

介绍
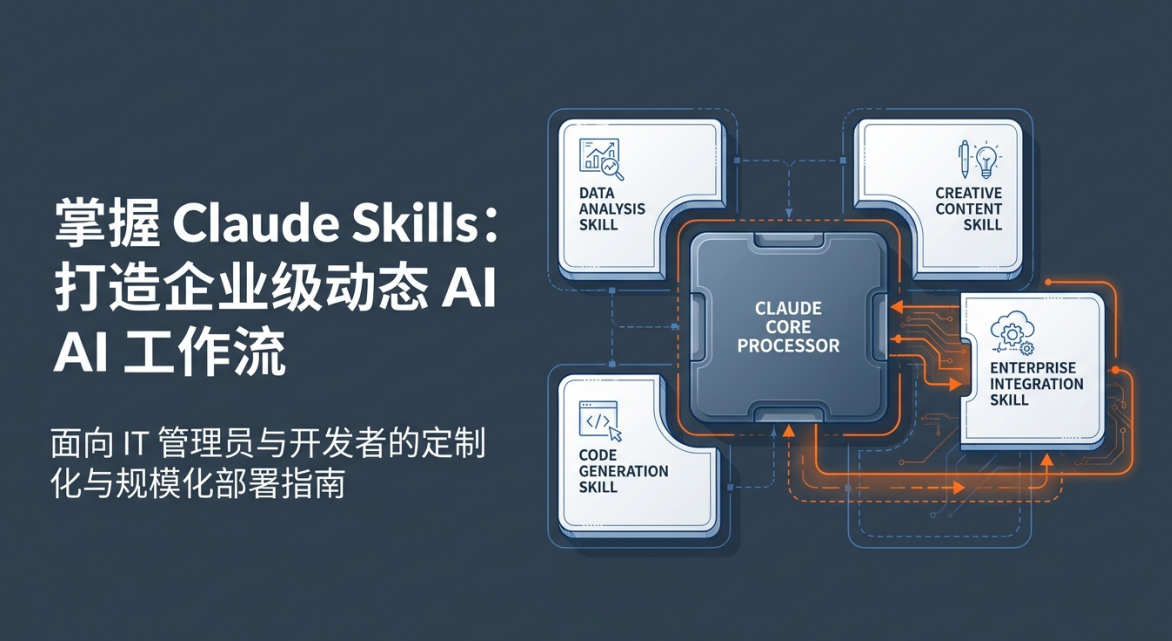
在 Claude 生态系统中,Skill(技能) 正从简单的指令集演进为一种包含指令、数据和可执行代码的复合型自动化单元。作为 AI 系统架构师,我们需要理解 Skill 不仅仅是插件,它是一种具备“自洽性”的任务执行包。通过将特定领域的工作流、机构知识与计算逻辑封装,Skill 显著提升了模型在处理复杂、重复性任务时的稳定性、速度与一致性。最核心的优势在于其复合性(Composability):多个 Skill 可以自动协同工作,构建出超越单一指令边界的智能体能力。
1. 核心定义:Agent Skills 架构范式
Skill 采用动态加载机制,使 Claude 能够根据任务需求按需调用专业化资源。这有效解决了大模型“上下文膨胀”的问题,确保模型在执行任务时只携带必要的上下文负载。
以下是 Skill 与 Claude 生态中其他功能的深度对比,展示了其在复杂任务中的核心优势:
|
比较维度 |
Skill (技能) |
Projects (项目) |
MCP (模型上下文协议) |
自定义指令 |
|
调用时机 |
动态语义触发:仅在任务匹配时加载。 |
静态预载:聊天开始即全量加载。 |
实时外联:访问外部工具或数据时触发。 |
全局生效:应用于所有对话。 |
|
知识加载方式 |
渐进式披露:元数据 -> 指令正文 -> 外部资源。 |
全量上下文:静态背景文档与代码库。 |
动态交互:通过协议获取外部服务数据。 |
偏好注入:宽泛的行为准则与偏好。 |
|
工具调用能力 |
原生代码执行:支持 Python/JS,具备逻辑运算力。 |
文本处理:主要基于文件交互。 |
连接器模式:对接第三方 API 与数据库。 |
逻辑生成:仅限于文本推理。 |
衔接语: Skill 的复合性特征不仅体现在功能集成上,更源于其严谨的底层定义——这一切都始于核心元数据文件 Skill.md。

2. Skill.md 规范:元数据工程与语义触发
在 Skill 的设计哲学中,“描述即接口”。模型在检索系统中识别并决定是否调用某个技能,完全依赖于元数据(Metadata)的精准定义。
元数据深度剖析
- name (名称):上限 64 字符。建议采用具象的动词短语。
- description (描述):上限 200 字符。这是核心语义索引,也是路由决策的单一事实来源。描述必须明确界定“何时调用”以及“能解决什么问题”。如果描述模糊,会导致模型在关键时刻决策失败(Invocation Failure)。
YAML 配置模板
每个 Skill.md 必须包含 YAML 前置元数据。特别注意,dependencies 的处理在不同模式下存在差异:
—
name: 企业品牌准则工具
description: 将 Acme Corp 品牌指南应用于文档和演示文稿,包括官方颜色、字体和徽标使用规范。当任务涉及设计审查或文档格式化时调用。
dependencies:
– python>=3.8
– pandas>=1.5.0
– numpy
—
正文构建指南
Markdown 正文是第二层指令。开发者应利用“少样本学习(Few-shot prompting)”,通过具体的 Examples 展示预期的输入与输出。这不仅能明确语义边界,还能大幅提升复杂逻辑下的任务成功率。
衔接语: 在定义好静态配置后,下一步需理解系统如何通过逻辑层级高效地检索并按需加载这些信息。

3. 渐进式披露机制 (Progressive Disclosure) 的运行逻辑
为了平衡上下文窗口溢出与计算成本,Skill 引入了渐进式披露机制。这种战略性说明确保了 Claude 的推理资源被精准投放。
层级模型构建
- Level 1 (元数据检索):Claude 扫描可用 Skill 的 name 和 description。
- Level 2 (详细指令):当语义命中时,加载 Skill.md 的 Markdown 正文及指令。
- Level 3 (外部资源与脚本):仅当 Level 2 无法满足任务需求时,Claude 才会按需加载同目录下的辅助文件(如 REFERENCE.md)或执行代码脚本。
资源引用策略
对于庞大的知识库,建议将其拆分为辅助资源文件。在 Skill.md 中进行显式引用(例如:“参考 REFERENCE.md 中的详细表格”),可引导模型在必要时才执行高成本的资源加载,维持对话的高响应速度。
衔接语: 这种按需加载机制,为集成高性能的可执行脚本提供了安全且高效的运行环境。

4. 脚本集成与依赖管理的高级实践
脚本集成使 Skill 从“文本生成”飞跃到“逻辑运算”与“文件处理”的新阶段,赋予了模型处理复杂数据分析和可视化工具的能力。
语言支持与运行环境
- 支持语言:主要支持 Python(标准库及 pandas, matplotlib 等)和 JavaScript/Node.js。
- 依赖管理(关键区别):
- 界面模式 (Claude.ai / Claude Code):支持运行时动态安装。模型会根据 dependencies 自动从 PyPI 或 npm 拉取包。
- API 模式:严禁运行时安装。所有第三方库必须预安装在执行容器中。开发者在设计 API Skill 时必须确保环境的一致性。
安全沙箱与 MCP 协同
- 严禁硬编码:禁止在脚本中写入 API Key 或凭据。
- 协同模式:Partner Skills(如 Figma, Notion)采用 “Skill + MCP” 架构。Skill 提供操作逻辑,而 MCP 连接器 负责安全的身份验证和外部数据通路。
衔接语: 完成逻辑开发后,必须通过严格的打包结构确保 Skill 能够被系统跨平台正确识别。

5. 目录拓扑与打包部署标准
统一的目录结构是实现企业级分发和跨平台兼容的前提。Skill 的文件系统必须遵循严格的嵌套规范。
目录树可视化
正确结构: ZIP 压缩包的根目录必须是 Skill 文件夹,而非文件散装。
my-Skill.zip
└── my-Skill/ <– 文件夹名必须匹配 Skill 名称
├── Skill.md <– 核心逻辑文件(必选)
├── REFERENCE.md <– 辅助资源(可选)
└── scripts/ <– 可执行脚本(可选)
验证清单 (Checklist)
- [ ] 先决条件:组织设置中的“代码执行 (Code Execution)”开关是否已开启?
- [ ] 结构检查:ZIP 压缩包内是否包含且仅包含一个根文件夹?
- [ ] 元数据:Skill.md 描述是否在 200 字符内且包含调用触发词?
- [ ] 路径一致性:脚本中的文件引用是否使用了相对于 Skill 根目录的路径?
衔接语: 规范的打包是部署的前提,而在企业环境中,还需配合精细的权限与共享策略。


6. 企业级治理:分发模型与 Agent Skills 标准
对于 Team 与 Enterprise 用户,Skill 是组织级知识沉淀的核心载体。管理员通过统一置备,可以确保全员采用标准化的工作流。
分发路径对比
|
特性 |
管理员统一置备 (Provisioned) |
成员 Peer-to-Peer 共享 |
全组织共享 (Directory) |
|
分发权限 |
仅限 Owner / Admin |
任何成员(若开关开启) |
任何成员(若开关开启) |
|
默认状态 |
默认启用,带视觉标识 |
默认禁用,需手动开启 |
需从目录手动安装 |
|
审核流程 |
所有者直接上传,无需审批 |
无强制审批,点对点分发 |
无审批环节,直接发布 |
|
审计能力 |
记录 role_assignment 事件 |
记录 share 事件 |
记录发布与安装事件 |
注意:审计日志仅记录事件(Who/When),不记录 Skill 的具体代码或正文内容。出于安全考虑,管理员应审慎开启“Org-wide Sharing”功能。
Agent Skills 开放标准
遵循 agentskills.io 规范不仅是为了当前的兼容性,更是为了避免供应商锁定。该标准提供了一个 Reference Python SDK,允许开发者在自建平台或其他 AI 工具中无缝迁移和运行相同的 Skill。
衔接语: 最终,所有架构设计的成败都需通过闭环的迭代测试来验证。


7. 开发者迭代指南:测试、监控与优化
Skill 开发是一个基于模型反馈进行微调的实验过程。成功的 Skill 应能显著提升任务的一致性、速度与准确性。
- 思维链 (CoT) 调试法:在测试时观察 Claude 的 “Thinking” 模块。确认模型是否在预期的语义点加载了 Skill,以及它是否正确理解了 Skill.md 中的指令层级。
- 最佳实践提炼:
- 聚焦单一流:不要构建“万能工具”,而应通过多个专注的 Skill 组合任务。
- 语义边界收窄:若发现误触发,应立即通过缩减 description 的范畴来优化。
- 示例驱动成功:在正文中使用具体的 Input/Output 示例定义“什么是成功执行”。
开发者能够构建出具有工业级鲁棒性的 AI 自动化单元,将 Claude 的通用智能转化为企业的核心生产力。

本质
一、Skill核心架构与落地内核:模块化知识注入底层逻辑
锚定AI智能自动化底层刚需,拆解Skill原生核心运行架构,适配全量级LLM场景落地,轻量化无额外适配成本,贴合全行业AI工程实操标准。
核心核心定义:Skill 绝非简单功能插件,本质是标准化封装的轻量化结构化知识包,全域兼容YAML规则配置+Markdown可视化双格式联动,精准贴合大模型原生适配逻辑,依托实时会话上下文无感注入,刚性约束、精准规范全链路LLM输出行为,杜绝模型发散答非所问、逻辑断层、实操落地失效等高频问题。

全域标准化配套固定目录(开箱即用,无需二次重构)
1. 核心主文档:专属SKILL.md全域适配主文件,统筹全流程规则、权限、输出口径基准;
2. 闭环执行脚本:轻量化可直接运行实操脚本,一键触发全自动化流程,适配本地/云端双部署;
3. 权威合规参考资料:行业合规基准、业务边界细则、风控合规兜底文件,规避业务违规风险;
4. 全品类配套资源:适配多场景素材库、格式模板、字段预设、权限配套包,降低上手门槛;
5. 标准落地示例:真实业务全链路复刻案例,对标实操、直接复用,零试错成本快速落地。

二、五大硬核设计范式:全覆盖适配全业务自动化场景
聚焦AI Agent全生命周期实操落地,精准匹配从单次轻量化操作、中期闭环任务到跨月度长线攻坚项目,全梯度适配,无场景盲区,适配企业批量投产、个人高效实操双线需求。
|
核心范式类型 |
精准落地典型场景 |
标杆实操代表案例 |
核心落地关键特征 |
|
线性流程范式 |
一键云端批量部署、环境快速装机配置、标准化工具闭环安装运维 |
vercel全链路极速自动化部署上线 |
全链路分步拆解标准步骤化指令,内嵌原生安全防护兜底默认值,全程无人值守自动推进,零人工干预卡点 |
|
智能决策树范式 |
多平台择优选型、业务链路分支研判、合规风险分级判定、资源配额智能调配 |
cloudflare全域跨境平台合规选型适配 |
分层渐进式知识分层披露输出,按需匹配分支判断逻辑,复杂场景多维交叉核验,选型结果精准无偏差 |
|
闭环迭代范式 |
模型性能高频迭代优化、业务话术动态调优、自动化链路漏洞自测修复、能力持续升级 |
test-driven-development全域TDD驱动开发 |
全程采用强硬刚性指令约束模型输出,配套合规借口反向反驳校验机制,边运行边自测,闭环迭代无断点 |
|
接力棒循环范式 |
企业长线数字化攻坚项目、多岗位协同联动办公、跨周期分段闭环推进、权责分层落地 |
stitch-loop长线项目专属联动机制 |
全流程文件化固化状态台账管理,节点无缝接力流转,权责清晰可溯源,全程长效稳定不脱节 |
|
阶段门控范式 |
新品全链路产品深度探索、商业化可行性研判、前置风险筛查、多技能联动编排投产 |
discovery-process标准化商业探索全流程 |
全链路多维度合规+实效双项检查,刚性阶段门控卡点放行,多Skill智能联动编排,投产零隐患 |




脑图

即刻复用落地:https://github.com/anthropics/skills
https://support.claude.com/en/articles/12512198-how-to-create-custom-skills
#AIAgent #技能工程 #企业智能自动化 #AI工作流落地 #大模型实操赋能
文章摘自:https://www.cnblogs.com/wintersun/p/19946522