作者:陈铨,货拉拉大数据技术与产品部高级大数据工程师
首先为大家推荐这个 OceanBase 开源负责人老纪的公众号 “老纪的技术唠嗑局”,会持续更新和 #数据库、#AI、#技术架构 相关的各种技术内容。欢迎感兴趣的朋友们关注!
货拉拉成立于2013年,成长于粤港澳大湾区,是从事同城跨城货运、企业版物流服务、搬家、零担、跑腿、冷运、汽车租售及车后市场服务的互联网物流商城。截至2024年,货拉拉在全球拥有1670万月活用户和168万月活司机,业务覆盖全球11个市场、400+城市,并在全球设有6个数据中心。
一、大模型应用场景的挑战
货拉拉基于自身在物流领域 AI 落地的深厚积累,已在 14+ 个业务或部门,50+ 个真实业务场景探索和落地大模型应用。在引入大模型的过程中,面临着其在垂直领域知识的缺乏、时效性不足以及数据安全隐患等挑战。为应对这些问题,采用了业界较为通用的解决方案的解决方案——检索增强生成技术(Retrieval-Augmented Generation, RAG),通过引入外部数据,让大模型的回答从原来的“闭卷”变为“开卷”。RAG 通过整合领域专有知识、私有数据以及实时数据,显著降低了答案生成的不确定性,增强了数据安全性,从而有效解决了大模型的固有问题,提升了回答的准确性和实用性。

RAG 的核心在于将强大的语言模型能力与向量数据库的能力相结合,企业在实施 RAG 方案的过程中,通常需要结合一个向量数据库。向量数据库在处理多模数据和语义检索方面具有独特的优势,具体体现在以下几个方面:
存储非结构化数据:向量数据库能够有效存储和管理多模态数据,如音频、视频、图片和文本等。这些数据通常具有规模庞大、信息密度高、处理成本高的特点。
向量化表示:通过神经网络提取数据特征,将其转换为高维空间中的坐标点。向量化表示赋予数据语义表达能力,使其适用于相似性检索。
检索非结构化数据:通过计算向量间的距离(如内积或欧氏距离),识别出最相似的向量。检索过程涉及近邻图的遍历,需要进行大量的浮点运算,以实现高效的相似性匹配。

二、向量数据库选型思考
(一)原有架构与痛点
现有的架构包含基础设施层(CPU 和 GPU 两种机型)、存储层(向量数据库、ES等)、检索层(以图索引为主,多种检索类型)、接入层与入口层。并且在国内外共有 5 个集群,单集群内存配置在 380 +GB,单表数据量最大为2000万。

痛点1:动态 schema
随着业务的快速发展,频繁的字段增删操作成为常态。目前的解决方案是通过新建表、导入现有数据并最终重建索引来实现,这一流程相对繁琐。对于某些数据量较大的表,索引重建的耗时可能长达十几个小时。此外,索引重建过程对 CPU 和内存资源消耗极大,容易引发线上业务抖动。

痛点2:混合检索
向量检索在相似语义检索和多模态数据理解方面具有显著优势,而全文检索则在精准匹配、短文本及低频词汇检索上表现优异。在企业应用中,仅依赖单一检索方式难以满足业务对检索精度的高要求。为了弥补全文检索的缺陷,引入了Elasticsearch来作为全文检索引擎,这也导致了整体架构的复杂性增加,同时提升了系统的维护难度。对于用户而言,需要在应用层实现复杂的reranking逻辑,并且得到的相似度得分难以统一,从而增加了使用成本。因此,业务希望引入一站式混合索引能力。

痛点3:运维难度大
稳定性能力弱:向量数据库本身存在不稳定性,BUG 较多;缺乏专家经验使得问题排查变得困难;监控指标有限,问题定位困难。
扩展性不足:节点的横向扩展能力较差,数据迁移依赖人工;数据分片的管理和运维过程复杂。
权限认证能力弱:现有的权限认证机制不够完善,容易引发数据泄漏和安全问题,需要自行实现权限管理,增加了开发和运维的复杂性。
社区活跃度差:虽然项目仍在维护,但更新频率较低,社区贡献和开发者参与度有限,且社区功能和生态发展缓慢,无法满足业务未来的需求。

(二)选型标准与过程
基于上述痛点,我们在2024年底重新进行了一次向量数据库选型。选型的标准主要从业务诉求和运维诉求两方面来考虑,如下图所示。

在选型过程中,将10款向量数据库列入候选集,并通过多维度的详细对比,基于业务和运维痛点进行了第一轮筛选,首先,由于我司采用多云架构,因此希望数据库可以跨云部署,排除了云商数据库。其次,基于业务对于向量维度有更高的需求,排除PostgreSQL。另外从稳定性和权限管理方面考虑,排除了Weaviate。
经过初步筛选,Milvus、Elasticsearch 和 OceanBase 成为入围的候选产品。在第二轮筛选中,重点关注稳定性和运维成本:
Milvus:实时风控场景对向量数据库的稳定性要求极高。由于 Milvus 的整体架构较为复杂,确保其稳定性需要投入更多的运维成本。此外,Zilliz 的云版本和货拉拉的线上服务是跨地区部署,存在一定的稳定性隐患,因此暂时排除 Milvus。
OceanBase:在搭建 OceanBase 社区版环境后,进行了全面的向量能力测试,并与业务部门联合对线上真实场景进行了压力测试和对比。结果表明,OceanBase 在功能和性能方面均能满足业务需求。此外,OceanBase经过各大厂多年的打磨,稳定性方已经得到验证。同时,OceanBase 社区活跃度高,定期更新向量能力和性能,并提供技术支持。
Elasticsearch:Elasticsearch 在全文检索和混合检索能力上表现比较优秀,但基于公司内部团队的实际情况,最终在 Elasticsearch 和 OceanBase 之间选择了后者。

在完成选型后,面临的关键决策是选择自建还是上云。首先对这两种方案进行了详细对比,其次考虑到公司内部大量DB 都存在上云趋势,上云后能够实现很好的弹性扩缩容,同时有更可靠的SLA保障 ,且现阶段我们更关注的是业务接入,在运维上不希望投入过多的人力,最终选择在云上构建向量数据库底座。
三、向量数据库落地场景
(一)资损代码识别
资损代码识别是 OceanBase 向量检索在货拉拉的重要应用场景。由于研发质量问题或代码中的潜在漏洞,可能导致公司面临严重的财务损失。过去主要依靠人工审核来识别资损代码,效率低下且难以全面覆盖线上服务,导致资损风险无法完全规避。为解决这一问题,结合大模型能力与 OceanBase 向量检索,开发了自动化代码风险识别系统。该系统通过向量化历史案例数据并检索相似代码,利用大模型进行分析和判断资损风险,从而提高代码审查的效率和准确性,控制开发过程中的风险。

具体流程如下:首先,基于历史真实发生的资损代码场景和案例数据,通过大模型进行分类打标处理,得到数据集并经人工二次确认后,将数据灌入向量数据库。在开发者提交代码构建时,触发代码检测流程,将用户提交的代码与向量数据库中保存的资损代码进行向量相似度检索,将检索结果及相关数据提供给大模型进行资损风险判断。若判断代码存在风险,则熔断代码构建流程,防止其发布到线上平台。这一项目的实施,提高了资损代码识别的效率和准确性,为公司有效的规避潜在的资损风险。
(二)数仓 AI 答疑助手
数仓 AI 答疑项目是 OceanBase 向量检索在货拉拉的另一个重要落地场景,同时也是一个非常典型的应用场景。货拉拉的大数据数仓体量庞大,拥有几十万张Hive表,每天都有大量用户需要查询数据。然而,用户通常缺乏足够的业务背景知识,难以快速找到所需数据,只能通过数仓开发人员的帮助,这给数仓开发同学带来了巨大的工作负担。为了解决这一问题,我们将向量检索的能力应用于数仓 AI 答疑助手,提高数据查询效率,减轻了数仓开发人员的工作压力。

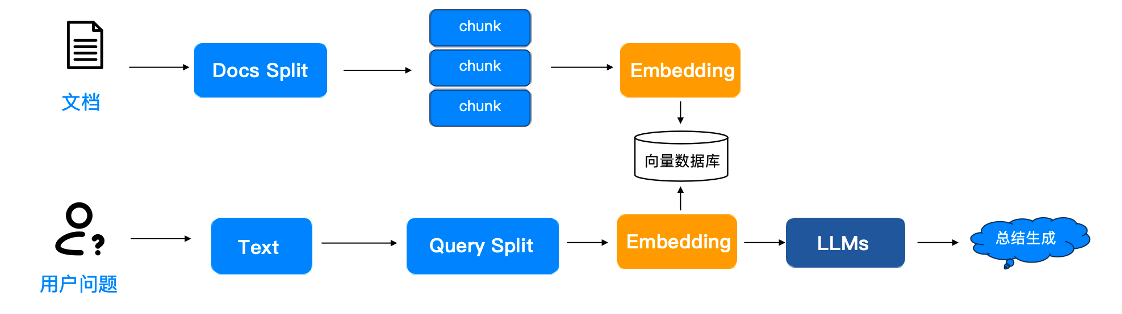
具体流程如下:首先,将库表的 Schema 信息、聊天答疑记录以及内部维护的文档进行处理,例如将库表信息处理成字段映射关系、将聊天答疑记录转化为 QA对形式等。然后,通过 Embedding 模型将这些数据转化为向量并存储到 OceanBase 向量数据库中。当用户提问时,系统首先进行意图识别,判断用户是找数场景、问口径场景还是普通知识答疑场景。接着,对用户的问题进行理解,将其复杂问题拆分成多个子问题,并进行实体识别,必要时采用多轮对话方式确定用户意图。之后进行知识召回,由于该场景对查询精度要求高,因此采用了多种检索方案,如向量检索、标量检索以及全文关键字检索。将召回的知识数据提供给重排序模型进行重排,将最相关答案提供给大模型进行总结生成,最终为用户提供准确的数据查询结果。这一项目的实施,降低用户找数门槛,减轻隐性的沟通负担,显著提高了数仓数据查询效率,降低了人力成本,提升了用户体验。
四、未来规划
随着 OceanBase 在货拉拉线上业务的稳定运行,未来将有更深入、更丰富的应用规划。
业务迁移:这一过程涉及支持一站式融合检索能力,业务改造适配,数据迁移等。
性能成本:随着用户数量的增加,性能和成本成为关注的焦点,将考虑引入标量量化索引 HNSW_SQ 或磁盘索引 IVF 等技术,同时支持表级别的 TTL 和冷热数据分层能力。
内部系统集成:将 OceanBase 集成到内部系统中,如大数据平台、监控告警系统和 DMS 数据库管理系统,以提供更丝滑的用户体验。
更多场景探索:正在在探索更多 OceanBase 的应用场景,如 OLAP、OBKV 等,希望解决在线存储的痛点。
老纪的技术唠嗑局 不仅希望能持续给大家带来有价值的技术分享,也希望能和大家一起为开源社区贡献力量。如果你对 OceanBase 开源社区认可,点亮一颗小星星 吧!你的每一个Star,都是我们努力的动力~
https://github.com/oceanbase/oceanbase