些技术手段在现代深度学习中仍然被广泛使用。
6.2 至今为止,除了文章中提到的还有哪些常用的提高模型性能或者防止过拟合的手段?
答:有
- 权重衰减(weight decay):在损失函数中加入权重的平方范数(L2正则化)或绝对值范数(L1正则化)作为正则化项,以惩罚较大的权重,防止模型过拟合。
- 早停(提早停止)
- Batch Normalization:在每个小批量的数据上对输入进行标准化,使得每层的输入具有相似的统计分布,从而加速模型的训练,同时也可以减少模型的过拟合。
- 集成学习(ensemble learning):通过将多个模型的预测结果结合起来,得到更准确的预测结果,从而减少模型的过拟合风险。
等。
6.3 为什么ReLU表现的会比传统的Sigmoid和tanh激活函数更好呢?
答:
- 快速收敛:Sigmoid和tanh函数的梯度在两端接近0,容易出现梯度消失问题,导致训练速度变慢。而ReLU函数的梯度在正区间一直为1,可以保证梯度传播时不会出现梯度消失问题,从而加速模型的收敛速度。
- 更好的表达能力:Sigmoid和tanh函数在输入较大或较小时,输出接近饱和,无法提供更多信息。而ReLU函数在正区间内输出恒为正数,可以提供更多的信息,更好地表达数据的特征。
6.4 由于模型过大和当时的算力限制,作者使用了两个GPU来进行训练,现在多GPU训练还有必要吗?
答:由于GPU算力飞快发展,在大部分任务中好像已经不需要在进行这样的操作了,但是在自然语言处理领域也可能会出现参数过多模型过大导致单个GPU无法训练的情况,这时候还是要采取多GPU联合训练的方法的。