上一篇我们介绍了坐标注意力 CA,它通过沿两个方向分别池化来保留空间位置信息。
同样,我们可以总结一下它实现混合注意力的逻辑:
CA 的做法本质上是一种隐式编码,它通过池化整合空间特征,学习权重并注入的逻辑让模型间接感知到空间信息,实现混合注意力。
如果再站高点,我们会发现一个更基础的问题:
模型究竟应该如何表达空间信息?
在 CNN 路线中,这一问题通过卷积与池化的结构归纳被隐式解决。
而在之前的 Transformer 路线中,则通过位置编码 PE 将位置信息显式注入到特征表示中。
现在,我们再回到 Transformer 路线的位置编码演化中:
从原始 Transformer 的正余弦固定编码,到 ViT 的可学习位置编码,虽然更加灵活,但其根本逻辑是相通的:
PE 描述的是“每个位置是什么”,而不是“位置之间是什么关系”。
也就是说,这是一种绝对位置编码,这在 NLP 中存在优化空间,当扩展到二维的 CV 任务中,更出现了新的局限性:
在视觉中,”绝对位置”的语义本身就是不稳定的。同一只猫,在图像左上角和右下角,它的绝对位置编码完全不同,但网络应该以相同的逻辑去处理它。
卷积的设计只关注相对位置,因此规避了这一问题,而 Transformer 的解决方案就是:相对位置编码(Relative Position Encoding,RPE)。
实际上,在之前的 Swin 中 RPE 的逻辑就已经被应用,这几篇展开 RPE 的相关逻辑,串联之前的 Swin,作为之后的混合架构的前置内容。
1. RPE
18 年的论文: Self-Attention with Relative Position Representations 中首次将相对位置编码引入了 Transformer 的自注意力机制,它的核心思路是这样的:
在注意力计算过程中额外引入两组可学习的向量 \(\mathbf{r}^K, \mathbf{r}^V\),分别用于修改 key 和 value 的表示。
分点展开如下:
1.1 相对位置参数表
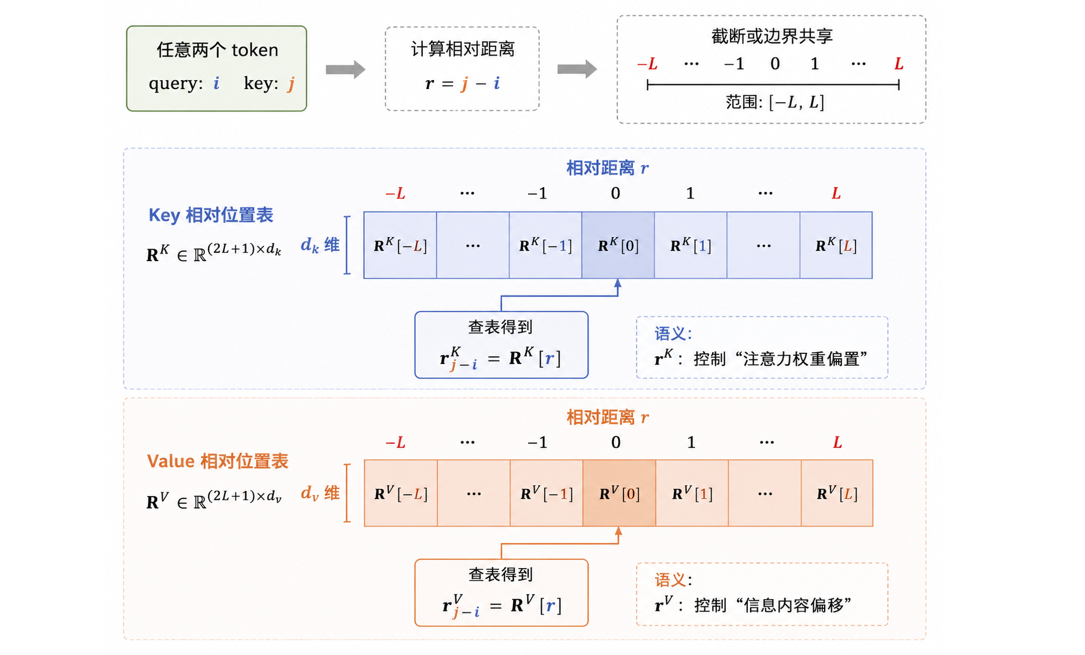
显然, \(\mathbf{r}^K\) 和 \(\mathbf{r}^V\) 不是凭空出现,我们为其定义了分别定义了一个相对位置参数表。
具体来说,假设我们限制最大相对距离为 \(L\)(比如 -10 到 +10),那么模型会定义两个参数表:
- Key 相对位置表:\(\mathbf{R}^K \in \mathbb{R}^{(2L+1)\times d_k}\)
- Value 相对位置表:\(\mathbf{R}^V \in \mathbb{R}^{(2L+1)\times d_v}\)
不难理解,\(2L+1\) 就是最大相对距离里的各种取值可能,\(d\) 就是表示维度。
现在,对任意两个 token:
\[\text{query}:i \quad \text{key}:j \]
计算相对距离为:
\[r = j – i \]
超过范围就会截断或边界共享,然后查表:
\[\mathbf{r}^K_{j-i} = \mathbf{R}^K[r] \]
\[\mathbf{r}^V_{j-i} = \mathbf{R}^V[r] \]
这就是两组可学习的向量的由来。而它们各自的语义是这样的:
- \(\mathbf{r}^K\) : 控制“注意力权重偏置”。
- \(\mathbf{r}^V\) : 控制“信息内容偏移”。

下面就展开结构,看看如何实现这两组参数的语义。
1.2 加入到注意力打分中的 \(\mathbf{r}^K\)
在标准注意力里,打分函数是:
\[e_{ij} = \frac{\mathbf{q}_i \cdot \mathbf{k}_j}{\sqrt{d_k}} \]
加法型 RPE 的第一步,是把 key 改写成:
\[\mathbf{k}_j \rightarrow \mathbf{k}_j + \mathbf{r}^K_{j-i} \]
代入后得到:
\[e_{ij} = \frac{\mathbf{q}_i \cdot (\mathbf{k}_j + \mathbf{r}^K_{j-i})}{\sqrt{d_k}} \]
展开后的结构是这样的:
\[e_{ij} = \frac{\mathbf{q}_i \cdot \mathbf{k}_j}{\sqrt{d_k}} + \frac{\mathbf{q}_i \cdot \mathbf{r}^K_{j-i}}{\sqrt{d_k}} \]
显然,原本的注意力分数只反应“语义相似度”,而现在又多了一项“距离相关性”。
1.3 加入聚合计算中的 \(\mathbf{r}^V\)
\(\mathbf{r}^K\) 作用在权重计算阶段,而 \(\mathbf{r}^V\) 作用在信息聚合阶段。
已知得到注意力权重后,聚合信息的标准输出为:
\[\mathbf{z}_i = \sum_j \alpha_{ij} \mathbf{v}_j \]
现在,RPE 将 value 改写为:
\[\mathbf{v}_j \rightarrow \mathbf{v}_j + \mathbf{r}^V_{j-i} \]
于是输出变成了:
\[\mathbf{z}_i = \sum_j \alpha_{ij} (\mathbf{v}_j + \mathbf{r}^V_{j-i}) \]
我们知道 value 本身的语义是 token 携带的真实信息, \(\mathbf{r}^V\) 在这里与其加和,就是在注入学习得到的相对位置信息。
总结来说,最初的 RPE 的核心逻辑是这样的:
建模相对距离,在 K/V 表示空间中注入“相对位置向量偏置”,让注意力从“内容函数”变成“内容 + 位置函数”。
2. RPE 的局限
在最初的 RPE 逻辑中,所有位置信息只能以“线性加法”的方式影响注意力,无法形成更复杂的非线性交互。
而且其依赖固定长度的相对位置表 \(\mathbf{R}^K, \mathbf{R}^V\),当序列长度超出训练范围时只能截断或共享边界 embedding,导致外推能力较弱。
于是,在 RPE 提出后,就出现了分裂式的发展趋势,其中有简要的结构增强,有从一维到二维的推广,还有重构式的新型设计,涉及方向较广,我们以时间线顺序在后几篇展开。
文章摘自:https://www.cnblogs.com/Goblinscholar/p/20001211