作者,钟兴宇
你是否遇到过这样的场景:辛辛苦苦定位一个 Bug,却发现整个项目有成千上万行代码,不知从何找起?
一个简单的“搜索”居然比修复 Bug 更折磨人。
这并不是你的错,现代软件工程的规模早已超过“按关键词查找”的时代,光靠 Ctrl+F 或 grep 就像在超市里只看标签找东西——难免遗漏真正想要的商品。
别担心,本文带你用通俗易懂的方式了解代码搜索技术的四次飞跃。这些飞跃不仅改变了工程师的工作方式,也帮助普通开发者更快地定位问题、复用代码。
作为一名长期在大型代码库中摸爬滚打的工程师,我亲历了代码搜索从文本匹配到语义理解、结构导航直至智能体辅助的演化。本文试图用白话文为你梳理这场变革,并分享一些在企业实践中引入向量化索引和私有化 RAG 的经验,哪怕刚入行的小白也能看懂。
01 代码搜索演进
过去,代码搜索技术经历了由“文本匹配”到“语义检索”,再到“图索引”和“智能体搜索”的持续演进,其发展脉络可概括如下:
一、传统文本匹配时代
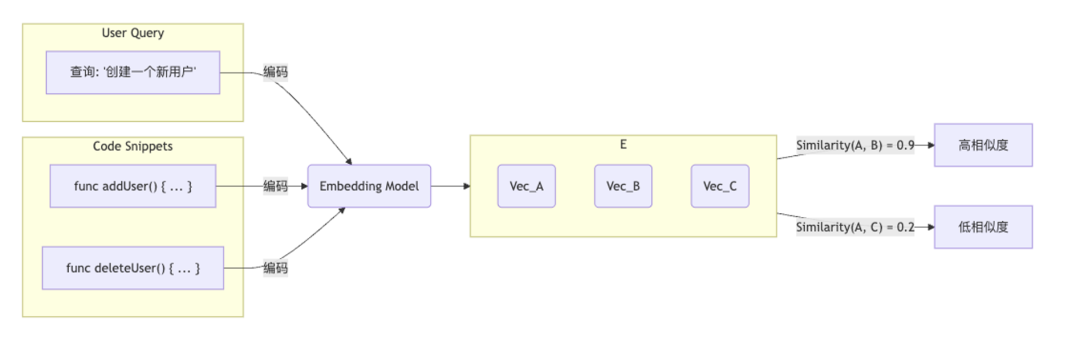
传统时代,我们的代码搜索方式主要依赖文本匹配,开发者通常使用 Ctrl+F 在源码中查找关键字,从而找到相应内容,检索结果完全受制于字面匹配,既缺乏对语义的洞察,也忽略了代码内部的结构信息(如函数调用、类继承等),造成关系丢失。例如查询“创建用户”,由于匹配不到“创建”关键字,找不到 addUser( ) ,且代码缺乏对应注释时,该方法几乎无法返回有效结果,存在明显局限性。
二、语义检索时代:让搜索读懂代码
大语言模型兴起后,开启了语义检索时代,代码被转化为高维向量(Embedding),并存储于向量数据库。通过向量模型进行相似度检索,用户即便使用自然语言描述需求,也能召回在功能或意图上相近的代码片段,如查询“创建用户”,大模型可以理解“创建”=“add”,突破了关键词的限制,真正理解代码的语义意图。
三、图索引革命:在代码的关系网中导航
近期研究进一步引入图索引,将代码仓库中包含的图关系,例如函数调用的依赖关系、类继承等,可以抽象为图:节点表示函数、类、文件等实体,边表示调用、继承、依赖等关系。基于图的检索不仅能回答“哪些函数调用了当前函数”,还能支持跨文件、跨模块的结构化查询,弥补了向量检索在代码拓扑理解上的不足。
四、智能体搜索时代:让“搜索”本身成为一种推理
目前还有一种以 OpenAI 的 Code Interpreter 或字节的 CodeFuse-Tree 为代表的 IDE 内置 Agent,通过对话式界面实时理解开发者意图,并主动在完整代码库中检索、聚合相关片段,甚至生成可运行示例。该模式融合了语义、图结构与上下文感知能力,标志着代码搜索正从“检索”走向“生成式辅助开发”。
核心飞跃:从文本到向量
从文本检索到向量检索的演进,其核心思想是将代码和自然语言查询,用深度学习模型(如 CodeBERT)嵌入到同一个高维向量空间中。搜索方式不再是匹配字符串,而是计算查询向量与代码片段向量的余弦相似度。从此搜索开始具备“理解”能力,能够根据意图而非字面量进行查找,使传统搜索方式得到变革。
具体流程如下:
-
离线构建索引:采用预训练模型将整个代码库逐片段编码为高维向量,建立全局向量索引。
-
在线查询:用户以自然语言提出问题后,系统首先将该查询向量化;随后计算查询向量与索引中所有代码向量的余弦相似度,召回相似度最高的若干片段,实现语义层面的精准匹配。

但挑战随之而来
向量检索的有效性并非天然具备,最初常用的向量化模型所提供的数据匹配大部分是文本到文本的相似度匹配,很少有文本到代码的相似度匹配,模型的“理解”能力完全取决于训练数据的质量。
近期 CORNSTACK, SWERANK 等论文中提供了一些解决方案,通过以下策略可以提升模型对代码语义的捕捉能力:
-
一致性过滤:筛选高质量的正样本,提高文本查询与其对应代码片段的匹配度,强化文本–代码映射。
-
硬负样本挖掘:找到“高仿”的错误答案,作为负例进行训练,训练模型的辦别力。
受限于训练数据规模与质量,该方向仍处于探索阶段,整体效果仍在持续迭代中。
从“查找”到“导航”
关于图索引的代码检索,近期也取得了一些最新进展:在传统的旧视角,大语言模型只能通过文件夹结构粗粒度地“观察”仓库,难以捕捉函数、类、模块间的依赖关系,仅凭文件名推断语义关联既低效又不准确。近期发现将完整代码库建模为有向异构图,并持久化至图数据库,核心思想是代码库不是一堆独立的文本,而是一个互相关联的网络,之间有相关的图关系,如继承、接口实现、函数调用等,我们完全可以将它们存到我们的图数据库中。

代表框架有 LocAgent & OrcaLoca:
- LocAgent:多跳推提供了如图遍历工具 TraverseGraph,允许 LLM 在代码关系图中进行多跳推理,一次性探索复杂的调用链。
- OrcaLoca: 智能过滤
利用图中节点间的距离来动态修剪和排序搜索结果,确保 LLM 的注意力始终聚焦在最相关的代码区域。
搜索的范式转变
当前代码检索领域最显著的变化是搜索的范式转变****,搜索不再是一个单一、静态的动作,而是由 #LLM 智能体主导的、动态的、多步骤的调查过程。
旧模式:用户提问 ️ 系统返回结果列表;
新模式(Agentic Search):#Agent 接收任务 ️ 自主规划 ️ 迭代式搜索与分析 ️ 定位解决方案。
智能体搜索的三大策略
当前智能体搜索常见的三大策略主要有:
1. 规划驱动搜索(PlanSearch, CODEPLAN)
在行动前先生成高层次的计划,让搜索更有目的性。
2. 交互式搜索循环(SWE-Agent)
执行“搜索-分析-再搜索”的闭环操作,持续调查。
3. 策略化搜索(OrcaLoca)
使用优先级队列管理搜索意图,并能分解复杂查询。
代码 Agent 搜索
以 SWE-Agent 为例,介绍几个命令的使用方式:

- find_file 命令的使用
find_file 命令专用于在仓库中搜索特定的文件名,每次查询最多返回50个结果,帮助代理快速定位所需文件。 - search_file 和 search_dir 命令
search_file 和 search_dir 命令用于在子目录中的文件(s)中查找字符串,同样每次查询最多返回50个结果,以便在大量文件中高效地进行文本搜索。 - 搜索结果的摘要输出
这些命令在搜索文件名或字符串时,会输出搜索结果的摘要,为代理提供快速概览,从而加快信息检索和决策过程。
总结:代码搜索的四次飞跃
总体来说,整个代码搜索的演进历程包括如下四次飞跃:从最初的文本匹配、到语义检索、图索引,再到智能体搜索。
① 文本匹配 ️ 关键词查找
② 语义检索 ️ 意图理解
③ 图索引 ️ 关系导航
④ 智能体搜索 ️ 自主调查与推理
02 LLM 与私有代码库
大模型虽拥有海量的通用编程知识,能写诗、能编码,却对企业的私有代码库“零认知”,容易产生“幻觉” (Hallucination),如何让强大的 LLM 安全、准确地理解并运用私有代码库是我们当前使用大模型的核心矛盾。
代码仓库语义化步骤
尽管 LLM 上下文长度已有提升,但仍无法一次性处理整个代码库。因此,我们可以采用以下解析流程:首先将代码按函数粒度切割独立处理;其次为每个函数生成功能描述文本;最后将这些解释内容转换为向量表示并存储于 #OceanBase 数据库中,为后续精准匹配与检索奠定基础。

该方案在保障数据安全的前提下,实现了对私有化代码的语义级理解与快速定位,下方的演示视频将展示其完整交互过程。
AI 驱动的开发计划生成过程
AI 驱动的开发计划整体的开发流程图如下图所示:我们首先利用 AI 根据用户的修改需求生成针对性问题,并让 AI 自主在代码仓库中检索相关内容以获取答案。AI 随后评估信息是否充分——若不足,则继续此问询循环;若已足够,则生成详细开发计划。用户可通过对话方式对该计划进行调整完善。

03 CodeRepoIndex 项目
CodeRepoIndex 是我们正在尝试的一个项目,是一个代码索引转换工具,可以将代码仓库转换为向量化索引的开源工具,核心功能包括代码解析索引和提供语义搜索接口。对于用户来说,只需要提供代码仓库地址和记录语音搜索接口,省去了代码切割、存储、向量化等一系列繁琐操作,非常轻便易用。目前的应用场景主要有以下三个:
应用场景
自然语言搜索代码
输入自然语言描述,返回最相关的代码片段。
智能问答系统
基于 RAG 技术,理解项目细节并提供准确回答。
代码生成与重构建议
生成定制化代码,分析并建议重构模式。
04 未来展望:多模态索引与专属助手
未来的代码搜索不仅仅是检索代码,还需要结合多模态信息,如设计文档、单元测试、提交记录等,为 LLM 提供更丰富的上下文。此外,提升数据流和依赖关系的理解能力,也是下一代工具的研究重点。
1. 多模态索引
对于数据源来说,索引是非常重要的一个方面,后续我们将关注索引代码、文档、注释、Commit 信息等作为索引信息,提供更全面的上下文。
2. 深度代码理解
对于代码索引工作者来说,理解用户意图是非常关键的,因此需要理解数据流、依赖关系,提升代码搜索和生成的准确性。
3. 专属 AI 编程助手
提升易用性,人人都能拥有懂你项目的 AI 编程助手,提高开发效率。
最终目标是让每个开发者都拥有一位熟悉项目背景的 AI 编程助手。它不仅能回答“这个函数在哪”,还能根据团队编码规范自动生成补丁、给出重构建议,甚至在你编码时实时提示潜在错误。
05 写在最后
回过头来看,我们已经走过了四个阶段:从依赖关键词的文本匹配,到让模型“听懂”自然语言的语义检索,再到利用图索引理解代码之间的关系,最终迈向能自主分析的智能体搜索。每一步都让搜索更聪明,也让普通开发者更容易在庞大的仓库中找到答案。
最后为大家推荐这个 OceanBase 开源负责人老纪的公众号「老纪的技术唠嗑局」,会持续更新和 #数据库、#AI、#技术架构 相关的各种技术内容。欢迎感兴趣的朋友们关注!
「老纪的技术唠嗑局」不仅希望能持续给大家带来有价值的技术分享,也希望能和大家一起为开源社区贡献一份力量。如果你对 OceanBase 开源社区认可,点亮一颗小星星吧!你的每一个Star,都是我们努力的动力。