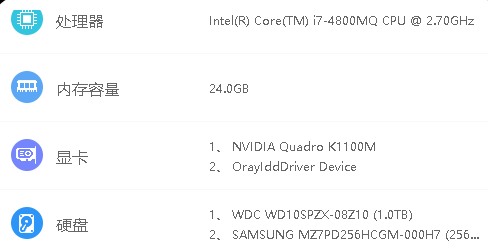
Qwen3.5 0.8b 老电脑小试牛刀
阿里云在 2026 年初发布的 Qwen3.5 0.8B 是一款极具突破性的“微型”基础模型。虽然只有 8 亿参数,但它拥有 Gated Delta Networks 混合架构、原生多模态支持以及超长上下文窗口。由于体积极小,它正在重塑端侧(Edge)AI 的应用生态。
Qwen3.5 0.8B 核心应用场景
-
极低功耗的边缘设备部署 (智能穿戴与物联网): 模型量化后仅需约 800MB 的内存,能在 Apple Watch 等智能手表或老旧智能手机上流畅运行(推理速度可达 10+ tokens/s)。这非常适合用作离线的智能家居中枢或可穿戴设备的自然语言交互接口,在无需依赖云端的情况下做到绝对的隐私保护。
-
纯前端/浏览器端 AI 赋能: 配合 Transformers.js 等框架,Qwen3.5 0.8B 能够利用 WebGPU 直接在用户的浏览器中本地运行。开发者可以构建零延迟、零 API 成本的纯前端网页应用,例如轻量级的离线网页文本摘要、沉浸式翻译或智能表单补全。
-
轻量级视觉到动作 (Vision-to-Action) 决策: 得益于其底层的原生多模态能力,它在处理图像时不需要外挂繁重的视觉适配器。社区开发者测试发现,即便是 0.8B 的小模型,也能通过截屏识别游戏(如《毁灭战士》)中的复杂画面,并输出“移动”或“开火”等精准操作指令。它非常适合作为轻量级 RPA(机器人流程自动化)或极简智能体的视觉导航节点。
-
超长文本的本地离线过滤: 令人意外的是,这个 0.8B 的微型模型原生支持高达 262,144 token 的上下文窗口。它可以被用来在算力受限的终端设备上,快速“生吞”长篇的系统日志或文档集,进行初级的关键信息检索、报错排查和分类。
环境

推理场景
测试提示词
桌子上有 3 个不透明的盒子。盒子 A 上写着:“金币在盒子 B 里。” 盒子 B 上写着:“金币不在盒子 A 里。” 盒子 C 上写着:“金币不在这个盒子里。” 已知这三句话中,只有一句话是真话,并且金币只在一个盒子里。请问金币到底在哪个盒子里?请逐步推导并给出确切结论。

信息抽取与 JSON 格式控制(长文本/杂乱信息处理)
小模型在处理包含多重干扰信息的文本时,往往容易“跑偏”或者无法严格遵循 JSON 输出格式。这个测试旨在评估其在实际业务场景中的数据提取与初步计算能力。评测成功
以下是一段门店店长的口语化日常汇报: “今天15号,早班的时候海鼎的收银系统又卡了一下,大概有五六个顾客没结账就走了,这块得抓紧优化。今天我们店进了 300 斤阿克苏苹果,这批货不行,坏果率我目测得有 5% 左右。今天的总营业额是 4500 元,不过里面有 1200 元是老顾客的会员卡充值,剩下的才是实际卖货的钱。另外店里的物料袋快没了,记得让大仓明天补点。”
请提取并计算以下信息构建 JSON:
-
date: 汇报日期(数字) -
system_issue: 提及的系统故障及影响(字符串) -
product_loss: 主要进货品类及损耗率(字符串) -
actual_sales: 实际商品销售额(需自行利用总营业额和充值金额计算得出,数字格式) -
inventory_request: 需要补充的物资(字符串)

测试观察点:
1. 模型能否准确进行 4500 - 1200 = 3300 的基本数学推理?
2. 是否严格只输出了 JSON,没有输出诸如“好的,这是您需要的 JSON:”之类的废话(小模型常犯此错)?
专业领域的深度逻辑链(网络空间安全/代码审计)
请审阅以下 Nginx 配置片段并指出潜在的安全风险: server { listen 80; server_name example.com; location / { proxy_pass http://backend_server; } location /admin { allow 192.168.1.0/24; deny all; } } 假设 backend_server 服务本身没有做额外的身份验证。如果攻击者目前并未处于 192.168.1.0/24 网段,但他发现 backend_server 上存在一个可以解析用户输入 URL 并发起 HTTP 请求的图片抓取功能(存在 SSRF 漏洞)。请推理:攻击者能否、以及如何利用这个漏洞绕过 Nginx 的 IP 限制,直接访问到 /admin 的接口?

测试观察点: 在 <think> 过程中,它能否清晰地拆解出 Nginx 的访问控制逻辑是在反向代理层生效的,而 SSRF 是由后端服务器(属于内网)主动发起的请求,从而得出可以通过 SSRF 绕过外部网关 IP 封锁的结论。
系统架构解构与 Markdown 排版(工程化思维)
测试模型能否理解复杂的业务痛点,并用结构化的工程语言进行方案拆解。
你是一名资深的 IT 系统架构师。请以清晰、专业的 Markdown 格式输出你的架构设计方案,多用列表和精简的段落。 我们正在为一家拥有 300 多家加盟店的零售企业重构 IT 方案。由于部分下沉市场的门店网络极不稳定,且加盟商不愿意承担高昂的硬件成本,目前每个门店仅配备了一台普通的 x86 架构收银机(无独立显卡,仅 8GB 内存)。 我们计划在这些收银机上本地部署 0.8B 级别的端侧大模型,用于“断网状态下的商品智能检索与单据录入容灾”。请为这个场景设计一个极简的端侧部署与数据同步架构方案。需要包含: 本地硬件资源分配建议(如何在 8G 内存下让模型与常规收银软件共存)。 断网情况下的 AI 容灾工作流。 网络恢复后,本地生成的数据如何与总部的 WMS(仓储管理系统)或中台进行数据对齐与同步。

量化版Q8_0量化版本


测试观察点:
1. 小模型非常容易在长篇大论中丢失上下文。它能否始终围绕“8GB内存”、“断网容灾”、“WMS同步”这三个核心限制条件进行解答?
2. Markdown 的层级结构(H2, H3, 粗体等)是否美观且合乎逻辑?
英语习语解读场景

测试观察点:
1.能否识别出是英语习语,给出例句。
Qwen3.5 Plus 云端

总结
本地次测试暴露了真实的业务风险,我们需要在架构设计上做出妥协:
-
必须采用极限极化 (Quantization): 在这种老旧 CPU 上,绝对不能跑 FP16 精度的模型。必须转换为
Q4_K_M甚至Q3_K_M格式的 GGUF 文件,牺牲微小的精度来换取内存带宽压力的骤降。 -
禁用复杂的思维链 (Disable Thought/Reasoning): 在算力极差的收银机上进行“商品智能检索”,模型不需要也不应该进行长达十几分钟的逻辑推理。应该使用纯粹的指令遵循模型(Base 或 Instruct 版),要求其直接进行字符串匹配或实体提取,将响应时间压缩到 5 秒以内,否则将严重阻塞门店收银通道。
-
限定上下文窗口: 老旧 CPU 处理长文本的 Prompt 预填充(Prefill)阶段极慢。在实际业务流中,传递给本地模型的上下文必须经过严格裁剪(例如只传入当天的残损品类或故障代码),避免模型“生吞”大量历史日志。
文章摘自:https://www.cnblogs.com/wintersun/p/19723954