作者:vivo 互联网大数据团队- You Shuo
本文是《vivo Pulsar万亿级消息处理实践》系列文章第2篇,Pulsar支持上报分区粒度指标,Kafka则没有分区粒度的指标,所以Pulsar的指标量级要远大于Kafka。在Pulsar平台建设初期,提供一个稳定、低时延的监控链路尤为重要。
系列文章:
本文是基于Pulsar 2.9.2/kop-2.9.2展开的。
一、背景
作为一种新型消息中间件,Pulsar在架构设计及功能特性等方面要优于Kafka,所以我们引入Pulsar作为我们新一代的消息中间件。在对Pulsar进行调研的时候(比如:性能测试、故障测试等),针对Pulsar提供一套可观测系统是必不可少的。Pulsar的指标是面向云原生的,并且官方提供了Prometheus作为Pulsar指标的采集、存储和查询的方案,但是使用Prometheus采集指标面临以下几个问题:
-
Prometheus自带的时序数据库不是分布式的,它受单机资源的限制;
-
Prometheus 在存储时序数据时消耗大量的内存,并且Prometheus在实现高效查询和聚合计算的时候会消耗大量的CPU。
除了以上列出的可观测系统问题,Pulsar还有一些指标本身的问题,这些问题包括:
-
Pulsar的订阅积压指标单位是entry而不是条数,这会严重影响从Kafka迁移过来的用户的使用体验及日常运维工作;
-
Pulsar没有bundle指标,因为Pulsar自动均衡的最小单位是bundle,所以bundle指标是调试Pulsar自动均衡参数时重要的观测依据;
-
kop指标上报异常等问题。
针对以上列出的几个问题,我们在下面分别展开叙述。
二、Pulsar监控告警系统架构
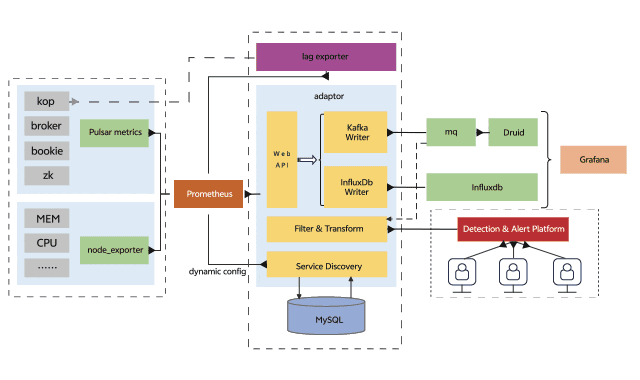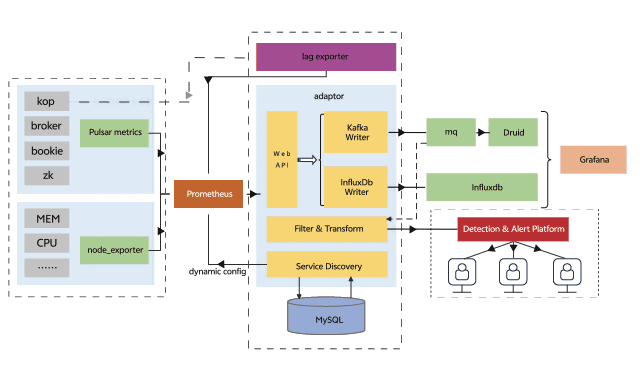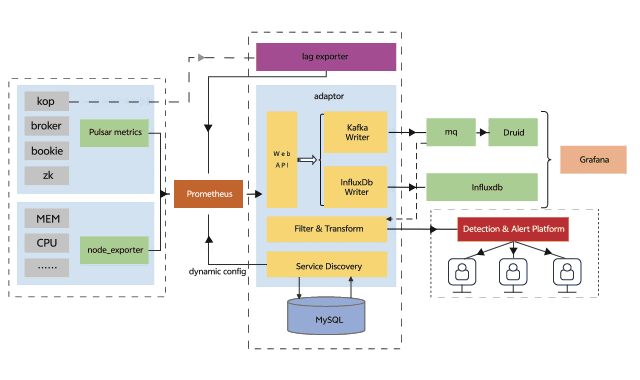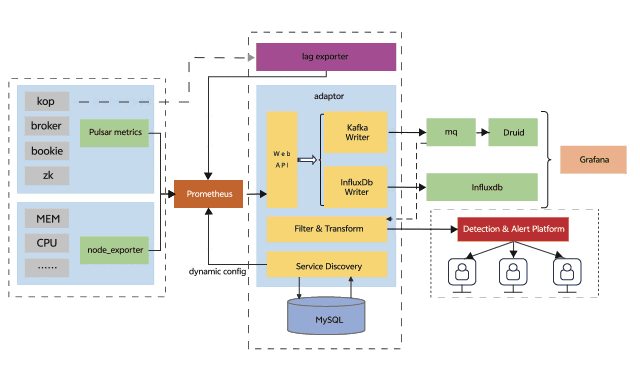
在上一章节我们列出了使用Prometheus作为观测系统的局限,由于Pulsar的指标是面向云原生的,采用Prometheus采集Pulsar指标是最好的选择,但对于指标的存储和查询我们使用第三方存储来减轻Prometheus的压力,整个监控告警系统架构如下图所示:
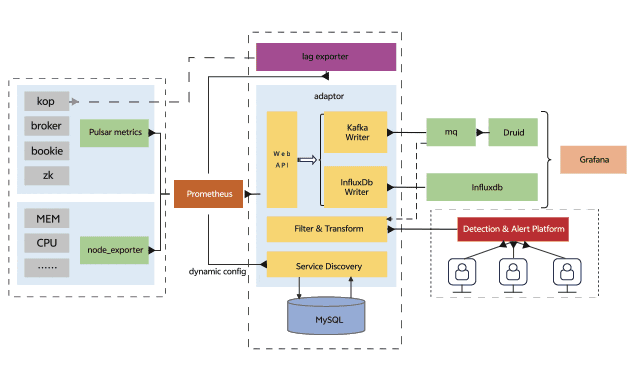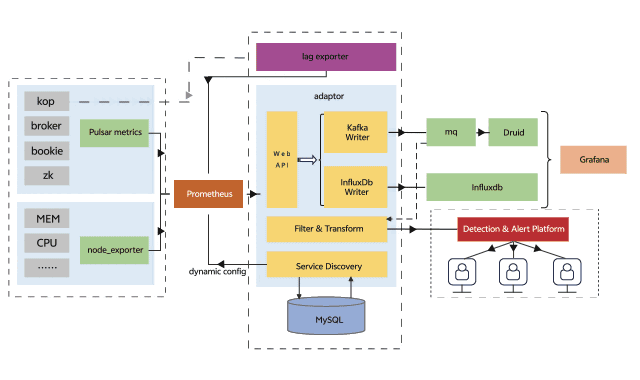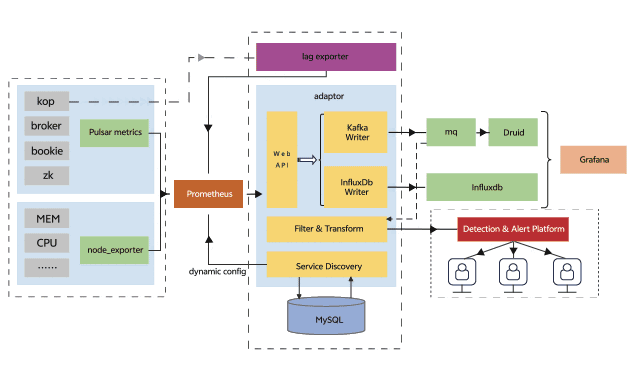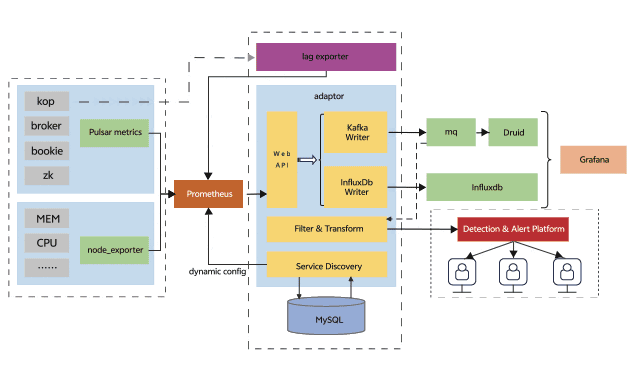
在整个可观测系统中,各组件的职能如下:
-
Pulsar、bookkeeper等组件提供暴露指标的接口
-
Prometheus访问Pulsar指标接口采集指标
-
adaptor提供了服务发现、Prometheus格式指标的反序列化和序列化以及指标转发远端存储的能力,这里的远端存储可以是Pulsar或Kafka
-
Druid消费指标topic并提供数据分析的能力
-
vivo内部的检测告警平台提供了动态配置检测告警的能力
基于以上监控系统的设计逻辑,我们在具体实现的过程中遇到了几个比较关键的问题:
一、adaptor需要接收Pulsar所有线上服务的指标并兼容Prometheus格式数据,所以在调研Prometheus采集Pulsar指标时,我们基于Prometheus的官方文档开发了adaptor,在adaptor里实现了服务加入集群的发现机制以及动态配置prometheus采集新新加入服务的指标:
-
Prometheus动态加载配置:Prometheus配置-官方文档
-
Prometheus自定义服务发现机制:Prometheus自定义服务发现-官方文档
在可以动态配置Prometheus采集所有线上正在运行的服务指标之后,由于Prometheus的指标是基于protobuf协议进行传输的,并且Prometheus是基于go编写的,所以为了适配Java版本的adaptor,我们基于Prometheus和go提供的指标格式定义文件(remote.proto、types.proto和gogo.proto)生成了Java版本的指标接收代码,并将protobuf格式的指标反序列化后写入消息中间件。
二、Grafana社区提供的Druid插件不能很好的展示Counter类型的指标,但是bookkeeper上报的指标中又有很多是Counter类型的指标,vivo的Druid团队对该插件做了一些改造,新增了计算速率的聚合函数。
druid插件的安装可以参考官方文档(详情)
三、由于Prometheus比较依赖内存和CPU,而我们的机器资源组又是有限的,在使用远端存储的基础上,我们针对该问题优化了一些Prometheus参数,这些参数包括:
–storage.tsdb.retention=30m:该参数配置了数据的保留时间为30分钟,在这个时间之后,旧的数据将会被删除。
–storage.tsdb.min-block-duration=5m:该参数配置了生成块(block)的最小时间间隔为5分钟。块是一组时序数据的集合,它们通常被一起压缩和存储在磁盘上,该参数间接控制Prometheus对内存的占用。
–storage.tsdb.max-block-duration=5m:该参数配置了生成块(block)的最大时间间隔为5分钟。如果一个块的时间跨度超过这个参数所设的时间跨度,则这个块将被分成多个子块。
–enable-feature=memory-snapshot-on-shutdown:该参数配置了在Prometheus关闭时,自动将当前内存中的数据快照写入到磁盘中,Prometheus在下次启动时读取该快照从而可以更快的完成启动。
三、Pulsar 指标优化
Pulsar的指标可以成功观测之后,我们在日常的调优和运维过程中发现了一些Pulsar指标本身存在的问题,这些问题包括准确性、用户体验、以及性能调优等方面,我们针对这些问题做了一些优化和改造,使得Pulsar更加通用、易维护。
3.1 Pulsar消费积压指标
原生的Pulsar订阅积压指标单位是entry,从Kafka迁移到Pulsar的用户希望Pulsar能够和Kafka一样,提供以消息条数为单位的积压指标,这样可以方便用户判断具体的延迟大小并尽量不改变用户使用消息中间件的习惯。
在确保配置brokerEntryMetadataInterceptors=
org.apache.pulsar.common.intercept.AppendIndexMetadataInterceptor情况下,Pulsar broker端在往bookkeeper端写入entry前,通过拦截器往entry的头部添加索引元数据,该索引在同一分区内单调递增,entry头部元数据示例如下:
biz-log-partition-1 -l 24622961 -e 6
Batch Message ID: 24622961:6:0
Publish time: 1676917007607
Event time: 0
Broker entry metadata index: 157398560244
Properties:
"X-Pulsar-batch-size 2431"
"X-Pulsar-num-batch-message 50"
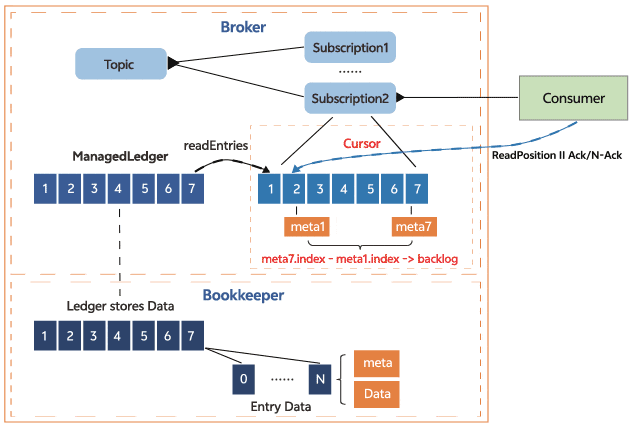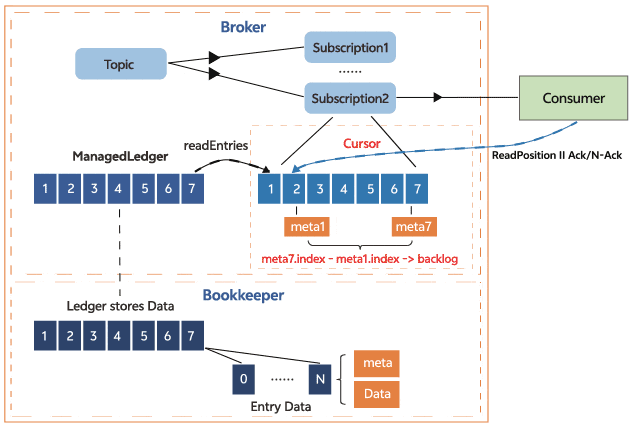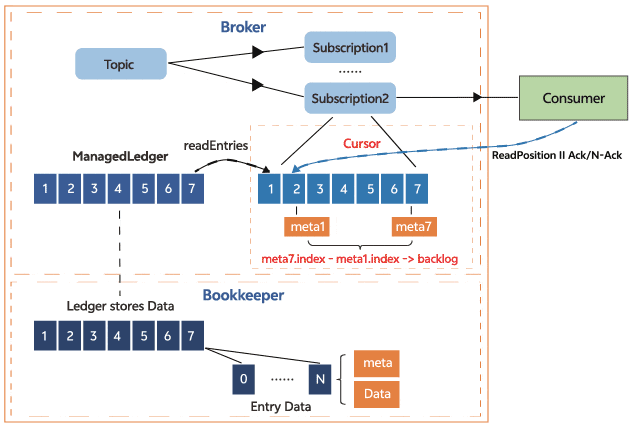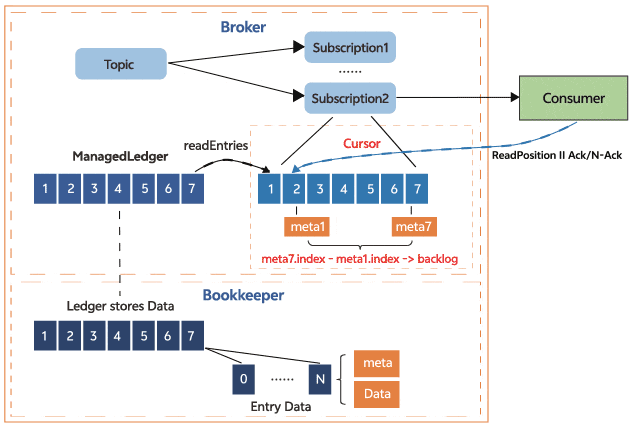
以分区为指标统计的最小单位,基于last add confirmed entry和last consumed entry计算两个entry中的索引差值,即是订阅在每个分区的数据积压。下面是cursor基于订阅位置计算订阅积压的示意图,其中last add confirmed entry在拦截器中有记录最新索引,对于last consumed entry,cursor需要从bookkeeper中读取,这个操作可能会涉及到bookkeeper读盘,所以在收集延迟指标的时候可能会增加采集的耗时。
效果
上图是新订阅积压指标和原生积压指标的对比,新增的订阅积压指标单位是条,原生订阅积压指标单位是entry。在客户端指定单条发送100w条消息时,订阅积压都有明显的升高,当客户端指定批次发送100w条消息的时候,新的订阅积压指标会有明显的升高,而原生订阅积压指标相对升高幅度不大,所以新的订阅积压指标更具体的体现了订阅积压的情况。

3.2 Pulsar bundle指标
Pulsar相比于Kafka增加了自动负载均衡的能力,在Pulsar里topic分区是绑定在bundle上的,而负载均衡的最小单位是bundle,所以我们在调优负载均衡策略和参数的时候比较依赖bunlde的流量分布指标,并且该指标也可以作为我们切分bundle的参考依据。我们在开发bundle指标的时候做了下面两件事情:
统计当前Pulsar集群非游离状态bundle的负载情况对于处于游离状态的bundle(即没有被分配到任何broker上的bundle),我们指定Pulsar leader在上报自身bundle指标的同时,上报这些处于游离状态的bundle指标,并打上是否游离的标签。
效果

上图就是bundle的负载指标,除了出入流量分布的情况,我们还提供了生产者/消费者到bundle的连接数量,以便运维同学从更多角度来调优负载均衡策略和参数。
3.3 kop消费延迟指标无法上报
在我们实际运维过程中,重启kop的Coordinator节点后会偶发消费延迟指标下降或者掉0的问题,从druid查看上报的数据,我们发现在重启broker之后消费组就没有继续上报kop消费延迟指标。
(1)原因分析
由于kop的消费延迟指标是由Kafka lag exporter采集的,所以我们重点分析了Kafka lag exporter采集消费延迟指标的逻辑,下图是Kafka-lag-exporter采集消费延迟指标的示意图:
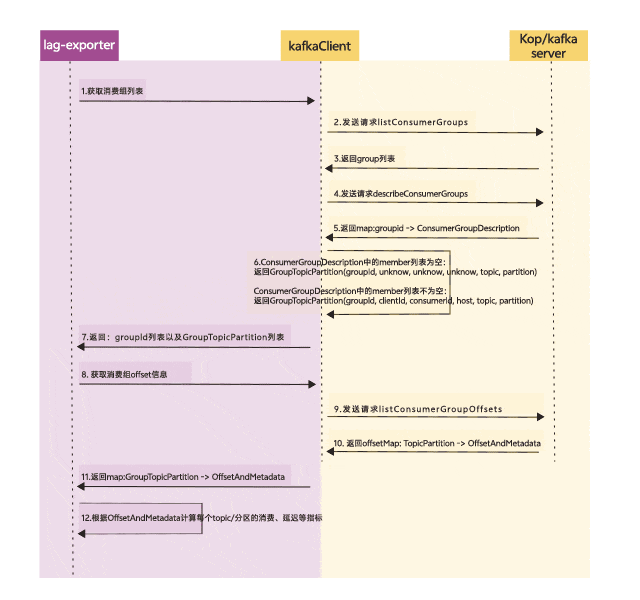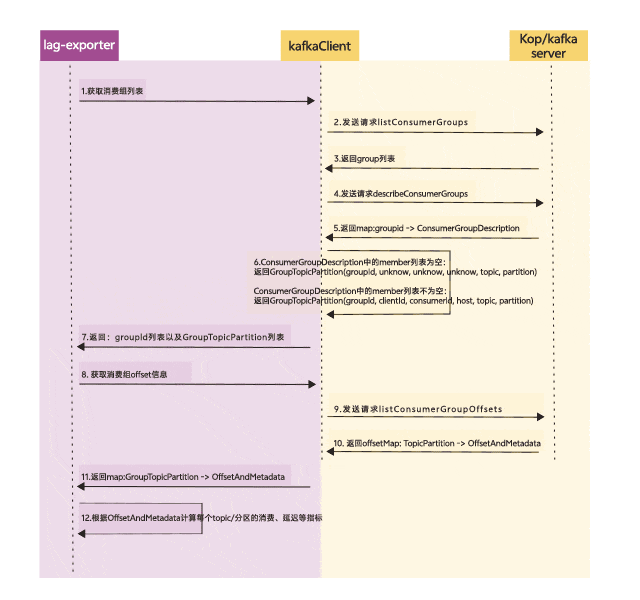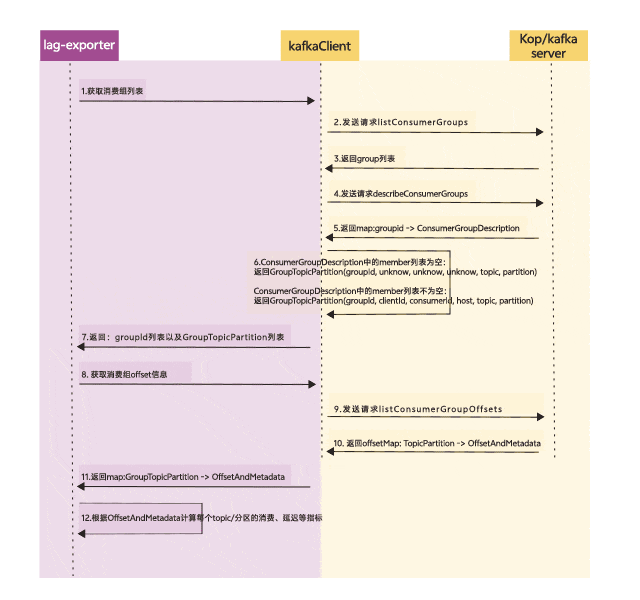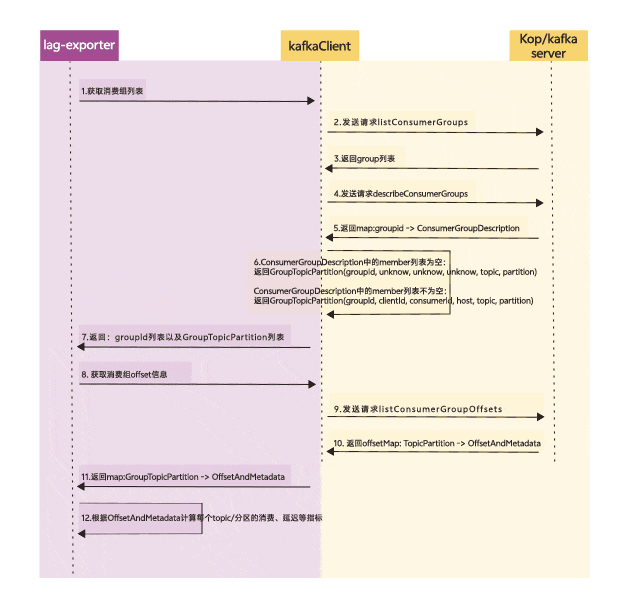
其中,kafka-lag-exporter计算消费延迟指标的逻辑会依赖kop的describeConsumerGroups接口,但是当GroupCoordinator节点重启后,该接口返回的member信息中assignment数据缺失,kafka-lag-exporter会将assignment为空的member给过滤掉,所以最终不会上报对应member下的分区指标,代码调试如下图所示:


为什么kop/Kafka describeConsumerGroups接口返回member的assignment是空的?因为consumer在启动消费时会通过groupManager.storeGroup写入__consumer_
offset,在coordinator关闭时会转移到另一个broker,但另一个broker并没有把assignment字段反序列化出来(序列化为groupMetadataValue,反序列化为readGroupMessageValue),如下图:
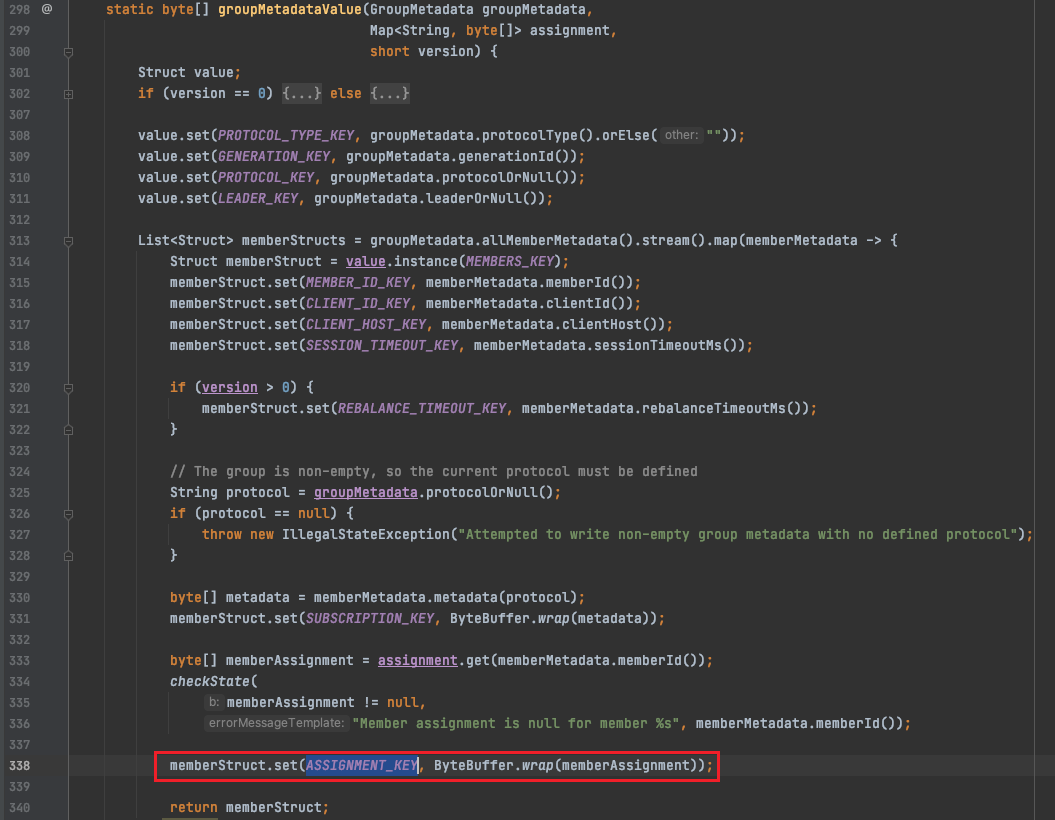
(2)解决方案
在GroupMetadataConstants#readGroup-
MessageValue()方法对coordinator反序列化消费组元数据信息时,将assignment字段读出来并设置(序列化为groupMetadataValue,反序列化为readGroupMessageValue),如下图:
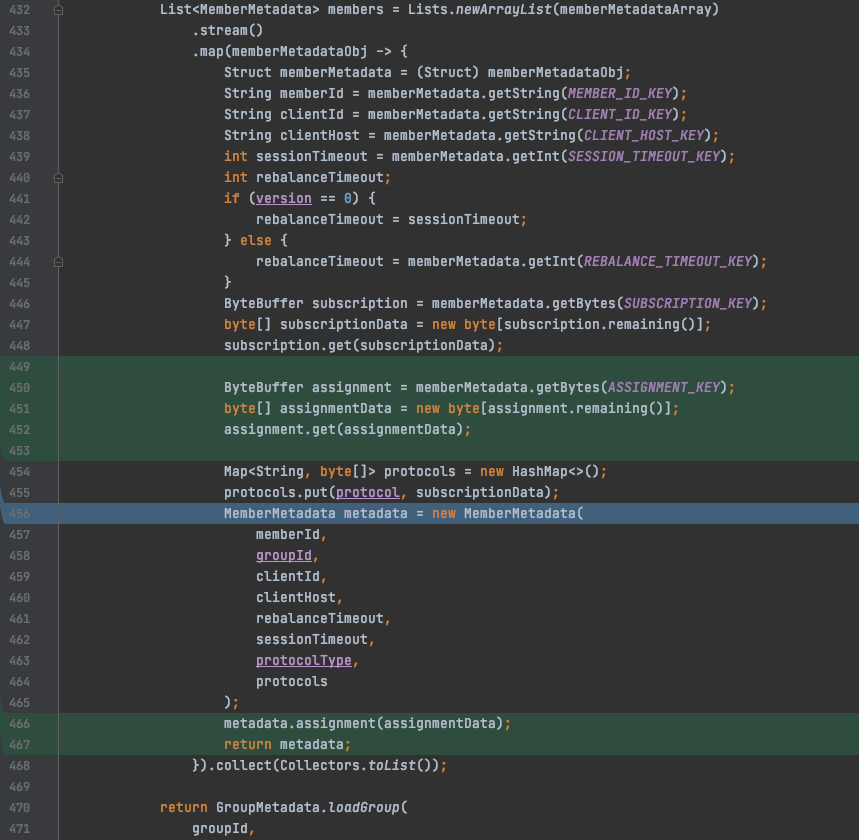
四、总结
在Pulsar监控系统构建的过程中,我们解决了与用户体验、运维效率、Pulsar可用性等方面相关的问题,加快了Pulsar在vivo的落地进度。虽然我们在构建Pulsar可观测系统过程中解决了一部分问题,但是监控链路仍然存在单点瓶颈等问题,所以Pulsar在vivo的发展未来还会有很多挑战。