介绍
(1) 发表:Arxiv 6.12
(2) 挑战
主要探讨了基于 LLM 的 APR 的两个主要类别:代理和程序。尽管这两个范式都表现出希望,但它们依然表现出两个重要的局限性:
- 忽视历史修复经验:现有方法都忽略了从同一存储库中先前解决的问题中积累的宝贵历史经验,而实际上,软件项目在其演变过程中经常显示出重复的错误模式
- 静态提示会导致动态适应性有限:现有方法依赖于手动制作的静态提示来指导错误定位和补丁生成等任务,这些通用提示无法解决实际软件项目之间的实质性差异
① 代理方法:将 LLM 视为能够通过与工具进行交互,修改代码和运行测试来计划和执行操作以解决错误的自主代理
② 程序方法:遵循预定义和静态管道,其中 LLM 顺序执行了使用固定的提示和操作序列而无需自主决策
(3) 贡献:
受人类认知的双重记忆系统(情景记忆和语义记忆协同工作以支持人类的推理和决策)的启发,我们提出了 ExpeRepair,这是一种基于 LLM 的新型 Agent 框架,它通过双通道知识积累不断从历史修复经验中学习
方法
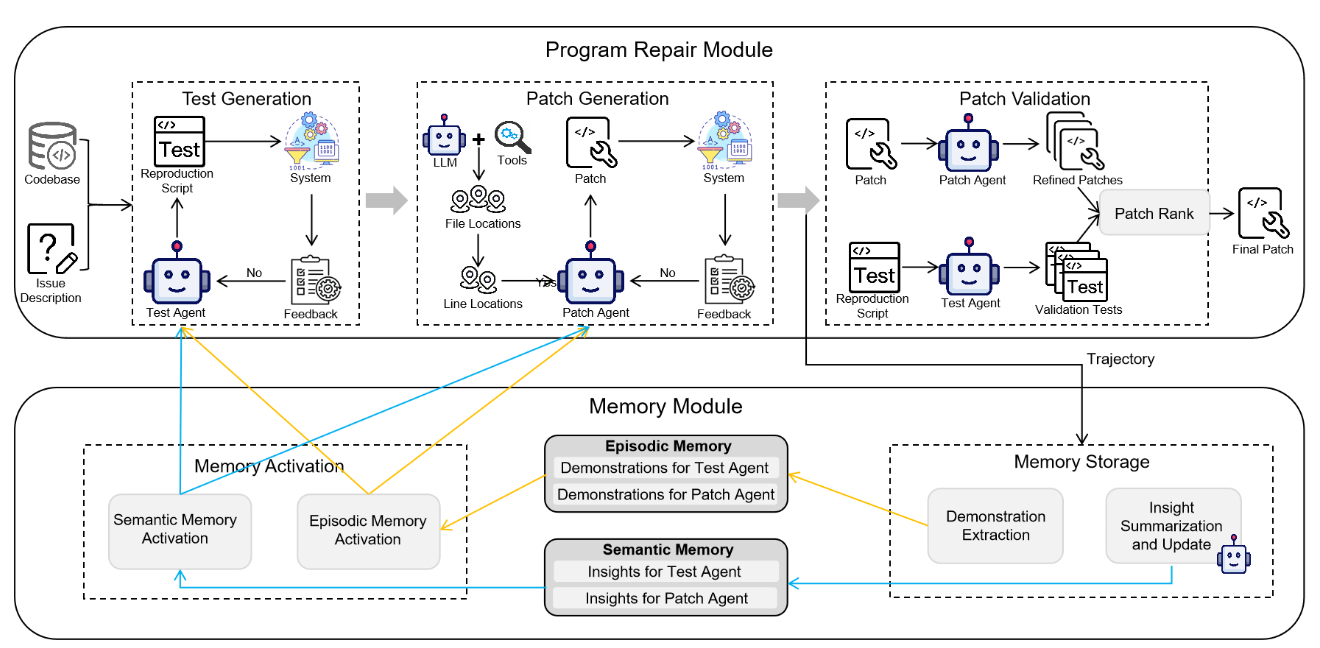
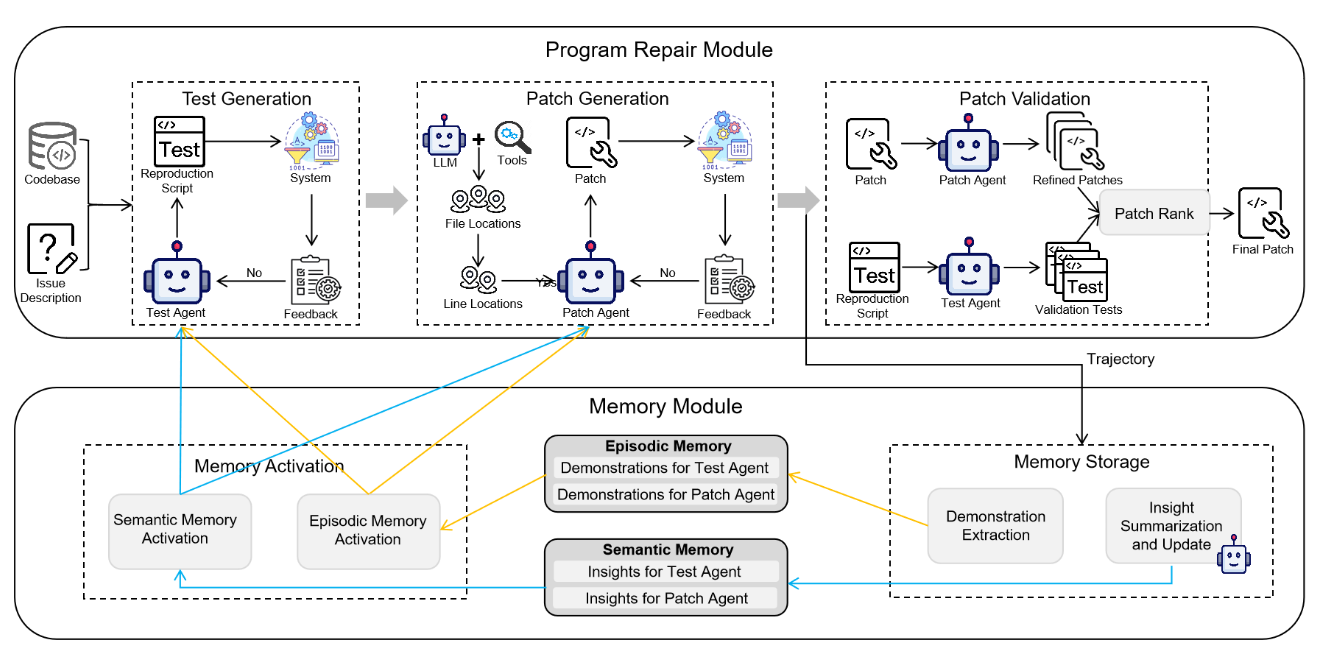
(1) 流程
- 初始化阶段:应用一组种子问题,LLM Agents 使用 ReAct 算法迭代的将各自的任务处理 \(z\) 次。随后为每个 Agent 提取特定问题的演示和见解并存储在情节记忆中和语义记忆中,从而实现热启动
- 推理阶段:首先从语义记忆中提取见解,然后从情节记忆中提取 top-k 相关演示,从而构建增强的提示。在 Agent 完成任务后提取新的演示和见解并更新两个记忆模块
(2) 模块
-
程序修复模块
① 测试生成:(现有方法通常会促使 LLM 仅基于问题描述生成复制测试脚本,这会导致两个主要局限性:忽略依赖关系或环境配置导致测试失败、测试脚本不足导致无法捕获全部问题范围) 具体而言,Test Agent 会从两个 Memory 中检索相关的演示并提取见解,这种迭代过程一直持续到产生有效的复现测试,或者已经完成了迭代次数上限
② 补丁生成:遵循先前工作 (SWE-Agent),ExpeRepair采用了层次结构的问题定位策略。然后也是迭代多次激活情节和语义记忆,并利用它们生成补丁。每次迭代通过 high temperature 的多个采样生成多种候选补丁,这个过程一直持续到至少一个候选补丁通过复现测试或达到迭代次数上限
③ 补丁验证:候选补丁成功通过了复现测试后,它不会立即被接受为最终补丁。复现测试通常集中在问题中描述的特定症状上,因此还要指示 Patch Agent 来解决诸如边缘案例处理、回归风险和遵守特定语言最佳实践等问题来修改和增强补丁程序。接下来指示Test Agent 创建针对边界条件的测试,我们将这些候选补丁及其相应的测试结果传递给专用的 Review Agent,该Review Agent 基于正确性,代码样式和遵守最佳实践的标准选择最终补丁
-
记忆模块
① 情节记忆:为 Test Agent 和 Patch Agent 存储了具体的可重复使用的历史修复和语义记忆,具体包含两种类型,分别是 (input, success output) 和 (input, failed output, feedback, success output) 。ExpeRepair 通过使用向量相似度 (例如 embedding) 或者基于 term 的检索方法 (例如 BM25),检索 top-k 的样例并加入到 Agent 的提示中
② 语义记忆:每次维修尝试结束时,ExpeRepair 执行了一个总结和更新过程,指示 LLM 产生反思性见解。然后将新汇总的见解与存储在语义内存中的现有见解进行比较,并且定义了三个操作 (a.添加: 引入新的见解,如果它提出了新颖或有价值的观察;b.删除:消除矛盾、过时或多余的见解;c.编辑:合并或完善重叠见解,以提高清晰度和实用性)。我们还限制了每个 Agent 的最大见解条目数量;如果达到此限制,则在添加新的见解之前,必须删除现有的见解。ExpeRepair 通过提取所有存储的见解来激活语义内存
实验
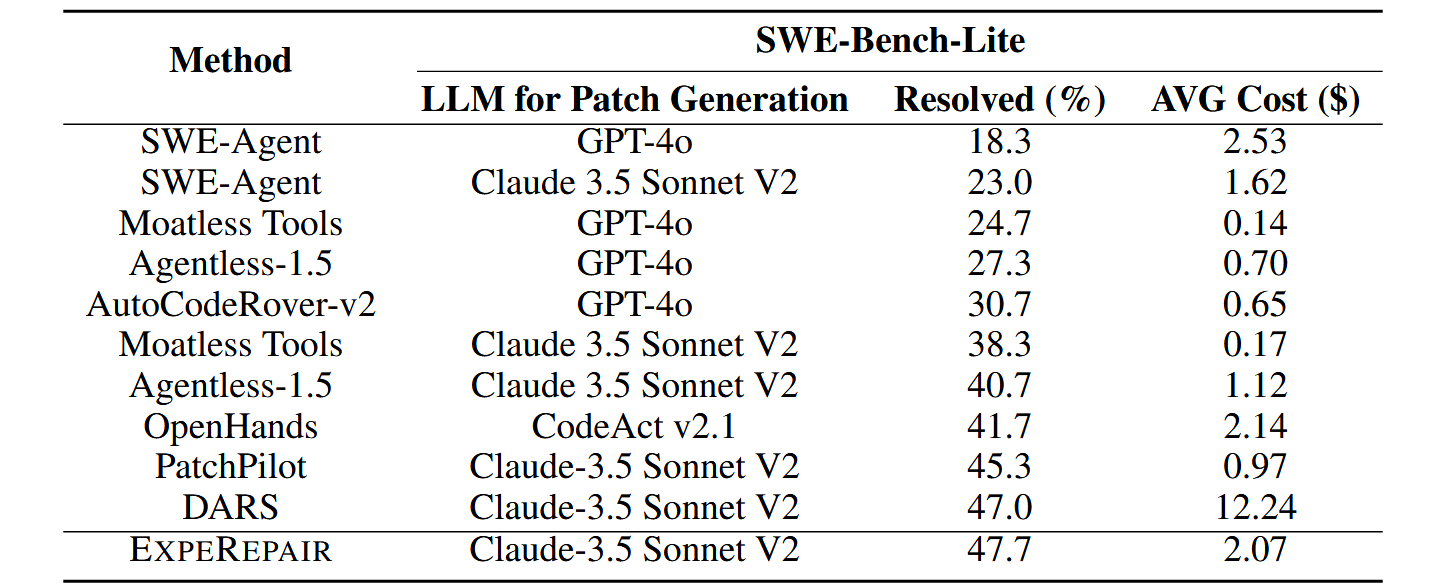
实验部分较为简单,总之实现了 SWE-bench-lite 上的 SOTA 效果
总结
个人认为这篇工作还是有很多缺点的,提出的两个挑战(历史经验和自适应 prompt)其实 APR 领域内现有工作早就做过了,并不是论文说的那样。所以我觉得这篇工作只是引入了新的有效方法,但其实并没有提出很新的见解。此外,对方法内容的介绍实在有点难以读懂