2 环境验证
2.1 安装
参考:https://developer.nvidia.com/cuda-downloads
然后安装CuPy,再安装PyCUDA。
验证安装:
# nvidia-smi Wed Aug 20 11:02:36 2025 +-----------------------------------------------------------------------------------------+ | NVIDIA-SMI 570.124.06 Driver Version: 570.124.06 CUDA Version: 12.8 | |-----------------------------------------+------------------------+----------------------+ | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |=========================================+========================+======================| | 0 NVIDIA L20 Off | 00000000:02:00.0 Off | 0 | | N/A 49C P8 26W / 350W | 14MiB / 46068MiB | 0% Default | | | | N/A | +-----------------------------------------+------------------------+----------------------+ +-----------------------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=========================================================================================| | 0 N/A N/A 2990 G /usr/libexec/Xorg 4MiB | +-----------------------------------------------------------------------------------------+ # nvcc -V nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2025 NVIDIA Corporation Built on Wed_Jan_15_19:21:50_PST_2025 Cuda compilation tools, release 12.8, V12.8.61 Build cuda_12.8.r12.8/compiler.35404655_0
如果找不到以上命令则需要设置环境变量:
export PATH=/usr/local/cuda/bin:$PATH export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH
python验证:
>>> import cupy as cp
... print("CuPy version:", cp.__version__)
... print("CUDA runtime version:", cp.cuda.runtime.runtimeGetVersion())
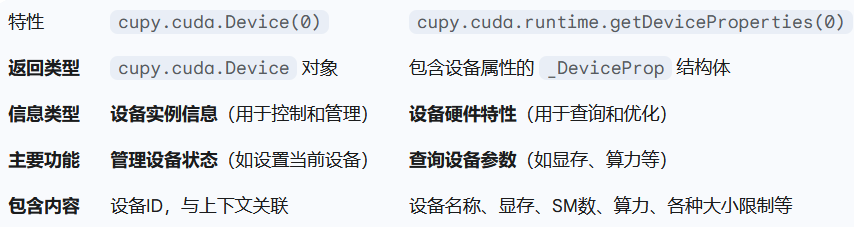
... print("Our available device:", cp.cuda.runtime.getDeviceProperties(0)['name'])
...
CuPy version: 13.6.0
CUDA runtime version: 12080
Our available device: b'NVIDIA L20'
>>> dir(cp.cuda.runtime)
['CUDARuntimeError', 'CUDA_C_16F', 'CUDA_C_32F', 'CUDA_C_64F', 'CUDA_C_8I', 'CUDA_C_8U', 'CUDA_R_16F', 'CUDA_R_32F', 'CUDA_R_64F', 'CUDA_R_8I', 'CUDA_R_8U', 'MemPoolProps', 'PointerAttributes', '_ThreadLocal', '__builtins__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__pyx_capi__', '__pyx_unpickle_MemPoolProps', '__pyx_unpickle_PointerAttributes', '__pyx_unpickle__ThreadLocal', '__spec__', '__test__', '_deviceEnsurePeerAccess', '_export_enum', '_getCUDAMajorVersion', '_getLocalRuntimeVersion', '_launchHostFuncUnmanaged', '_sys', '_threading', 'check_status', 'createSurfaceObject', 'createTextureObject', 'cudaAddressModeBorder', 'cudaAddressModeClamp', 'cudaAddressModeMirror', 'cudaAddressModeWrap', 'cudaArrayDefault', 'cudaArraySurfaceLoadStore', 'cudaChannelFormatKindFloat', 'cudaChannelFormatKindNone', 'cudaChannelFormatKindSigned', 'cudaChannelFormatKindUnsigned', 'cudaCpuDeviceId', 'cudaDevAttrAsyncEngineCount', 'cudaDevAttrCanFlushRemoteWrites', 'cudaDevAttrCanMapHostMemory', 'cudaDevAttrCanUseHostPointerForRegisteredMem', 'cudaDevAttrClockRate', 'cudaDevAttrComputeMode', 'cudaDevAttrComputePreemptionSupported', 'cudaDevAttrConcurrentKernels', 'cudaDevAttrConcurrentManagedAccess', 'cudaDevAttrCooperativeLaunch', 'cudaDevAttrCooperativeMultiDeviceLaunch', 'cudaDevAttrDirectManagedMemAccessFromHost', 'cudaDevAttrEccEnabled', 'cudaDevAttrGPUDirectRDMAFlushWritesOptions', 'cudaDevAttrGPUDirectRDMASupported', 'cudaDevAttrGPUDirectRDMAWritesOrdering', 'cudaDevAttrGlobalL1CacheSupported', 'cudaDevAttrGlobalMemoryBusWidth', 'cudaDevAttrGpuOverlap', 'cudaDevAttrHostNativeAtomicSupported', 'cudaDevAttrHostRegisterReadOnlySupported', 'cudaDevAttrHostRegisterSupported', 'cudaDevAttrIntegrated', 'cudaDevAttrIsMultiGpuBoard', 'cudaDevAttrKernelExecTimeout', 'cudaDevAttrL2CacheSize', 'cudaDevAttrLocalL1CacheSupported', 'cudaDevAttrManagedMemory', 'cudaDevAttrMaxBlockDimX', 'cudaDevAttrMaxBlockDimY', 'cudaDevAttrMaxBlockDimZ', 'cudaDevAttrMaxBlocksPerMultiprocessor', 'cudaDevAttrMaxGridDimX', 'cudaDevAttrMaxGridDimY', 'cudaDevAttrMaxGridDimZ', 'cudaDevAttrMaxPitch', 'cudaDevAttrMaxRegistersPerBlock', 'cudaDevAttrMaxRegistersPerMultiprocessor', 'cudaDevAttrMaxSharedMemoryPerBlock', 'cudaDevAttrMaxSharedMemoryPerBlockOptin', 'cudaDevAttrMaxSharedMemoryPerMultiprocessor', 'cudaDevAttrMaxSurface1DLayeredLayers', 'cudaDevAttrMaxSurface1DLayeredWidth', 'cudaDevAttrMaxSurface1DWidth', 'cudaDevAttrMaxSurface2DHeight', 'cudaDevAttrMaxSurface2DLayeredHeight', 'cudaDevAttrMaxSurface2DLayeredLayers', 'cudaDevAttrMaxSurface2DLayeredWidth', 'cudaDevAttrMaxSurface2DWidth', 'cudaDevAttrMaxSurface3DDepth', 'cudaDevAttrMaxSurface3DHeight', 'cudaDevAttrMaxSurface3DWidth', 'cudaDevAttrMaxSurfaceCubemapLayeredLayers', 'cudaDevAttrMaxSurfaceCubemapLayeredWidth', 'cudaDevAttrMaxSurfaceCubemapWidth', 'cudaDevAttrMaxTexture1DLayeredLayers', 'cudaDevAttrMaxTexture1DLayeredWidth', 'cudaDevAttrMaxTexture1DLinearWidth', 'cudaDevAttrMaxTexture1DMipmappedWidth', 'cudaDevAttrMaxTexture1DWidth', 'cudaDevAttrMaxTexture2DGatherHeight', 'cudaDevAttrMaxTexture2DGatherWidth', 'cudaDevAttrMaxTexture2DHeight', 'cudaDevAttrMaxTexture2DLayeredHeight', 'cudaDevAttrMaxTexture2DLayeredLayers', 'cudaDevAttrMaxTexture2DLayeredWidth', 'cudaDevAttrMaxTexture2DLinearHeight', 'cudaDevAttrMaxTexture2DLinearPitch', 'cudaDevAttrMaxTexture2DLinearWidth', 'cudaDevAttrMaxTexture2DMipmappedHeight', 'cudaDevAttrMaxTexture2DMipmappedWidth', 'cudaDevAttrMaxTexture2DWidth', 'cudaDevAttrMaxTexture3DDepth', 'cudaDevAttrMaxTexture3DDepthAlt', 'cudaDevAttrMaxTexture3DHeight', 'cudaDevAttrMaxTexture3DHeightAlt', 'cudaDevAttrMaxTexture3DWidth', 'cudaDevAttrMaxTexture3DWidthAlt', 'cudaDevAttrMaxTextureCubemapLayeredLayers', 'cudaDevAttrMaxTextureCubemapLayeredWidth', 'cudaDevAttrMaxTextureCubemapWidth', 'cudaDevAttrMaxThreadsPerBlock', 'cudaDevAttrMaxThreadsPerMultiProcessor', 'cudaDevAttrMaxTimelineSemaphoreInteropSupported', 'cudaDevAttrMemoryClockRate', 'cudaDevAttrMemoryPoolSupportedHandleTypes', 'cudaDevAttrMemoryPoolsSupported', 'cudaDevAttrMultiGpuBoardGroupID', 'cudaDevAttrMultiProcessorCount', 'cudaDevAttrPageableMemoryAccess', 'cudaDevAttrPageableMemoryAccessUsesHostPageTables', 'cudaDevAttrPciBusId', 'cudaDevAttrPciDeviceId', 'cudaDevAttrPciDomainId', 'cudaDevAttrReserved92', 'cudaDevAttrReserved93', 'cudaDevAttrReserved94', 'cudaDevAttrReservedSharedMemoryPerBlock', 'cudaDevAttrSingleToDoublePrecisionPerfRatio', 'cudaDevAttrSparseCudaArraySupported', 'cudaDevAttrStreamPrioritiesSupported', 'cudaDevAttrSurfaceAlignment', 'cudaDevAttrTccDriver', 'cudaDevAttrTextureAlignment', 'cudaDevAttrTexturePitchAlignment', 'cudaDevAttrTotalConstantMemory', 'cudaDevAttrUnifiedAddressing', 'cudaDevAttrWarpSize', 'cudaFilterModeLinear', 'cudaFilterModePoint', 'cudaInvalidDeviceId', 'cudaIpcMemLazyEnablePeerAccess', 'cudaLimitDevRuntimePendingLaunchCount', 'cudaLimitDevRuntimeSyncDepth', 'cudaLimitMallocHeapSize', 'cudaLimitMaxL2FetchGranularity', 'cudaLimitPrintfFifoSize', 'cudaLimitStackSize', 'cudaMemAdviseSetAccessedBy', 'cudaMemAdviseSetPreferredLocation', 'cudaMemAdviseSetReadMostly', 'cudaMemAdviseUnsetAccessedBy', 'cudaMemAdviseUnsetPreferredLocation', 'cudaMemAdviseUnsetReadMostly', 'cudaMemAllocationTypePinned', 'cudaMemAttachGlobal', 'cudaMemAttachHost', 'cudaMemAttachSingle', 'cudaMemHandleTypeNone', 'cudaMemHandleTypePosixFileDescriptor', 'cudaMemLocationTypeDevice', 'cudaMemLocationTypeHost', 'cudaMemLocationTypeHostNuma', 'cudaMemLocationTypeHostNumaCurrent', 'cudaMemLocationTypeInvalid', 'cudaMemPoolAttrReleaseThreshold', 'cudaMemPoolAttrReservedMemCurrent', 'cudaMemPoolAttrReservedMemHigh', 'cudaMemPoolAttrUsedMemCurrent', 'cudaMemPoolAttrUsedMemHigh', 'cudaMemPoolReuseAllowInternalDependencies', 'cudaMemPoolReuseAllowOpportunistic', 'cudaMemPoolReuseFollowEventDependencies', 'cudaMemoryTypeDevice', 'cudaMemoryTypeHost', 'cudaReadModeElementType', 'cudaReadModeNormalizedFloat', 'cudaResourceTypeArray', 'cudaResourceTypeLinear', 'cudaResourceTypeMipmappedArray', 'cudaResourceTypePitch2D', 'destroySurfaceObject', 'destroyTextureObject', 'deviceCanAccessPeer', 'deviceDisablePeerAccess', 'deviceEnablePeerAccess', 'deviceGetAttribute', 'deviceGetByPCIBusId', 'deviceGetDefaultMemPool', 'deviceGetLimit', 'deviceGetMemPool', 'deviceGetPCIBusId', 'deviceSetLimit', 'deviceSetMemPool', 'deviceSynchronize', 'driverGetVersion', 'eventBlockingSync', 'eventCreate', 'eventCreateWithFlags', 'eventDefault', 'eventDestroy', 'eventDisableTiming', 'eventElapsedTime', 'eventInterprocess', 'eventQuery', 'eventRecord', 'eventSynchronize', 'free', 'freeArray', 'freeAsync', 'freeHost', 'getDevice', 'getDeviceCount', 'getDeviceProperties', 'graphDestroy', 'graphExecDestroy', 'graphInstantiate', 'graphLaunch', 'graphUpload', 'hostAlloc', 'hostAllocDefault', 'hostAllocMapped', 'hostAllocPortable', 'hostAllocWriteCombined', 'hostRegister', 'hostUnregister', 'ipcCloseMemHandle', 'ipcGetEventHandle', 'ipcGetMemHandle', 'ipcOpenEventHandle', 'ipcOpenMemHandle', 'is_hip', 'launchHostFunc', 'malloc', 'malloc3DArray', 'mallocArray', 'mallocAsync', 'mallocFromPoolAsync', 'mallocManaged', 'memAdvise', 'memGetInfo', 'memPoolCreate', 'memPoolDestroy', 'memPoolGetAttribute', 'memPoolSetAttribute', 'memPoolTrimTo', 'memPrefetchAsync', 'memcpy', 'memcpy2D', 'memcpy2DAsync', 'memcpy2DFromArray', 'memcpy2DFromArrayAsync', 'memcpy2DToArray', 'memcpy2DToArrayAsync', 'memcpy3D', 'memcpy3DAsync', 'memcpyAsync', 'memcpyDefault', 'memcpyDeviceToDevice', 'memcpyDeviceToHost', 'memcpyHostToDevice', 'memcpyHostToHost', 'memcpyPeer', 'memcpyPeerAsync', 'memoryTypeDevice', 'memoryTypeHost', 'memoryTypeManaged', 'memoryTypeUnregistered', 'memset', 'memsetAsync', 'pointerGetAttributes', 'profilerStart', 'profilerStop', 'runtimeGetVersion', 'setDevice', 'streamAddCallback', 'streamBeginCapture', 'streamCaptureModeGlobal', 'streamCaptureModeRelaxed', 'streamCaptureModeThreadLocal', 'streamCaptureStatusActive', 'streamCaptureStatusInvalidated', 'streamCaptureStatusNone', 'streamCreate', 'streamCreateWithFlags', 'streamDefault', 'streamDestroy', 'streamEndCapture', 'streamIsCapturing', 'streamLegacy', 'streamNonBlocking', 'streamPerThread', 'streamQuery', 'streamSynchronize', 'streamWaitEvent']
2.2 使用设备查询验证GPU
我们已经安装了 CUDA 驱动程序和工具包,并确认我们的系统能够识别 GPU。在深入了解细节之前,让我们先仔细看看机器中的硬件。设备查询让我们能够查看 GPU 的所有重要细节,例如它拥有多少个多处理器、可用内存、支持的计算能力以及其他影响 CUDA 编程的功能。
运行设备查询时,它会显示您的安装已成功,并帮助我们调整内核和库设置以匹配您的硬件。这使得我们的编程在未来更加健壮、可预测且性能更佳。
2.2.1 运行设备查询
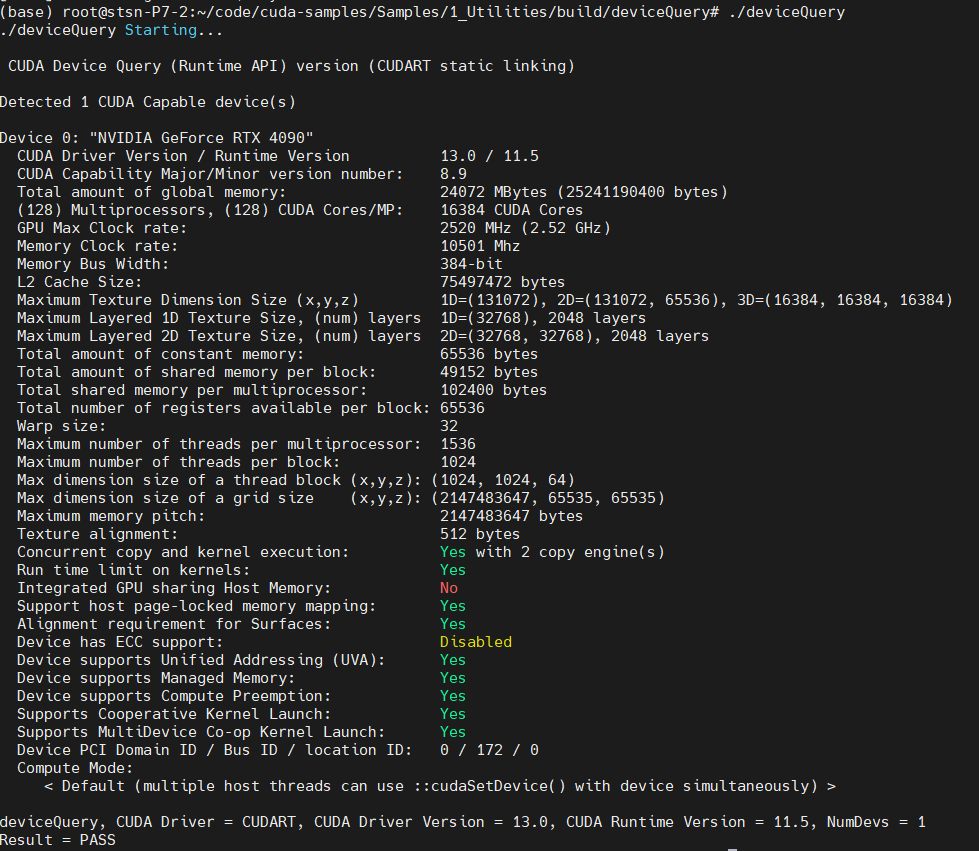
CUDA 工具包附带一个名为 deviceQuery 的便捷示例二进制文件。此工具会打印系统中每个可见 GPU 的完整报告。
在大多数 Linux 设置中,我们可以在以下位置找到 deviceQuery:/usr/local/cuda/samples/1_Utilities/deviceQuery/deviceQuery
如果没有找到,我们可以按如下方式构建 CUDA 示例目录:
cd /usr/local/cuda/samples/1_Utilities/deviceQuery sudo make ./deviceQuery
实在不行还可以使用源码编译:
# git clone https://github.com/NVIDIA/cuda-samples # cd cuda-samples/Samples/1_Utilities/build/deviceQuery # make # ./deviceQuery
输出会显示一长串属性,其中对我们最有用的几行是:
● 设备名称
● 全局内存总量
● 多处理器数量
● 每个 SM 的 CUDA 核心数
● 每个块的最大线程数
● 每个块的共享内存
● 计算能力
2.2.2 python验证设备属性
我们经常希望直接在 Python 中访问这些设置,尤其是在我们的代码需要适应不同的硬件时。使用 CuPy,我们可以以编程方式检查所需的一切。
现在,我们将打印出最重要的属性:
In [1]: import cupy as cp
In [2]: device = cp.cuda.Device(0)
In [3]: attributes = device.attributes
In [4]: attributes
Out[4]:
{'AsyncEngineCount': 2,
'CanFlushRemoteWrites': 0,
'CanMapHostMemory': 1,
'CanUseHostPointerForRegisteredMem': 1,
'ClockRate': 2520000,
'ComputeMode': 0,
'ComputePreemptionSupported': 1,
'ConcurrentKernels': 1,
'ConcurrentManagedAccess': 1,
'CooperativeLaunch': 1,
'CooperativeMultiDeviceLaunch': 1,
'DirectManagedMemAccessFromHost': 0,
'EccEnabled': 0,
'GPUDirectRDMAFlushWritesOptions': 1,
'GPUDirectRDMASupported': 0,
'GPUDirectRDMAWritesOrdering': 0,
'GlobalL1CacheSupported': 1,
'GlobalMemoryBusWidth': 384,
'GpuOverlap': 1,
'HostNativeAtomicSupported': 0,
'HostRegisterReadOnlySupported': 0,
'HostRegisterSupported': 1,
'Integrated': 0,
'IsMultiGpuBoard': 0,
'KernelExecTimeout': 1,
'L2CacheSize': 75497472,
'LocalL1CacheSupported': 1,
'ManagedMemory': 1,
'MaxBlockDimX': 1024,
'MaxBlockDimY': 1024,
'MaxBlockDimZ': 64,
'MaxBlocksPerMultiprocessor': 24,
'MaxGridDimX': 2147483647,
'MaxGridDimY': 65535,
'MaxGridDimZ': 65535,
'MaxPitch': 2147483647,
'MaxRegistersPerBlock': 65536,
'MaxRegistersPerMultiprocessor': 65536,
'MaxSharedMemoryPerBlock': 49152,
'MaxSharedMemoryPerBlockOptin': 101376,
'MaxSharedMemoryPerMultiprocessor': 102400,
'MaxSurface1DLayeredLayers': 2048,
'MaxSurface1DLayeredWidth': 32768,
'MaxSurface1DWidth': 32768,
'MaxSurface2DHeight': 65536,
'MaxSurface2DLayeredHeight': 32768,
'MaxSurface2DLayeredLayers': 2048,
'MaxSurface2DLayeredWidth': 32768,
'MaxSurface2DWidth': 131072,
'MaxSurface3DDepth': 16384,
'MaxSurface3DHeight': 16384,
'MaxSurface3DWidth': 16384,
'MaxSurfaceCubemapLayeredLayers': 2046,
'MaxSurfaceCubemapLayeredWidth': 32768,
'MaxSurfaceCubemapWidth': 32768,
'MaxTexture1DLayeredLayers': 2048,
'MaxTexture1DLayeredWidth': 32768,
'MaxTexture1DLinearWidth': 268435456,
'MaxTexture1DMipmappedWidth': 32768,
'MaxTexture1DWidth': 131072,
'MaxTexture2DGatherHeight': 32768,
'MaxTexture2DGatherWidth': 32768,
'MaxTexture2DHeight': 65536,
'MaxTexture2DLayeredHeight': 32768,
'MaxTexture2DLayeredLayers': 2048,
'MaxTexture2DLayeredWidth': 32768,
'MaxTexture2DLinearHeight': 65000,
'MaxTexture2DLinearPitch': 2097120,
'MaxTexture2DLinearWidth': 131072,
'MaxTexture2DMipmappedHeight': 32768,
'MaxTexture2DMipmappedWidth': 32768,
'MaxTexture2DWidth': 131072,
'MaxTexture3DDepth': 16384,
'MaxTexture3DDepthAlt': 32768,
'MaxTexture3DHeight': 16384,
'MaxTexture3DHeightAlt': 8192,
'MaxTexture3DWidth': 16384,
'MaxTexture3DWidthAlt': 8192,
'MaxTextureCubemapLayeredLayers': 2046,
'MaxTextureCubemapLayeredWidth': 32768,
'MaxTextureCubemapWidth': 32768,
'MaxThreadsPerBlock': 1024,
'MaxThreadsPerMultiProcessor': 1536,
'MaxTimelineSemaphoreInteropSupported': 1,
'MemoryClockRate': 10501000,
'MemoryPoolSupportedHandleTypes': 9,
'MemoryPoolsSupported': 1,
'MultiGpuBoardGroupID': 0,
'MultiProcessorCount': 128,
'PageableMemoryAccess': 1,
'PageableMemoryAccessUsesHostPageTables': 0,
'PciBusId': 172,
'PciDeviceId': 0,
'PciDomainId': 0,
'Reserved92': 0,
'Reserved93': 0,
'Reserved94': 0,
'ReservedSharedMemoryPerBlock': 1024,
'SingleToDoublePrecisionPerfRatio': 64,
'SparseCudaArraySupported': 1,
'StreamPrioritiesSupported': 1,
'SurfaceAlignment': 512,
'TccDriver': 0,
'TextureAlignment': 512,
'TexturePitchAlignment': 32,
'TotalConstantMemory': 65536,
'UnifiedAddressing': 1,
'WarpSize': 32}
In [5]: properties = cp.cuda.runtime.getDeviceProperties(0)
In [6]: properties
Out[6]:
{'name': b'NVIDIA GeForce RTX 4090',
'totalGlobalMem': 25241190400,
'sharedMemPerBlock': 49152,
'regsPerBlock': 65536,
'warpSize': 32,
'maxThreadsPerBlock': 1024,
'maxThreadsDim': (1024, 1024, 64),
'maxGridSize': (2147483647, 65535, 65535),
'clockRate': 2520000,
'totalConstMem': 65536,
'major': 8,
'minor': 9,
'textureAlignment': 512,
'texturePitchAlignment': 32,
'multiProcessorCount': 128,
'kernelExecTimeoutEnabled': 1,
'integrated': 0,
'canMapHostMemory': 1,
'computeMode': 0,
'maxTexture1D': 131072,
'maxTexture2D': (131072, 65536),
'maxTexture3D': (16384, 16384, 16384),
'concurrentKernels': 1,
'ECCEnabled': 0,
'pciBusID': 172,
'pciDeviceID': 0,
'pciDomainID': 0,
'tccDriver': 0,
'memoryClockRate': 10501000,
'memoryBusWidth': 384,
'l2CacheSize': 75497472,
'maxThreadsPerMultiProcessor': 1536,
'isMultiGpuBoard': 0,
'cooperativeLaunch': 1,
'cooperativeMultiDeviceLaunch': 1,
'deviceOverlap': 1,
'maxTexture1DMipmap': 32768,
'maxTexture1DLinear': 268435456,
'maxTexture1DLayered': (32768, 2048),
'maxTexture2DMipmap': (32768, 32768),
'maxTexture2DLinear': (131072, 65000, 2097120),
'maxTexture2DLayered': (32768, 32768, 2048),
'maxTexture2DGather': (32768, 32768),
'maxTexture3DAlt': (8192, 8192, 32768),
'maxTextureCubemap': 32768,
'maxTextureCubemapLayered': (32768, 2046),
'maxSurface1D': 32768,
'maxSurface1DLayered': (32768, 2048),
'maxSurface2D': (131072, 65536),
'maxSurface2DLayered': (32768, 32768, 2048),
'maxSurface3D': (16384, 16384, 16384),
'maxSurfaceCubemap': 32768,
'maxSurfaceCubemapLayered': (32768, 2046),
'surfaceAlignment': 512,
'asyncEngineCount': 2,
'unifiedAddressing': 1,
'streamPrioritiesSupported': 1,
'globalL1CacheSupported': 1,
'localL1CacheSupported': 1,
'sharedMemPerMultiprocessor': 102400,
'regsPerMultiprocessor': 65536,
'managedMemory': 1,
'multiGpuBoardGroupID': 0,
'hostNativeAtomicSupported': 0,
'singleToDoublePrecisionPerfRatio': 64,
'pageableMemoryAccess': 1,
'concurrentManagedAccess': 1,
'computePreemptionSupported': 1,
'canUseHostPointerForRegisteredMem': 1,
'sharedMemPerBlockOptin': 101376,
'pageableMemoryAccessUsesHostPageTables': 0,
'directManagedMemAccessFromHost': 0,
'uuid': b'\xea\xce)\xa0\xbe\xf8\x9d\xfe\x06w\x96\xdb\x89\x84,\xc4',
'luid': b'',
'luidDeviceNodeMask': 0,
'persistingL2CacheMaxSize': 51904512,
'maxBlocksPerMultiProcessor': 24,
'accessPolicyMaxWindowSize': 134213632,
'reservedSharedMemPerBlock': 1024}
In [7]: properties['name']
Out[7]: b'NVIDIA GeForce RTX 4090'
In [8]: properties['major']
Out[8]: 8
In [9]: properties['minor']
Out[9]: 9
In [10]: print("Total Global Memory (MB):", device.mem_info[1] // (1024 * 1024))
Total Global Memory (MB): 24071
In [11]: print("Multiprocessors:", attributes['MultiProcessorCount'])
...: print("Max Threads per Block:", attributes['MaxThreadsPerBlock'])
...: print("Shared Memory per Block (KB):", attributes['MaxSharedMemoryPerBlock'] // 1024)
Multiprocessors: 128
Max Threads per Block: 1024
Shared Memory per Block (KB): 48
我们可以看到所有会影响代码的属性:线程块可以设置多大、可以分配多少内存以及支持哪些功能。
2.2.3 验证计算能力
CUDA 计算能力(Compute Capability) 是 NVIDIA GPU 的一个版本号,它定义了 GPU 的硬件特性和功能集。简单来说,它告诉我们一张 NVIDIA 显卡在执行 CUDA 应用程序时,支持哪些功能,以及它有哪些硬件上的限制(比如寄存器数量、共享内存大小等)。
这个版本号通常由两个数字表示,例如 8.6 或 7.5,其中第一个数字是主版本号(major),第二个数字是次版本号(minor)。
主版本号(Major Version):表示 GPU 架构的代号。例如,8.x 代表 Ampere 架构,7.x 代表 Volta 架构,6.x 代表 Pascal 架构。主版本号的升级通常意味着架构上的重大变化和新功能的引入。
次版本号(Minor Version):表示在同一代 GPU 架构内的功能改进或修订。例如,8.0 和 8.6 都属于 Ampere 架构,但 8.6 可能在某些方面(如性能、功能)有所优化。
不同的计算能力版本支持不同的 CUDA 功能。例如,某些高级功能(如 Tensor Core、异步操作、增强的指令集等)可能只在较高的计算能力版本上才可用。如果你想在程序中使用这些新功能,你的 GPU 必须支持相应的计算能力。
nvcc 编译器在编译 CUDA 代码时,会根据你指定的计算能力来生成优化的二进制代码。指定正确的计算能力可以帮助编译器更好地利用目标 GPU 的硬件特性,从而获得更好的性能。
计算能力决定了 GPU 的硬件参数,例如:
- 每个多处理器(SM)的线程块(Thread Block)数量。
- 每个线程块的最大线程数。
- 每个线程块的共享内存(Shared Memory)大小。
- 每个线程的寄存器(Register)数量。
这些参数直接影响到 CUDA 内核的设计和优化。开发者需要根据目标 GPU 的计算能力来调整网格(Grid)和线程块(Block)的维度,以及共享内存的使用,以避免资源耗尽。计算能力的每次提升都会解锁新的指令、更大的共享内存以及新的加速功能。
大多数现代 CUDA 库都要求计算能力达到 6.0 或更高版本。如果我们的 GPU 报告计算能力达到 7.5、8.6 或类似水平,则几乎可以支持所有当前的 CUDA 库,包括最新版本的 CuPy、PyCUDA 和深度学习框架。如果我们的设备报告计算能力非常低(例如 3.x 或更低版本),则某些功能可能无法使用。在这种情况下,我们会限制使用兼容的库,或者考虑升级硬件。
我们还可以在 PyCUDA 中查询设备属性:
>>> import pycuda.driver as drv
... import pycuda.autoinit
... device = drv.Device(0)
... print("Device Name:", device.name())
... print("Compute Capability:", f"{device.compute_capability()[0]}.{device.compute_capability()[1]}")
... print("Total Global Memory (MB):", device.total_memory() // (1024 * 1024))
... for key, value in device.get_attributes().items():
... print(f"{key}: {value}")
...
Device Name: NVIDIA GeForce RTX 4090
Compute Capability: 8.9
Total Global Memory (MB): 24071
ASYNC_ENGINE_COUNT: 2
CAN_MAP_HOST_MEMORY: 1
CAN_USE_HOST_POINTER_FOR_REGISTERED_MEM: 1
CLOCK_RATE: 2520000
COMPUTE_CAPABILITY_MAJOR: 8
COMPUTE_CAPABILITY_MINOR: 9
COMPUTE_MODE: DEFAULT
COMPUTE_PREEMPTION_SUPPORTED: 1
CONCURRENT_KERNELS: 1
CONCURRENT_MANAGED_ACCESS: 1
DIRECT_MANAGED_MEM_ACCESS_FROM_HOST: 0
ECC_ENABLED: 0
GENERIC_COMPRESSION_SUPPORTED: 1
GLOBAL_L1_CACHE_SUPPORTED: 1
GLOBAL_MEMORY_BUS_WIDTH: 384
GPU_OVERLAP: 1
HANDLE_TYPE_POSIX_FILE_DESCRIPTOR_SUPPORTED: 1
HANDLE_TYPE_WIN32_HANDLE_SUPPORTED: 0
HANDLE_TYPE_WIN32_KMT_HANDLE_SUPPORTED: 0
HOST_NATIVE_ATOMIC_SUPPORTED: 0
INTEGRATED: 0
KERNEL_EXEC_TIMEOUT: 1
L2_CACHE_SIZE: 75497472
LOCAL_L1_CACHE_SUPPORTED: 1
MANAGED_MEMORY: 1
MAXIMUM_SURFACE1D_LAYERED_LAYERS: 2048
MAXIMUM_SURFACE1D_LAYERED_WIDTH: 32768
MAXIMUM_SURFACE1D_WIDTH: 32768
MAXIMUM_SURFACE2D_HEIGHT: 65536
MAXIMUM_SURFACE2D_LAYERED_HEIGHT: 32768
MAXIMUM_SURFACE2D_LAYERED_LAYERS: 2048
MAXIMUM_SURFACE2D_LAYERED_WIDTH: 32768
MAXIMUM_SURFACE2D_WIDTH: 131072
MAXIMUM_SURFACE3D_DEPTH: 16384
MAXIMUM_SURFACE3D_HEIGHT: 16384
MAXIMUM_SURFACE3D_WIDTH: 16384
MAXIMUM_SURFACECUBEMAP_LAYERED_LAYERS: 2046
MAXIMUM_SURFACECUBEMAP_LAYERED_WIDTH: 32768
MAXIMUM_SURFACECUBEMAP_WIDTH: 32768
MAXIMUM_TEXTURE1D_LAYERED_LAYERS: 2048
MAXIMUM_TEXTURE1D_LAYERED_WIDTH: 32768
MAXIMUM_TEXTURE1D_LINEAR_WIDTH: 268435456
MAXIMUM_TEXTURE1D_MIPMAPPED_WIDTH: 32768
MAXIMUM_TEXTURE1D_WIDTH: 131072
MAXIMUM_TEXTURE2D_ARRAY_HEIGHT: 32768
MAXIMUM_TEXTURE2D_ARRAY_NUMSLICES: 2048
MAXIMUM_TEXTURE2D_ARRAY_WIDTH: 32768
MAXIMUM_TEXTURE2D_GATHER_HEIGHT: 32768
MAXIMUM_TEXTURE2D_GATHER_WIDTH: 32768
MAXIMUM_TEXTURE2D_HEIGHT: 65536
MAXIMUM_TEXTURE2D_LINEAR_HEIGHT: 65000
MAXIMUM_TEXTURE2D_LINEAR_PITCH: 2097120
MAXIMUM_TEXTURE2D_LINEAR_WIDTH: 131072
MAXIMUM_TEXTURE2D_MIPMAPPED_HEIGHT: 32768
MAXIMUM_TEXTURE2D_MIPMAPPED_WIDTH: 32768
MAXIMUM_TEXTURE2D_WIDTH: 131072
MAXIMUM_TEXTURE3D_DEPTH: 16384
MAXIMUM_TEXTURE3D_DEPTH_ALTERNATE: 32768
MAXIMUM_TEXTURE3D_HEIGHT: 16384
MAXIMUM_TEXTURE3D_HEIGHT_ALTERNATE: 8192
MAXIMUM_TEXTURE3D_WIDTH: 16384
MAXIMUM_TEXTURE3D_WIDTH_ALTERNATE: 8192
MAXIMUM_TEXTURECUBEMAP_LAYERED_LAYERS: 2046
MAXIMUM_TEXTURECUBEMAP_LAYERED_WIDTH: 32768
MAXIMUM_TEXTURECUBEMAP_WIDTH: 32768
MAX_BLOCKS_PER_MULTIPROCESSOR: 24
MAX_BLOCK_DIM_X: 1024
MAX_BLOCK_DIM_Y: 1024
MAX_BLOCK_DIM_Z: 64
MAX_GRID_DIM_X: 2147483647
MAX_GRID_DIM_Y: 65535
MAX_GRID_DIM_Z: 65535
MAX_PERSISTING_L2_CACHE_SIZE: 51904512
MAX_PITCH: 2147483647
MAX_REGISTERS_PER_BLOCK: 65536
MAX_REGISTERS_PER_MULTIPROCESSOR: 65536
MAX_SHARED_MEMORY_PER_BLOCK: 49152
MAX_SHARED_MEMORY_PER_BLOCK_OPTIN: 101376
MAX_SHARED_MEMORY_PER_MULTIPROCESSOR: 102400
MAX_THREADS_PER_BLOCK: 1024
MAX_THREADS_PER_MULTIPROCESSOR: 1536
MEMORY_CLOCK_RATE: 10501000
MEMORY_POOLS_SUPPORTED: 1
MULTIPROCESSOR_COUNT: 128
MULTI_GPU_BOARD: 0
MULTI_GPU_BOARD_GROUP_ID: 0
PAGEABLE_MEMORY_ACCESS: 1
PAGEABLE_MEMORY_ACCESS_USES_HOST_PAGE_TABLES: 0
PCI_BUS_ID: 172
PCI_DEVICE_ID: 0
PCI_DOMAIN_ID: 0
READ_ONLY_HOST_REGISTER_SUPPORTED: 0
RESERVED_SHARED_MEMORY_PER_BLOCK: 1024
SINGLE_TO_DOUBLE_PRECISION_PERF_RATIO: 64
STREAM_PRIORITIES_SUPPORTED: 1
SURFACE_ALIGNMENT: 512
TCC_DRIVER: 0
TEXTURE_ALIGNMENT: 512
TEXTURE_PITCH_ALIGNMENT: 32
TOTAL_CONSTANT_MEMORY: 65536
UNIFIED_ADDRESSING: 1
WARP_SIZE: 32
这会显示所有可用属性,以便我们可以根据需要调整内核配置。
每当我们更换机器、GPU 或驱动程序时,运行新的设备查询始终是验证兼容性的第一步。通过这种做法,我们的 CUDA 编程将保持可靠、灵活,并与现有硬件完美匹配。
参考资料
- 软件测试精品书籍文档下载持续更新 https://github.com/china-testing/python-testing-examples 请点赞,谢谢!
- 本文涉及的python测试开发库 谢谢点赞! https://github.com/china-testing/python_cn_resouce
- python精品书籍下载 https://github.com/china-testing/python_cn_resouce/blob/main/python_good_books.md
- Linux精品书籍下载 https://www.cnblogs.com/testing-/p/17438558.html
- python八字排盘 https://github.com/china-testing/bazi
- 联系方式:钉ding或V信: pythontesting
2.3 在PyCUDA 中实现内核

我们已经使用 PyCUDA 编写了一个基本的向量加法内核,但现在我们想进一步了解 PyCUDA 如何让我们在 Python 脚本中插入和运行自定义 CUDA C 代码。我们希望熟悉整个主机-设备工作流程:分配内存、移动数据、编写更灵活的内核、动态编译、启动内核,然后检索和验证结果。
这个示例比我们之前的示例更好。在这里,我们将讨论参数化、尝试新的操作,并阐明为什么 PyCUDA 是 Python 和 CUDA 生态系统之间如此坚实的桥梁。
2.3.1 准备主机数据
我们将首先设置两个输入数组和一个用于输出的占位符。我们将开始在主机上使用 NumPy 来简化设置。
>>> import numpy as np
... N = 8
... a_host = np.arange(N, dtype=np.float32)
... b_host = np.arange(N, 0, -1).astype(np.float32)
... print("Input Array A:", a_host)
... print("Input Array B:", b_host)
...
Input Array A: [0. 1. 2. 3. 4. 5. 6. 7.]
Input Array B: [8. 7. 6. 5. 4. 3. 2. 1.]
为了清晰起见,我们选择较小的数组,但同样的工作流程也适用于更大的数据集。
2.3.2 配设备内存
使用 PyCUDA,我们将这些数组传输到 GPU。我们还为结果分配了空间。
>>> import pycuda.autoinit ... import pycuda.driver as drv ... import pycuda.gpuarray as gpuarray ... a_device = gpuarray.to_gpu(a_host) ... b_device = gpuarray.to_gpu(b_host) ... c_device = gpuarray.empty_like(a_device) ...
此时,a_device 和 b_device 位于 GPU 上,c_device 为结果保留空间。
2.3.3 编写自定义 CUDA C 内核
这正是 PyCUDA 的优势所在。我们可以将 CUDA C 代码以字符串形式嵌入,并在运行时进行编译。这样,我们的内核将逐个元素地添加两个数组,但我们也可以轻松地更改操作。
以下是 CUDA C 脚本:
... kernel_code = """
... __global__ void add_arrays(float *a, float *b, float *c, int n)
... {
... int idx = threadIdx.x + blockDim.x * blockIdx.x;
... if (idx < n)
... {
... c[idx] = a[idx] + b[idx]; // Try changing this operation!
... }
... }
... """
... mod = SourceModule(kernel_code)
... add_arrays = mod.get_function("add_arrays")
...
>>> threads_per_block = 4
... blocks_per_grid = (N + threads_per_block - 1) // threads_per_block
...
CUDA 要求我们指定每个块中要运行的线程数以及要启动的块数。为简单起见,我们可以使用 4 作为块大小,并计算覆盖所有元素的网格大小。
2.3.4 启动内核并验证结果
然后,我们使用 PyCUDA 的函数接口调用内核。所有指针和参数都按照它们在内核中出现的顺序传递。
>>> add_arrays( ... a_device, b_device, c_device, np.int32(N), ... block=(threads_per_block, 1, 1), grid=(blocks_per_grid, 1) ... )
内核在 GPU 上异步运行,并行处理所有元素。
计算完成后,我们将结果从 GPU 复制回主机,并与 CPU 计算结果进行验证。
>>> c_host = c_device.get()
... print("Result Array C:", c_host)
... # Validate correctness
... expected = a_host + b_host
... if np.allclose(c_host, expected):
... print("Result matches CPU computation.")
... else:
... print("Mismatch found!")
...
Result Array C: [8. 8. 8. 8. 8. 8. 8. 8.]
Result matches CPU computation.
快速总结一下我们的工作:
● 我们首先分配所需大小的设备数组——无需担心主机内存。
● 使用 to_gpu() 和 .get() 时,PyCUDA 会自动处理主机到设备和设备到主机的移动。
● 我们的 CUDA C 代码在脚本运行时嵌入并编译,使我们能够快速迭代。
● 然后,我们控制块和网格的大小,从而获得应对任何规模或复杂度问题的灵活性。
● 最后,通过对照 CPU 版本检查结果,我们可以及早发现错误,并增强对 GPU 编程技能的信心。
这为我们提供了一种可靠、灵活的模式,可以使用 PyCUDA 在 Python 项目中嵌入和验证 CUDA C 内核。这项技能非常有用,对于我们接下来处理更具挑战性和创造性的 GPU 编程任务至关重要。
2.4 小结
总而言之,我们成功搭建了一个可靠且专业级的 GPU 编程环境,确保工作流程的每一步都保持稳健、可重复且能够满足我们的需求。我们首先加深了对 CUDA 驱动程序、CUDA 工具包和 NVIDIA 硬件之间关系的理解,确保所有组件都协调一致以实现最佳性能。我们学习了如何安装和验证工具包和驱动程序、更新环境变量,以及如何使用内置工具(例如 nvidia-smi 和 nvcc)来验证系统是否已准备好应对繁重的 GPU 工作负载。
通过运行 CUDA 设备查询并检查 GPU 属性(无论是在命令行还是在 Python 中),我们深入了解了设备的计算能力、可用内存和架构限制。这使我们能够调整代码和库选择,使其与硬件完美匹配。通过亲手使用 PyCUDA,我们练习了如何在 Python 中嵌入、编译和执行 CUDA C 内核,从而强化了主机-设备工作流程的各个方面。