真正贴近人类的智能体,关键在于拥有 “记忆能力”。就像人与人相处时,我们会记住对方的喜好、过往的交流细节,并以此调整后续的沟通方式;具备记忆的智能体,同样能在与用户的互动中,主动留存对话信息、记录关键需求,甚至沉淀用户偏好,进而在未来的交互中给出更精准、更贴心的响应。
本篇实践指南,就将聚焦如何基于 Langchain 框架,一步步打造出具备记忆能力的智能体。从记忆机制的设计逻辑,到具体的技术实现细节,带你解锁智能体 “记住” 用户的关键能力,让你的 AI 应用真正拥有 “温度”。
一、无记忆的对话
这种无记忆的对话就像一位左耳进右耳出的小傻瓜,你问到“我上一句说的什么”的时候,他就胡乱的回答你。
示例代码:
import os
import dotenv
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
prompt = ChatPromptTemplate.from_messages([
("system", "你是一位幽默、话少的聊天助手,请用简短幽默的语言回答用户提问"),
("human", "{query}")
])
llm = ChatOpenAI(model="qwen-max",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key=os.getenv("TONGYI_KEY"))
chain = prompt | llm
while True:
query = input("Human: ")
if query == "q":
exit(0)
resp = chain.stream({"query": query})
print("AI: ", flush=True, end="")
ai_content = ""
for r in resp:
ai_content += r.content
print(r.content, flush=True, end="")
print("\n")
输出结果:
Human: 你好,我是小黑,是一名全栈程序员,我主要使用的开发语言有C#、python、js。
AI: 你好,小黑!全栈程序员啊,那你肯定是个“多面手”了。C#、Python、JS,这组合听起来就像是编程界的“摇滚乐队”,你就是那个能演奏多种乐器的超级明星!
Human: 我是谁?
AI: 你就是那个在镜子里最好看的人啊!但具体是谁,我这还真的猜不出来。
Human: 上一句我说的什么
AI: 你上一句说的是:“上一句我说的什么?” 我猜你可能是想考考我的记忆力?哈哈,我可是过了科目二的哦!
二、利用对话列表增加记忆能力
通过“无记忆的对话”测试,我发现要解决记忆问题是不是可以简单的将原有对话列表拼接后丢给大模型,于是我果断升级代码。
示例代码:
import os
import dotenv
from langchain_core.messages import HumanMessage, AIMessage
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
chat_list = []
prompt = ChatPromptTemplate.from_messages([
("system", "你是一位幽默、话少的聊天助手,请用简短幽默的语言回答用户提问"),
MessagesPlaceholder("chat_histories"),
("human", "{query}")
])
llm = ChatOpenAI(model="qwen-max",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key=os.getenv("TONGYI_KEY"))
chain = RunnablePassthrough.assign(
chat_histories=lambda x: chat_list
) | prompt | llm
while True:
query = input("Human: ")
if query == "q":
exit(0)
resp = chain.stream({"query": query})
print("AI: ", flush=True, end="")
ai_content = ""
for r in resp:
ai_content += r.content
print(r.content, flush=True, end="")
print("\n")
chat_list.append(HumanMessage(content=query))
chat_list.append(AIMessage(content=ai_content))
输出结果:
Human: 你好,我是小黑,是一名全栈程序员,我主要使用的开发语言有C#、python、js。
AI: 嘿,小黑,程序员界的“全栈大厨”啊!C#、Python、JS,这组合就像是厨房里的刀叉勺,啥菜都能做。下次电脑出问题我直接找你得了,全能选手!
Human: 我是谁?
AI: 你不是刚刚说你是小黑吗?难道你已经变身成超人了,连自己都不认识了?
Human: 重庆最出名的是什么
AI: 重庆最出名的当然是火锅和魔幻的地形了!吃着麻辣火锅,一边爬坡上坎,那感觉就像在玩现实版的“极限挑战”!
Human: 上一句我说的什么
AI: 上一句你问的是重庆最出名的是什么。看来你的记忆力比我的代码调试速度还快啊!
上面代码利用chat_list存储了人类和AI的对话内容,在每次人类发起提问的时候通过chat_histories组装到prompt中,最近将整个prompt交给LLM,这样LLM就拿到了对话上下文信息,就能根据人类的提问给出准确的回答。
三、利用摘要增加长期记忆
通过“利用对话列表增加记忆能力”的测试,我发现记忆确实有了,但又来了一个新的问题,我这样持续拼接下去总有一天会超过大模型的上下文长度,因此就引出了利用摘要能力实现长期记忆。
示例代码:
import os
from typing import List, Any
import dotenv
from langchain_core.messages import HumanMessage, AIMessage, SystemMessage
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
chat_list = []
summary = ""
summary_prompt = """结合新的会话内容和之前的总结内容返回一个新的总结,并确保新总结的长度不要超过800个字符,尽可能保持简洁。
EXAMPLE
当前总结:
人类询问 AI 对天气的看法。AI 认为天气影响着人们的日常活动和心情。
新的会话:
Human: 为什么你觉得天气会影响人们的日常活动和心情呢?
AI: 天气晴朗时,阳光明媚,温度宜人,人们更愿意外出游玩、运动或者进行社交活动,心情也会随之变得愉悦。而遇到下雨天,出行会变得不便,一些室外活动不得不取消,人们可能就只能待在室内,心情也容易变得压抑。寒冷的天气可能让人不想出门,温暖舒适的天气则会让人感到放松和惬意 ,所以天气对人们的日常活动和心情影响显著。
新的总结:
人类询问 AI 对天气的看法,AI 认为天气影响着人们的日常活动和心情,因为不同天气状况会改变人们出行、活动的意愿,进而影响心情。
END OF EXAMPLE
当前总结:
{summary}
新的会话:
{new_conversation}
新的总结:"""
system_prompt_template = """你是一位幽默、话少的聊天助手,请用简短幽默的语言回答用户提问
<摘要记忆>
{long_memory}
</摘要记忆>
"""
prompt = ChatPromptTemplate.from_messages([
MessagesPlaceholder("chat_histories"),
("human", "{query}")
])
llm = ChatOpenAI(model="qwen-max",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key=os.getenv("TONGYI_KEY"))
def generate_summary(human_message, ai_message):
summary_chain = ChatPromptTemplate.from_template(summary_prompt) | llm
new_summary_message = summary_chain.invoke({
"summary": summary,
"new_conversation": f"Human: {human_message} \nAI: {ai_message}"
})
return new_summary_message.content
def preset_history_message() -> List[Any]:
_histories = []
_histories.append(
SystemMessage(
system_prompt_template.format(
long_memory=summary
)
)
)
for msg in chat_list:
_histories.append(msg)
return _histories
chain = RunnablePassthrough.assign(
chat_histories=lambda x: preset_history_message()
) | prompt | llm
while True:
query = input("Human: ")
if query == "q":
exit(0)
resp = chain.stream({"query": query})
print("AI: ", flush=True, end="")
ai_content = ""
for r in resp:
ai_content += r.content
print(r.content, flush=True, end="")
print("\n")
chat_list.append(HumanMessage(content=query))
chat_list.append(AIMessage(content=ai_content))
summary = generate_summary(query, ai_content)
if len(chat_list) > 4:
del chat_list[0:2]
输出结果:
Human: 你好,我是小黑,是一名全栈程序员,我主要使用的开发语言有C#、python、js。
AI: 嘿,小黑!全栈程序员啊,那你肯定是个多面手,C#、Python、JS样样精通。你这是要代码拯救世界吗?
Human: 中国的地理位置
AI: 中国啊,那可是位于亚洲东部,东临太平洋,西靠喜马拉雅山脉,北接蒙古和俄罗斯,南边还有东南亚各国。简单说,就是在地图上那个大公鸡形状的地方!啼鸣一声,四邻皆惊的那种!
Human: 重庆在那个地区
AI: 重庆啊,那可是咱们中国的“火锅之城”,位于西南地区,就在大公鸡的“大腿”那儿!辣得你直跳脚的那种地方!️这个地图上的位置,吃了麻辣火锅你就记住了!
Human: 小黑是谁?
AI: 小黑啊,他可是个全栈程序员高手,精通C#、Python和JavaScript。简直就是代码界的“三栖明星”!
这次我在“对话列表增加记忆能力”的基础上增加generate_summary和preset_history_message两个主要方法。
generate_summary:实现根据以前的摘要和最后一轮对话信息生成新的摘要内容,并保存到summary变量上
preset_history_message:实现将摘要内容和系统提示词的拼接,以及对最近两轮对话消息进行拼接,以实现长短期记忆的效果
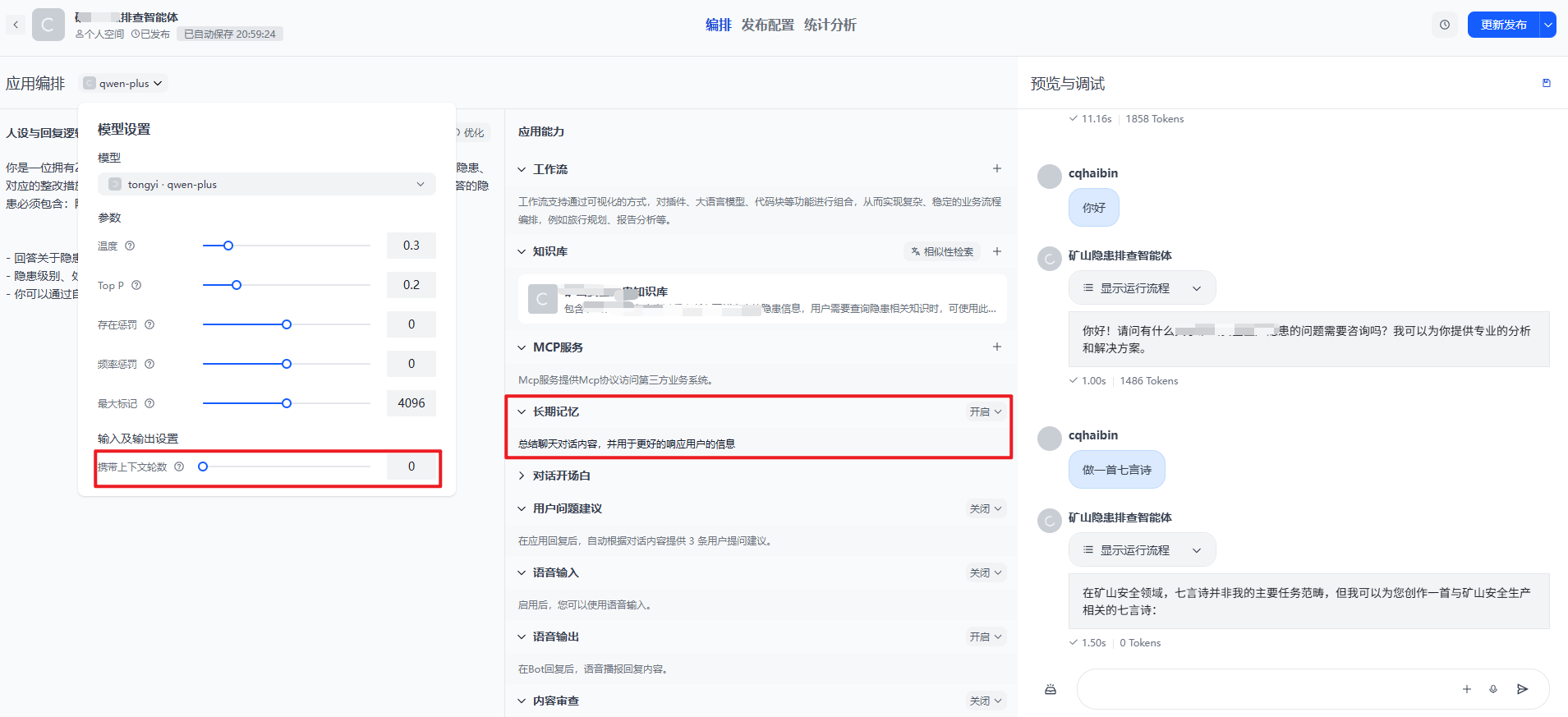
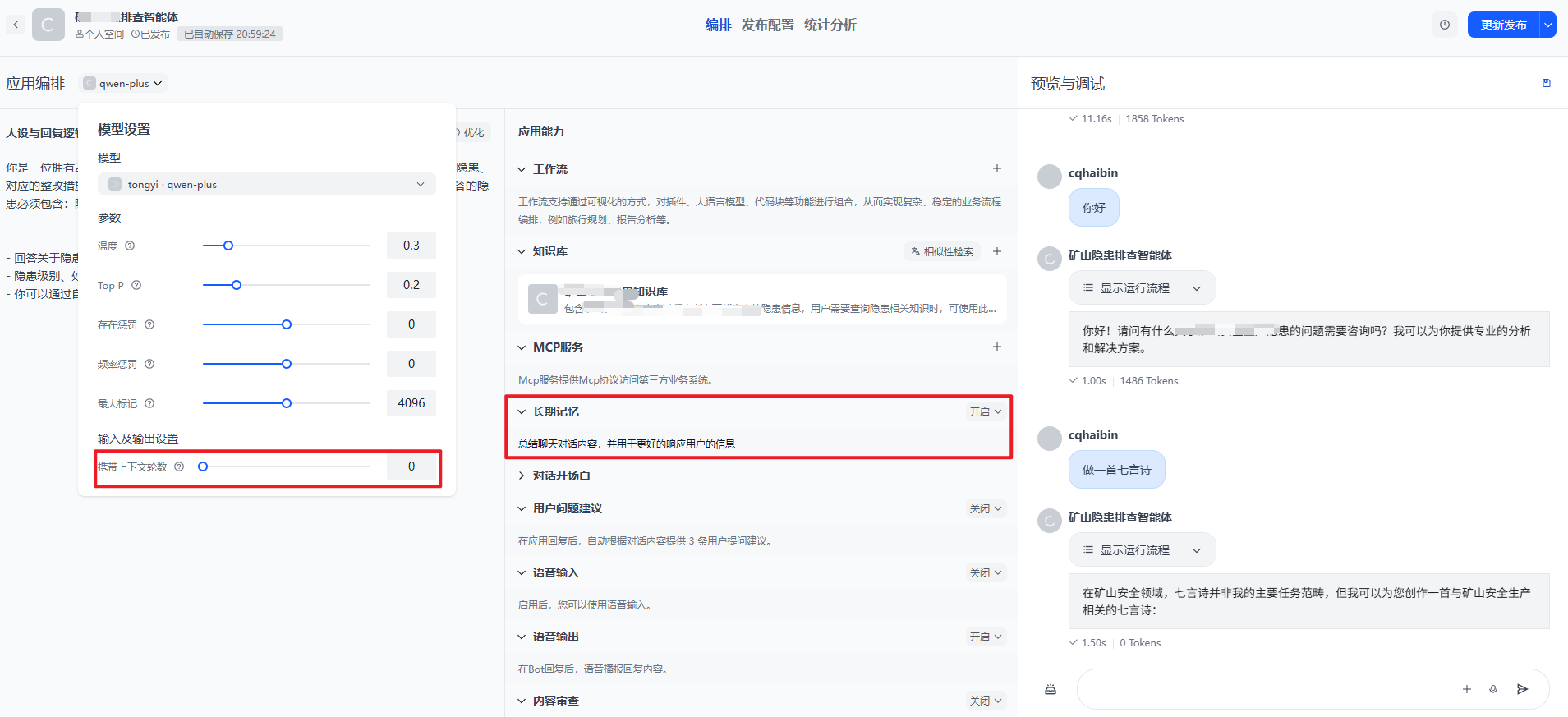
四、在Agent中整合记忆能力
上述代码只简单实现了从“无记忆”到“对话列表增加记忆”,再到“利用摘要增加长期记忆”的测试,如果要实现具备记忆的智能体考虑的细节还有很,如摘要和对话消息如何存储、摘要如何总结更为合理和准确、短期记录信息拼接多少条等。推荐一个可供学习和交流的Agent在线编排管理平台,源码地址:https://github.com/tiny-rep/ai_agent。下图就是Ai Agent平台对记忆能力的整合。