前言
随着大型语言模型 (LLM) 的飞速发展,将其集成到各类应用中以提升智能化水平已成为一种趋势。Saga Reader 作为一款现代化的 RSS 阅读器,在 LLM 集成方面做出了前瞻性的设计,不仅支持通过 Ollama 实现本地化 LLM 功能,还具备了接入多种在线 LLM 服务(如智谱 GLM、Mistral AI 等)的能力。本文将深入剖析 Saga Reader 是如何实现这种灵活的多 LLM Provider 架构,并探讨其技术难点与亮点。
关于Saga Reader
基于Tauri开发的开源AI驱动的智库式阅读器(前端部分使用Web框架),能根据用户指定的主题和偏好关键词自动从互联网上检索信息。它使用云端或本地大型模型进行总结和提供指导,并包括一个AI驱动的互动阅读伴读功能,你可以与AI讨论和交换阅读内容的想法。
这个项目我5月刚放到Github上(Github – Saga Reader),欢迎大家关注分享。🧑码农🧑开源不易,各位好人路过请给个小星星Star。
核心技术栈:Rust + Tauri(跨平台)+ Svelte(前端)+ LLM(大语言模型集成),支持本地 / 云端双模式
关键词:端智能,边缘大模型;Tauri 2.0;桌面端安装包 < 5MB,内存占用 < 20MB。
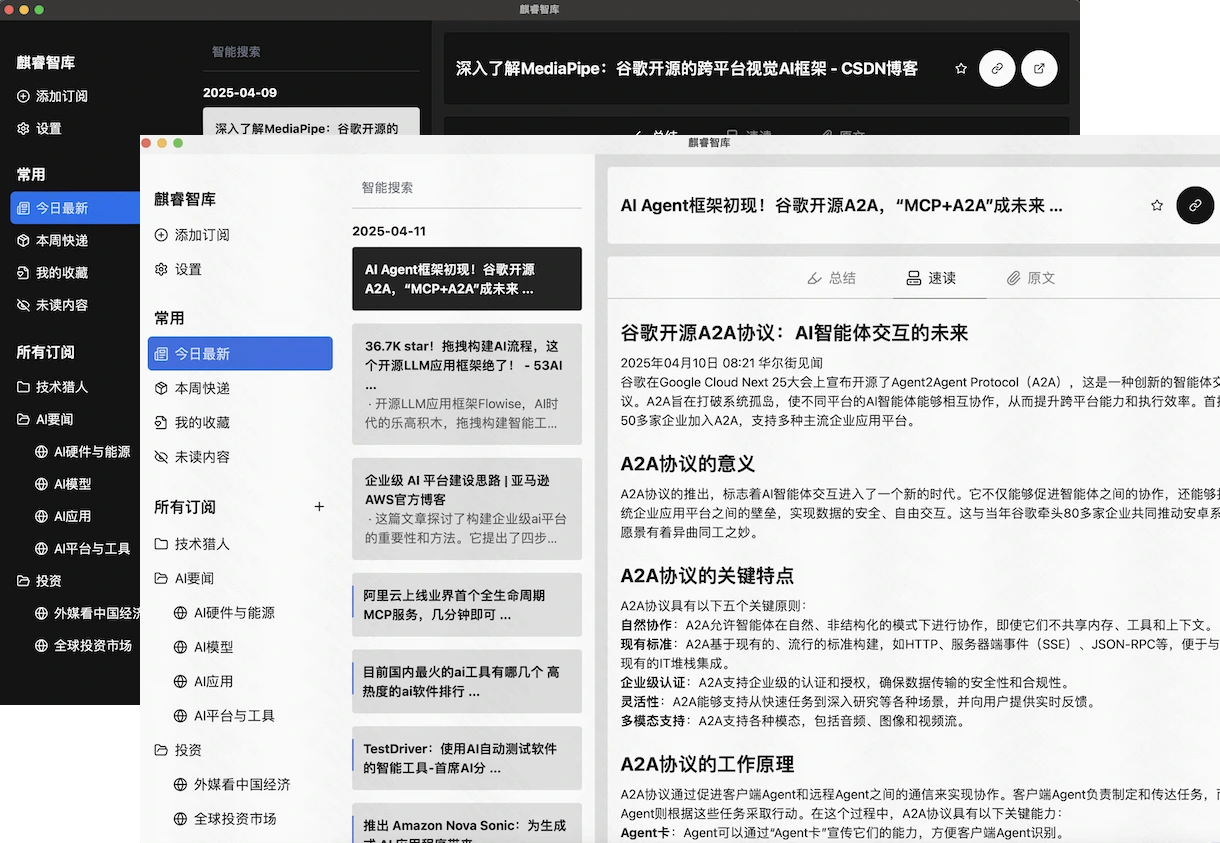
运行截图
为何需要支持多种 LLM Provider?
在 LLM 的选型上,不同的 Provider 各有千秋:
- 本地 LLM (Ollama):
- 优势:数据隐私与安全、离线可用性、低成本、模型选择灵活。
- 场景:对隐私高度敏感的用户、无网络环境、个人实验与定制。
- 在线 LLM (如 GLM, Mistral AI, OpenAI Platform 等):
- 优势:通常拥有更强大的模型能力、更快的推理速度(依赖云端算力)、无需本地配置和资源消耗。
- 场景:追求最佳效果、需要特定高级功能(如超长上下文、特定领域微调模型)、不希望占用本地资源。
Saga Reader 通过支持多种 Provider,赋予了用户根据自身需求和偏好选择最合适 LLM 服务的自由,同时也为应用未来的功能扩展打下了坚实的基础。
Saga Reader 的 LLM 集成架构:深入代码细节
Saga Reader 的 LLM 功能构建在 crates/llm 和 crates/ollama 这两个核心 crate 之上。其设计的核心思想是抽象与解耦,使得上层业务逻辑可以透明地与不同的 LLM Provider 进行交互。
模块依赖关系图 (Mermaid)
graph TD AppLogic[Saga Reader 应用逻辑] –>|调用 LLM 功能| LLMAgent[llm::llm_agent::CompletionAgent] LLMAgent –>|根据配置选择| OllamaService[llm::providers::llm_ollama::OllamaCompletionService] LLMAgent –>|根据配置选择| GLMService[llm::providers::llm_glm::GLMCompletionService] LLMAgent –>|根据配置选择| MistralService[llm::providers::llm_mistral::MistralQinoAgentService] LLMAgent –>|根据配置选择| PlatformService[llm::providers::llm_platform::PlatformAgentService] OllamaService –>|HTTP 请求| OllamaAPI[Ollama REST API] GLMService –>|HTTP 请求| GLMAPI[智谱 GLM API] MistralService –>|HTTP 请求| MistralAPI[Mistral AI API] PlatformService –>|HTTP 请求| CustomPlatformAPI[自定义平台 API] OllamaService –>|依赖| OllamaCrate[ollama crate] OllamaCrate –>|执行 Shell 命令| LocalOllama[本地 Ollama 实例] LLMAgent –>|使用| LLMConnector[llm::connector] OllamaService –>|使用| LLMConnector GLMService –>|使用| LLMConnector MistralService –>|使用| LLMConnector PlatformService –>|使用| LLMConnector AppLogic –>|读取配置| LLMConfig[types::LLMSection] LLMAgent –>|读取配置| LLMConfig
1. 配置层 (types crate)
所有与 LLM 相关的配置都定义在 types crate 中,例如 (假设存在此结构,具体需查看 types crate) 及其包含的各个 Provider 的具体配置结构(如 OllamaLLMProvider, GLMLLMProvider)。这使得配置信息与业务逻辑分离,方便管理。
2. ollama Crate: 本地 Ollama 服务管理
这个 Crate ( ) 专注于与本地 Ollama 实例的交互和管理,其核心功能在 中实现:
ProgramStatus枚举:定义了 Ollama 的几种状态:Uninstall,InstallButNotRunning,Running。Information结构体:封装了 Ollama 的版本、状态和额外信息。- 平台路径常量:
// ... existing code ... #[cfg(target_os = "windows")] static PATH_TO_OLLAMA: &str = "ollama"; #[cfg(target_os = "macos")] static PATH_TO_OLLAMA: &str = "/usr/local/bin/ollama"; #[cfg(target_os = "linux")] static PATH_TO_OLLAMA: &str = "/usr/local/bin/ollama"; // ... existing code ...这里使用条件编译来确定不同操作系统下
ollama命令的路径。 create_shell_command()函数:// ... existing code ... #[cfg(target_family = "unix")] fn create_shell_command() -> Command { let mut cmd = Command::new("sh"); cmd.arg("-c"); cmd } #[cfg(target_family = "windows")] fn create_shell_command() -> Command { let mut cmd = Command::new("cmd"); cmd.arg("/C").creation_flags(0x08000000); // CREATE_NO_WINDOW cmd } // ... existing code ...根据操作系统类型创建相应的
tokio::process::Command,用于执行 shell 命令。在 Windows 上,creation_flags(0x08000000)用于隐藏命令窗口。request_running()和request_version():通过 HTTP GET 请求访问 Ollama 的 API (如/和/api/version) 来检查服务是否运行并获取版本。query_platform_by_process():// ... existing code ... async fn query_platform_by_process() -> anyhow::Result<Information> { match create_shell_command() .arg(format!("{PATH_TO_OLLAMA} -v")) // 执行 ollama -v .output() .await { Ok(output) => { if output.status.success() { // 命令成功执行 let stdout_str = std::str::from_utf8(&output.stdout)?; // 解析版本号和运行状态 let status = match parse_is_running_from_version(stdout_str) { true => ProgramStatus::Running, false => ProgramStatus::InstallButNotRunning, }; return Ok(Information { version: parse_version(stdout_str).into(), status, extra: None, }); } // 命令执行失败,可能未安装 let stderr_str = std::str::from_utf8(&output.stderr)?; Ok(Information { version: "-".into(), status: ProgramStatus::Uninstall, extra: Some(stderr_str.to_owned()), }) } Err(err) => { // 执行命令本身出错,也视为未安装 Ok(Information { version: "-".into(), status: ProgramStatus::Uninstall, extra: Some(err.to_string()), }) } } } // ... existing code ...此函数尝试通过执行
ollama -v命令来获取 Ollama 的状态。它会检查命令的退出状态,并解析标准输出/错误输出。parse_version()和parse_is_running_from_version():辅助函数,用于从ollama -v的输出中提取版本信息和判断 Ollama 是否正在运行(通过查找特定错误信息)。
3. llm Crate: LLM 服务抽象与 Provider 实现
这个 Crate ( ) 是 LLM 功能的核心,实现了对多种 Provider 的支持。
-
connector.rs: ( )// ... existing code ... pub(crate) fn new() -> anyhow::Result<Client> { Ok( Client::builder() .timeout(Duration::from_secs(60)) // 设置请求超时 .gzip(true) // 启用 gzip 压缩 .deflate(true) // 启用 deflate 压缩 .build()? // 构建 Client ) } // ... existing code ...提供了一个共享的
reqwest::Client实例,统一了网络请求的配置,如超时时间和内容压缩。 -
providers/types.rs: ( )AITargetOption结构体:定义了调用 LLM 时可配置的参数,如temperature,seed,top_k,top_p,num_ctx,并提供了默认值。CompletionServiceTrait:// ... existing code ... pub trait CompletionService { fn completion(&self, message: String) -> impl std::future::Future<Output=anyhow::Result<String>>; } // ... existing code ...这是所有 LLM Provider 必须实现的接口,其核心是
completion异步方法,接收用户消息,返回 LLM 的响应。使用了impl Trait作为返回类型,简化了异步代码的编写。
-
llm_agent.rs: ( )CompletionServiceEnums枚举:内部使用,用于持有不同 Provider 实例的Box(或者直接持有实例,如当前代码所示)。CompletionAgent结构体:对外暴露的统一 LLM 调用入口。CompletionAgent::new()( ): 工厂方法,根据传入的LLMSection配置(其中包含了active_provider_type和各 Provider 的具体配置),实例化对应的CompletionService实现,并将其存储在CompletionServiceEnums中。CompletionAgent::completion()( ): 将调用分发到内部持有的具体 Provider 实例的completion方法。
-
Provider 实现 (例如
providers/llm_ollama.rs,providers/llm_glm.rs):- 每个 Provider 文件都定义了一个结构体 (如
OllamaCompletionService,GLMCompletionService),并为其实现了CompletionServiceTrait。 - 构造函数 (
new): 接收特定 Provider 的配置(如OllamaLLMProvider)、系统提示词和AITargetOption,初始化自身状态,包括创建reqwest::Client实例。 completion方法: 核心逻辑所在地。- 构造特定于该 Provider API 的请求参数(通常包括模型名称、系统提示、用户提示、以及
AITargetOption中的参数)。例如,在 中:// ... existing code ... let parameter = RequestParameter { model: self.endpoint.model.to_string(), system: self.system_prompt.to_string(), prompt: content, options: self.options.clone(), images: None, // Ollama 支持多模态,这里预留了 images 字段 format: None, // 可以指定输出格式,如 json keep_alive: "5m".to_string(), // 保持模型活跃一段时间 stream: false, // 当前实现为非流式 }; // ... existing code ...在 中,请求体是
messages数组:// ... existing code ... let sys_prompt = Message { role: "system".to_string(), content: self.system_prompt.to_string(), }; let message = Message { role: "user".to_string(), content, }; let parameter = RequestParameters { model: self.config.model_name.clone(), messages: vec![sys_prompt, message], }; // ... existing code ... - 使用
self.client(即llm::connector::new()创建的reqwest::Client) 发送异步 HTTP POST 请求到 Provider 的 API endpoint。 - 处理认证:对于需要 API Key 的 Provider (如 GLM, Mistral),在请求头中添加
Authorization字段。// ... existing code ... .header("Authorization", format!("Bearer {}", self.config.api_key.clone())) // ... existing code ... - 异步等待响应,并将响应体解析为特定于该 Provider API 的响应结构体 (如
CompletionReplyfor Ollama,Responsefor GLM)。 - 从解析后的响应中提取 LLM 生成的文本内容并返回。
- 构造特定于该 Provider API 的请求参数(通常包括模型名称、系统提示、用户提示、以及
- 每个 Provider 文件都定义了一个结构体 (如
LLM 调用流程图 (Mermaid)
sequenceDiagram participant App as Saga Reader AppLogic participant Agent as llm::CompletionAgent participant Provider as Concrete LLM Provider (e.g., OllamaCompletionService) participant API as LLM API Endpoint App->>Agent: completion(user_message) Agent->>Provider: completion(user_message) Provider->>API: POST /api/generate (or similar) Note right of Provider: Request includes model, prompt, options API–>>Provider: HTTP Response (JSON) Provider–>>Agent: Result<String, Error> Agent–>>App: Result<String, Error>
技术难点与亮点回顾
- 高度可扩展的 Provider 架构:
- 亮点:通过
CompletionServiceTrait 和CompletionAgent的设计,Saga Reader 可以非常方便地添加对新的 LLM Provider 的支持,只需实现 Trait 并更新CompletionAgent的match分支即可。这是整个 LLM 模块最核心的优势。
- 亮点:通过
- 异步与错误处理:
- 亮点:所有 LLM 调用都是异步的 (
async/await),避免阻塞主线程。统一使用anyhow::Result进行错误处理,简化了错误传递和管理。
- 亮点:所有 LLM 调用都是异步的 (
- 配置驱动:
- 亮点:LLM Provider 的选择、API 地址、密钥、模型名称等都通过配置(
LLMSection及其子结构)传入,使得切换和管理 Provider 非常灵活。
- 亮点:LLM Provider 的选择、API 地址、密钥、模型名称等都通过配置(
- Ollama 的本地化支持:
- (这部分与上一版博客分析一致,包括跨平台兼容性、服务状态检测等)
- 对多种在线 API 的精细化适配:
- 难点:不同的在线 LLM API 有着不同的请求/响应格式、认证方式。Saga Reader 通过为每种 API 创建专门的
RequestParameters和Response结构体,以及在各自的completion方法中处理独特的认证逻辑,解决了这个问题。
- 难点:不同的在线 LLM API 有着不同的请求/响应格式、认证方式。Saga Reader 通过为每种 API 创建专门的
应用场景示例 (畅想)
- 文章摘要生成 :自动为长篇文章生成简洁的摘要。
- 智能问答 :针对当前阅读的文章内容,向 LLM 提问并获得解答。
- 内容翻译 :将外语文章翻译成用户设定的语言。
- 关键词提取与主题分类 :帮助用户更好地组织和发现感兴趣的内容。
- 个性化推荐 :根据用户的阅读历史和偏好,利用 LLM 理解内容并进行智能推荐。
总结与展望
Saga Reader 通过其精心设计的 LLM 模块,不仅实现了对本地 Ollama 的深度集成,更展现了其拥抱多样化 LLM Provider 的开放姿态。这种灵活、可扩展的架构,使得 Saga Reader 能够根据用户的具体需求和技术发展趋势,自由切换或组合使用不同的 LLM 服务,从而持续提升应用的智能化水平和用户体验。
未来,随着更多 LLM 服务的涌现,Saga Reader 的这种架构优势将更加凸显。我们期待看到 Saga Reader 在 RSS 阅读领域带来更多基于 LLM 的创新功能。