本文将详细讲解Windows平台下,如何安装与NVIDIA RTX显卡匹配的CUDA工具包,并正确配置、使用llama.cpp加载大模型,实现模型高效运行(将模型几乎全放入显卡,提升推理速度),全程结合实操截图与具体命令,新手可直接跟着操作。
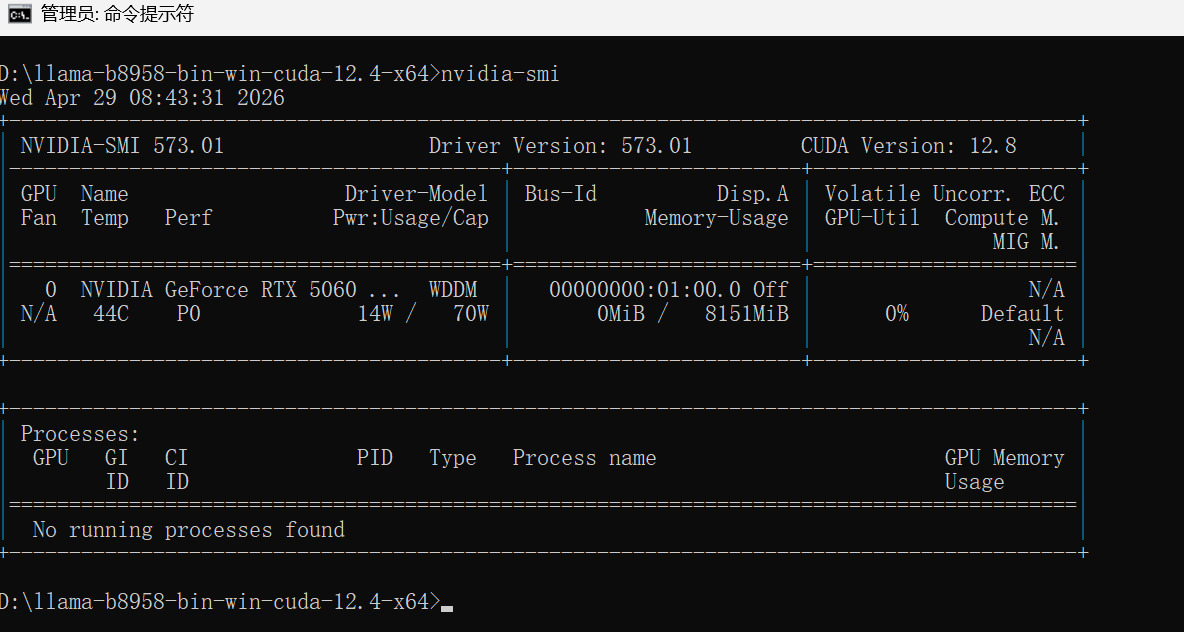
1.首先需要下载与RTX对应的CUDA驱动,此处必须保证完全一致,执行nvidia-smi命令获取版本信息,这里最高支持CUDA Version: 12.8版。


2.接着下载Cuda 12.4并选择自定义安装。

3.大模型加载器需要是12版,所以就只能下载llama.cpp12系列的,其他版本会报错。

4.执行命令直接启动llama.cpp,模型几乎全放进显卡。
使用30层。
llama-server.exe -m qwen.gguf --host 127.0.0.1 --port 11433 -c 1024 --n-gpu-layers 30

运行之前把防火墙关闭,不然可能会无法连接。

5.准备好测试脚本,如下所示,让其输出500个字的概述。
import json
from urllib import request, error
url = "http://127.0.0.1:11433/completion"
headers = {"Content-Type": "application/json"}
data = {
"model": "qwen.gguf",
"prompt": "你好,请用500字介绍一下通义千问",
"temperature": 0.7,
"max_tokens": 512,
"ctx_size": 4096,
"stop": ["<|im_end|>"]
}
try:
data_json = json.dumps(data).encode("utf-8")
req = request.Request(url, data=data_json, headers=headers, method="POST")
with request.urlopen(req, timeout=60) as response:
result = json.loads(response.read().decode("utf-8"))
print("生成结果:")
print(result["content"])
except error.HTTPError as e:
print(f"调用失败(HTTP错误):{e.code} - {e.reason}")
except error.URLError as e:
print(f"调用失败(连接/网络错误):{e.reason}")
except Exception as e:
print(f"调用失败(其他异常):{e}")
运行结果如下:

文章摘自:https://www.cnblogs.com/LyShark/p/19947914