GoogLeNet 是 Google 在 2014 年 ILSVRC(ImageNet Large Scale Visual Recognition Challenge)比赛中提出的一种深度卷积神经网络模型,其关键创新在于引入了 Inception 模块,大大提高了网络的参数利用率与计算效率。
本文将通过完整的 PyTorch 实现,从背景、结构、参数计算、源码讲解四个方面系统阐述 GoogLeNet,并附带可运行代码与注释。
GoogLeNet 背景简介
GoogLeNet 出自论文《Going Deeper with Convolutions》,是 ILSVRC-2014 冠军模型,准确率远超同期网络如 AlexNet 与 VGG。
该网络最核心的创新是 Inception 模块,它将不同大小的卷积核(如 1×1、3×3、5×5)及池化操作并行组合,使得网络能提取多尺度特征,同时大幅减少参数量(尤其是 5×5 卷积前的降维 1×1 卷积)。
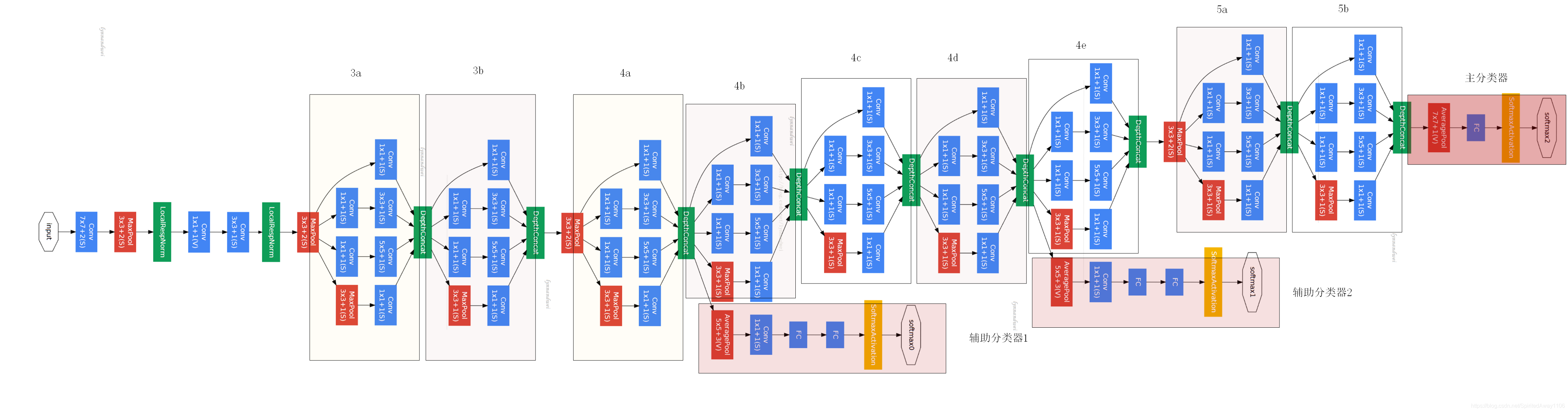
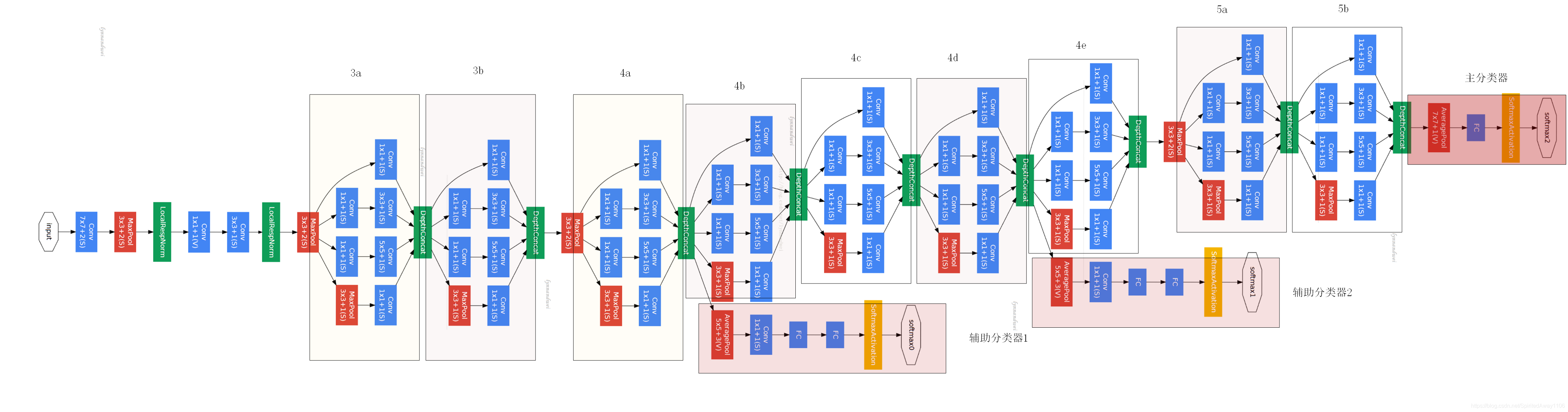
GoogLeNet 网络结构解析
GoogLeNet 并不是单纯的层叠卷积+池化,它引入的 Inception 模块 结构如下:
-
1×1 卷积分支:直接进行 1×1 卷积;
-
3×3 卷积分支:1×1 卷积降维 → 3×3 卷积;
-
5×5 卷积分支:1×1 卷积降维 → 5×5 卷积;
-
池化分支:3×3 最大池化 → 1×1 卷积。
每个 Inception 的输出会在通道维度上拼接,形成更丰富的特征表达。
整网包括如下模块组合:
-
卷积+池化(b1、b2)
-
多组 Inception + 池化(b3、b4、b5)
-
自适应平均池化 → 全连接层输出分类结果(b6)
GoogLeNet 每层参数计算分析(以 b1 为例)
以第一层为例:
nn.Conv2d(1, 64, 7, 2, 3)
-
输入通道数:1(灰度图)
-
输出通道数:64
-
卷积核大小:7×7
-
步幅:2
-
填充:3
输出尺寸为:
H_out = floor((224 + 2×3 - 7)/2) + 1 = 112
W_out = 112
输出张量尺寸 = [64, 112, 112]
池化层:
nn.MaxPool2d(3, 2, 1)
输出尺寸变为:
H_out = floor((112 + 2×1 - 3)/2) + 1 = 56
W_out = 56
输出张量尺寸 = [64, 56, 56]
类似方法可计算各层形状,尤其要注意每个 Inception 的输出通道数是四个分支通道数的 加和。
GoogLeNet 模型完整源码解释(含注释)
model.py – GoogLeNet 模型定义
import torch # 导入PyTorch主库
from torch import nn # 导入神经网络模块
from torchsummary import summary # 导入模型结构摘要工具
# 定义Inception模块
class Inception(nn.Module):
def __init__(
self, in_channels, out1x1, out3x3red, out3x3, out5x5red, out5x5, pool_proj
):
super(Inception, self).__init__() # 调用父类构造函数
self.ReLu = nn.ReLU() # 定义ReLU激活函数
self.branch1x1 = nn.Conv2d(in_channels, out1x1, kernel_size=1) # 1x1卷积分支
self.branch3x3 = nn.Sequential(
nn.Conv2d(in_channels, out3x3red, kernel_size=1), # 1x1卷积降维
nn.ReLU(), # 激活
nn.Conv2d(out3x3red, out3x3, kernel_size=3, padding=1), # 3x3卷积
)
self.branch5x5 = nn.Sequential(
nn.Conv2d(in_channels, out5x5red, kernel_size=1), # 1x1卷积降维
nn.ReLU(), # 激活
nn.Conv2d(out5x5red, out5x5, kernel_size=5, padding=2), # 5x5卷积
)
self.branch_pool = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1), # 3x3最大池化
nn.Conv2d(in_channels, pool_proj, kernel_size=1), # 1x1卷积
)
def forward(self, x):
p1 = self.ReLu(self.branch1x1(x)) # 1x1卷积分支前向传播
p2 = self.ReLu(self.branch3x3(x)) # 3x3卷积分支前向传播
p3 = self.ReLu(self.branch5x5(x)) # 5x5卷积分支前向传播
p4 = self.ReLu(self.branch_pool(x)) # 池化分支前向传播
outputs = [p1, p2, p3, p4] # 合并所有分支输出
return torch.cat(outputs, 1) # 在通道维度拼接
# 定义GoogLeNet主结构
class GoogLeNet(nn.Module):
def __init__(self, num_classes=10):
super(GoogLeNet, self).__init__() # 调用父类构造函数
self.b1 = nn.Sequential(
nn.Conv2d(1, 64, 7, 2, 3), # 7x7卷积,步长2,填充3
nn.ReLU(), # 激活
nn.MaxPool2d(3, 2, 1) # 3x3最大池化,步长2,填充1
)
self.b2 = nn.Sequential(
nn.Conv2d(64, 64, 1), # 1x1卷积
nn.ReLU(), # 激活
nn.Conv2d(64, 192, 3, 1, 1), # 3x3卷积
nn.ReLU(), # 激活
nn.MaxPool2d(3, 2, 1), # 3x3最大池化
)
self.b3 = nn.Sequential(
Inception(192, 64, 96, 128, 16, 32, 32), # 第一个Inception模块
Inception(256, 128, 128, 192, 32, 96, 64), # 第二个Inception模块
nn.MaxPool2d(3, 2, 1), # 池化
)
self.b4 = nn.Sequential(
Inception(480, 192, 96, 208, 16, 48, 64), # 多个Inception模块
Inception(512, 160, 112, 224, 24, 64, 64),
Inception(512, 128, 128, 256, 24, 64, 64),
Inception(512, 112, 128, 288, 32, 64, 64),
Inception(528, 256, 160, 320, 32, 128, 128),
nn.MaxPool2d(3, 2, 1), # 池化
)
self.b5 = nn.Sequential(
Inception(832, 256, 160, 320, 32, 128, 128), # 倒数第二个Inception
Inception(832, 384, 192, 384, 48, 128, 128), # 最后一个Inception
)
self.b6 = nn.Sequential(
nn.AdaptiveAvgPool2d((1, 1)), # 自适应平均池化到1x1
nn.Flatten(), # 展平
nn.Linear(1024, num_classes), # 全连接输出
)
# 权重初始化
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode="fan_out", nonlinearity="relu") # He初始化
if m.bias is not None:
nn.init.constant_(m.bias, 0) # 偏置初始化为0
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01) # 正态分布初始化
if m.bias is not None:
nn.init.constant_(m.bias, 0) # 偏置初始化为0
def forward(self, x):
x = self.b1(x) # 第一阶段
x = self.b2(x) # 第二阶段
x = self.b3(x) # 第三阶段
x = self.b4(x) # 第四阶段
x = self.b5(x) # 第五阶段
x = self.b6(x) # 分类阶段
return x # 返回输出
# 测试模型结构
if __name__ == "__main__":
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 选择设备
model = GoogLeNet().to(device=device) # 实例化模型并移动到设备
print(summary(model, (1, 224, 224))) # 打印模型结构摘要模型训练代码详解(train.py)
import os # 操作系统相关
import sys # Python运行环境相关
sys.path.append(os.getcwd()) # 添加当前目录到模块搜索路径
import time # 计时
from torchvision.datasets import FashionMNIST # FashionMNIST数据集
from torchvision import transforms # 数据预处理
from torch.utils.data import (
DataLoader, # 批量数据加载
random_split, # 数据集划分
)
import numpy as np # 数值计算
import matplotlib.pyplot as plt # 绘图
import torch # PyTorch主库
from torch import nn, optim # 神经网络和优化器
import copy # 深拷贝
import pandas as pd # 数据处理
from GoogLeNet_model.model import GoogLeNet # 导入GoogLeNet模型
batch_size = 32 # 批量大小
加载训练集与验证集
def train_val_date_load(): # 加载训练集和验证集
train_dataset = FashionMNIST(
root="./data", # 数据路径
train=True, # 加载训练集
download=True, # 自动下载
transform=transforms.Compose(
[
transforms.Resize(size=224), # 缩放到224x224
transforms.ToTensor(), # 转为Tensor
]
),
)
train_date, val_data = random_split(
train_dataset,
[
int(len(train_dataset) * 0.8), # 80%训练集
len(train_dataset) - int(len(train_dataset) * 0.8), # 20%验证集
],
)
train_loader = DataLoader(
dataset=train_date,
batch_size=batch_size,
shuffle=True,
num_workers=1, # 训练集加载器
)
val_loader = DataLoader(
dataset=val_data,
batch_size=batch_size,
shuffle=True,
num_workers=1, # 验证集加载器
)
return train_loader, val_loader # 返回加载器
训练主流程
def train_model_process(model, train_loader, val_loader, epochs=10): # 训练过程
device = "cuda" if torch.cuda.is_available() else "cpu" # 设备选择
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器
criterion = nn.CrossEntropyLoss() # 交叉熵损失
model.to(device) # 模型转到设备
best_model_wts = copy.deepcopy(model.state_dict()) # 最佳模型参数
best_acc = 0.0 # 最佳准确率
train_loss_all = [] # 训练损失
val_loss_all = [] # 验证损失
train_acc_all = [] # 训练准确率
val_acc_all = [] # 验证准确率
since = time.time() # 训练开始时间
for epoch in range(epochs): # 轮次循环
print(f"Epoch {epoch + 1}/{epochs}") # 当前轮次
train_loss = 0.0 # 本轮训练损失
train_correct = 0 # 本轮训练正确数
val_loss = 0.0 # 本轮验证损失
val_correct = 0 # 本轮验证正确数
train_num = 0 # 本轮训练样本数
val_num = 0 # 本轮验证样本数
for step, (images, labels) in enumerate(train_loader): # 训练集循环
images = images.to(device) # 图片转设备
labels = labels.to(device) # 标签转设备
model.train() # 训练模式
outputs = model(images) # 前向传播
pre_lab = torch.argmax(outputs, dim=1) # 预测标签
loss = criterion(outputs, labels) # 损失计算
optimizer.zero_grad() # 梯度清零
loss.backward() # 反向传播
optimizer.step() # 参数更新
train_loss += loss.item() * images.size(0) # 累计损失
train_correct += torch.sum(pre_lab == labels.data) # 累计正确数
train_num += labels.size(0) # 累计样本数
print(
"Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}, Acc:{:.4f}".format(
epoch + 1,
epochs,
step + 1,
len(train_loader),
loss.item(),
torch.sum((pre_lab == labels.data) / batch_size),
)
)
for step, (images, labels) in enumerate(val_loader): # 验证集循环
images = images.to(device)
labels = labels.to(device)
model.eval() # 评估模式
with torch.no_grad(): # 不计算梯度
outputs = model(images)
pre_lab = torch.argmax(outputs, dim=1)
loss = criterion(outputs, labels)
val_loss += loss.item() * images.size(0)
val_correct += torch.sum(pre_lab == labels.data)
val_num += labels.size(0)
print(
"Epoch [{}/{}], Step [{}/{}], Val Loss: {:.4f}, Acc:{:.4f}".format(
epoch + 1,
epochs,
step + 1,
len(val_loader),
loss.item(),
torch.sum((pre_lab == labels.data) / batch_size),
)
)
# 记录每轮训练和验证的损失与准确率
train_loss_all.append(train_loss / train_num)
val_loss_all.append(val_loss / val_num)
train_acc = train_correct.double() / train_num
val_acc = val_correct.double() / val_num
train_acc_all.append(train_acc.item())
val_acc_all.append(val_acc.item())
print(
f"Train Loss: {train_loss / train_num:.4f}, Train Acc: {train_acc:.4f}, "
f"Val Loss: {val_loss / val_num:.4f}, Val Acc: {val_acc:.4f}"
)
if val_acc_all[-1] > best_acc: # 更新最佳模型
best_acc = val_acc_all[-1]
best_model_wts = copy.deepcopy(model.state_dict())
time_elapsed = time.time() - since # 总耗时
print(
f"Training complete in {time_elapsed // 60:.0f}m {time_elapsed % 60:.0f}s\n"
f"Best val Acc: {best_acc:.4f}"
)
torch.save(model.state_dict(), "./models/google_net_best_model.pth") # 保存模型
train_process = pd.DataFrame(
data={
"epoch": range(1, epochs + 1), # 轮次
"train_loss_all": train_loss_all, # 训练损失
"val_loss_all": val_loss_all, # 验证损失
"train_acc_all": train_acc_all, # 训练准确率
"val_acc_all": val_acc_all, # 验证准确率
}
)
return train_process # 返回训练过程
训练过程可视化
def matplot_acc_loss(train_process): # 绘制曲线
plt.figure(figsize=(12, 5)) # 画布大小
plt.subplot(1, 2, 1) # 第1个子图
plt.plot(
train_process["epoch"], train_process["train_loss_all"], label="Train Loss"
)
plt.plot(
train_process["epoch"], train_process["val_loss_all"], label="Val Loss"
)
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.title("Loss vs Epoch")
plt.legend()
plt.subplot(1, 2, 2) # 第2个子图
plt.plot(
train_process["epoch"], train_process["train_acc_all"], label="Train Acc"
)
plt.plot(
train_process["epoch"], train_process["val_acc_all"], label="Val Acc"
)
plt.xlabel("Epoch")
plt.ylabel("Accuracy")
plt.title("Accuracy vs Epoch")
plt.legend()
plt.tight_layout() # 自动调整
plt.ion() # 交互模式
plt.show() # 显示图像
plt.savefig("./models/google_net_output.png") # 保存图片
训练主入口
if __name__ == "__main__": # 主程序入口
traindatam, valdata = train_val_date_load() # 加载数据
result = train_model_process(
GoogLeNet(), traindatam, valdata, 10
) # 训练模型
matplot_acc_loss(result) # 绘制曲线
模型测试代码详解(test.py)
import os # 操作系统相关
import sys # Python运行环境相关
sys.path.append(os.getcwd()) # 添加当前目录到模块搜索路径
import torch # PyTorch主库
from torch.utils.data import (
DataLoader, # 批量数据加载
random_split, # 数据集划分(未用到)
)
from torchvision import datasets, transforms # torchvision数据集和变换
from torchvision.datasets import FashionMNIST # FashionMNIST数据集
from GoogLeNet_model.model import GoogLeNet # 导入GoogLeNet模型
加载测试集
def test_data_load(): # 加载测试数据
test_dataset = FashionMNIST(
root="./data", # 数据路径
train=False, # 加载测试集
download=True, # 自动下载
transform=transforms.Compose(
[
transforms.Resize(size=224), # 缩放到224x224
transforms.ToTensor(), # 转为Tensor
]
),
)
test_loader = DataLoader(
dataset=test_dataset,
batch_size=128,
shuffle=True,
num_workers=1, # 测试集加载器
)
return test_loader # 返回加载器
print(test_data_load()) # 打印测试集加载器(调试)
测试过程
def test_model_process(model, test_loader): # 测试过程
device = "cuda" if torch.cuda.is_available() else "cpu" # 设备选择
model.to(device) # 模型转到设备
model.eval() # 评估模式
correct = 0 # 正确数
total = 0 # 总数
with torch.no_grad(): # 不计算梯度
for images, labels in test_loader: # 测试集循环
images, labels = images.to(device), labels.to(device)
outputs = model(images) # 前向传播
_, predicted = torch.max(outputs, 1) # 预测标签
total += labels.size(0) # 累计总数
correct += torch.sum(predicted == labels.data) # 累计正确数
accuracy = correct / total * 100 # 准确率(百分比)
print(f"Test Accuracy: {accuracy:.2f}%") # 打印准确率
主入口测试
if __name__ == "__main__": # 主程序入口
test_loader = test_data_load() # 加载测试集
model = GoogLeNet() # 实例化模型
model.load_state_dict(
torch.load("./models/google_net_best_model.pth")
) # 加载模型参数
test_model_process(model, test_loader) # 测试模型总结
本文完整地实现并解释了 GoogLeNet 模型的架构、参数计算与 PyTorch 训练/测试流程:
-
结构创新在于 Inception 模块 的多路径设计;
-
模型参数高效,训练稳定;
-
适配任何图像分类任务,代码可复用性强。