关于ArrayList的元素插入、检索、修改、删除、扩容等可视化操作过程
还有关于ArrayList的迭代器、线程安全和时间复杂度
1. 底层数据结构
基于动态数组实现,内部维护一个Object[]数组。本质是数组数据结构,底层通过拷贝扩容使得数组具备了动态增大的特性。
数组所具备的一些特性,ArrayList也同样具备,比如、插入元素的有序性、访问元素的地址计算等。ArrayList与普通数组的本质区别就在于它的动态扩容特性。
集合内可以保存什么类型元素?保存的是什么? 这点必须明确知道集合必须保存引用类型的元素,对于基本类型是无法保存的,比如、int、long类型,但可以保持对应的基本类型的封装类,比如,Integer、Long。集合内保存的是对象的引用,而非对象本身。
1.1. ArrayList的特性
有底层数据结构所决定的特性
-
插入元素的有序性,而非排序,不会自动根据值排序;
-
元素访问:通过数组“首地址+下标”来计算元素的存储地址,再通过元素地址直接访问,时间复杂度都是O(1);
-
数组一但申请空间就确定不可变,所以ArrayList需要在添加元素操作时,实现自动扩容。
1.2. 如何设计的数据结构
以下是ArrayList类结构与字段
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, Serializable {
private static final long serialVersionUID = 8683452581122892189L;
/** 默认初始容量 */
private static final int DEFAULT_CAPACITY = 10;
/** 空实例数组(无延迟扩容) */
private static final Object[] EMPTY_ELEMENTDATA = {};
/** 默认构造后首次扩容使用的空数组 */
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
/** 阈值:最大数组大小 */
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
/** 真正存储元素的数组;构造时或赋予 EMPTY_* 共享数组 */
transient Object[] elementData;
/** 当前元素个数 */
private int size;
/** 用于 Fail-Fast 的修改计数器 */
protected transient int modCount;
// …
}
真正存储元素的成员变量Object[] elementData和保存数组大小的size,其它字段多半服务于动态扩容。
MAX_ARRAY_SIZE = Integer.MAX_VALUE – 8为什么减8?因为数组头需要占用一些空间,8位刚好一个字节,故最小减8,使得ArrayList尽可能存储更多数据,但正常开发不可能保存这么大数据集合,Integer.MAX_VALUE可以保持十亿级了,你减个1024都没问题。
modCount用于记录扩容次数,在迭代器中若存在并发修改,则快速失效抛出异常。
我们从本质去学习技术:集合的作用是什么?
集合的作用是将数据以特定结构存储在内存中,并且方便开发者进行操作。
-
存储:开辟内存空间,写入数据;在Java语言中无需开发者手动申请内存空间,只需要关注数据写入即可;
-
操作:无非就是增删查改,只不过现在操作的是内存中的数据罢了。
2. 元素插入(增)
方法分类
ArrayList的add方法有两个重载版本,对应不同的用法:
-
add(E e)—— 在数组末尾插入;
-
add(int index, E element)—— 在指定索引下标插入。
2.1. 在数组末尾插入
使用方法add(E e),以下是jdk8的源码
public boolean add(E e) {
ensureCapacityInternal(size + 1);
elementData[size++] = e;
return true;
}
插入数据的过程
-
调用ensureCapacityInternal确保数组足够大;
-
将元素写入elementData[size];
-
size++并返回。
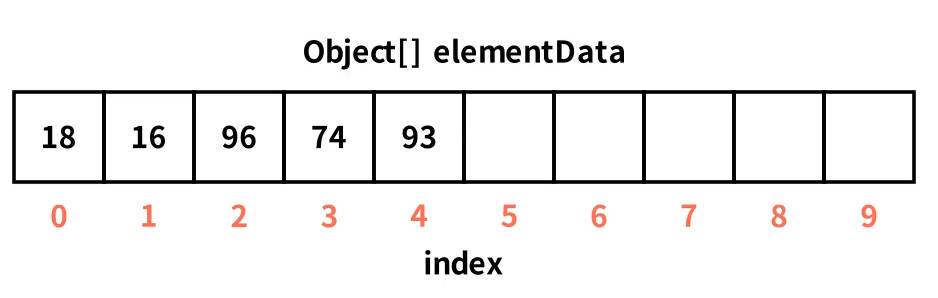
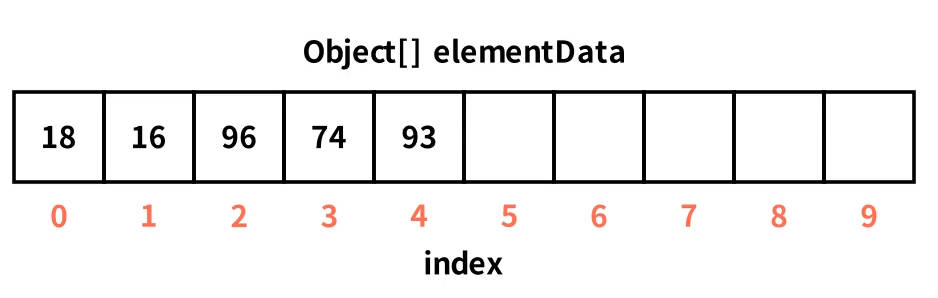
可视化感受下:无参构造创建ArrayList集合,然后插入五个元素,首次add需要扩容数组为10(详细的扩容流程看后面章节),效果如图
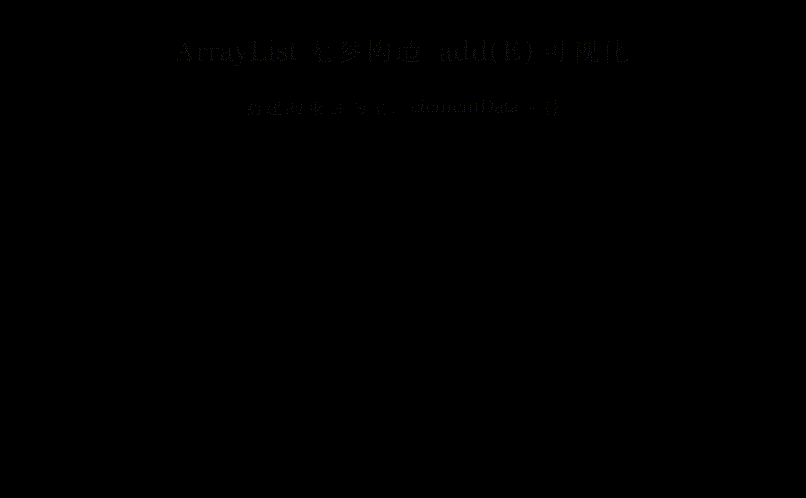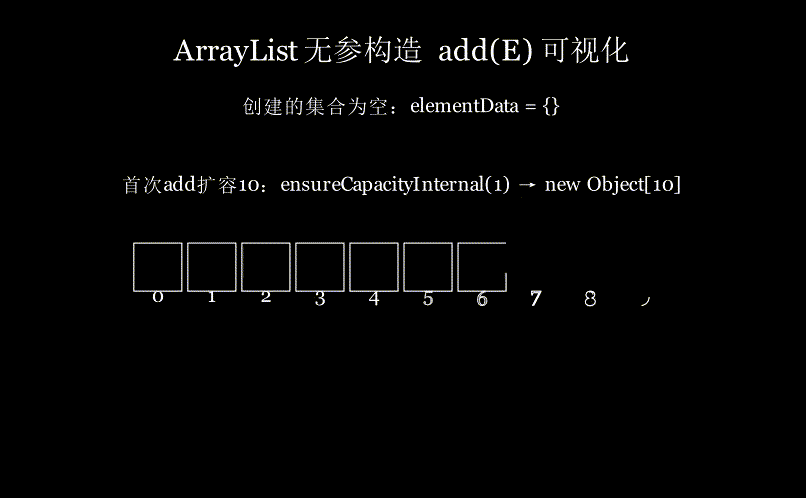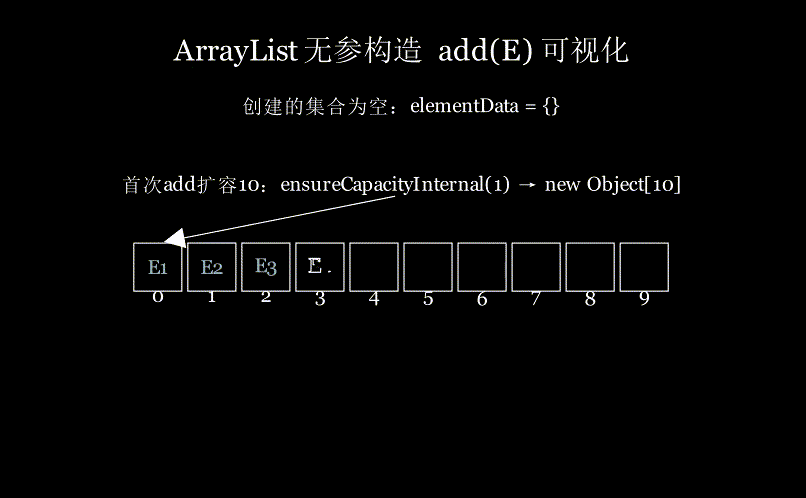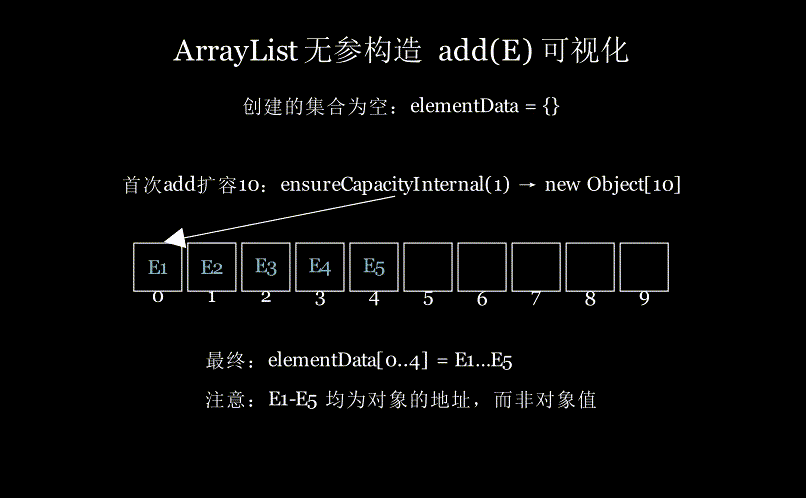
2.2. 指定索引下标插入
使用方法:add(int index, E element)
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}
插入数据的过程
-
检查是否越界;
-
调用ensureCapacityInternal确保数组足够大;
-
将坐标index后的元素都往后移动一位;
-
将元素写入elementData[size];
-
size++。
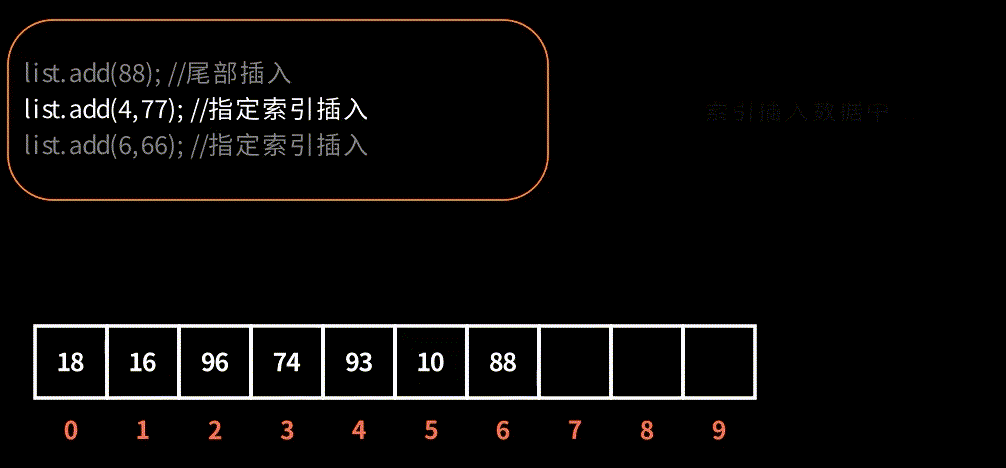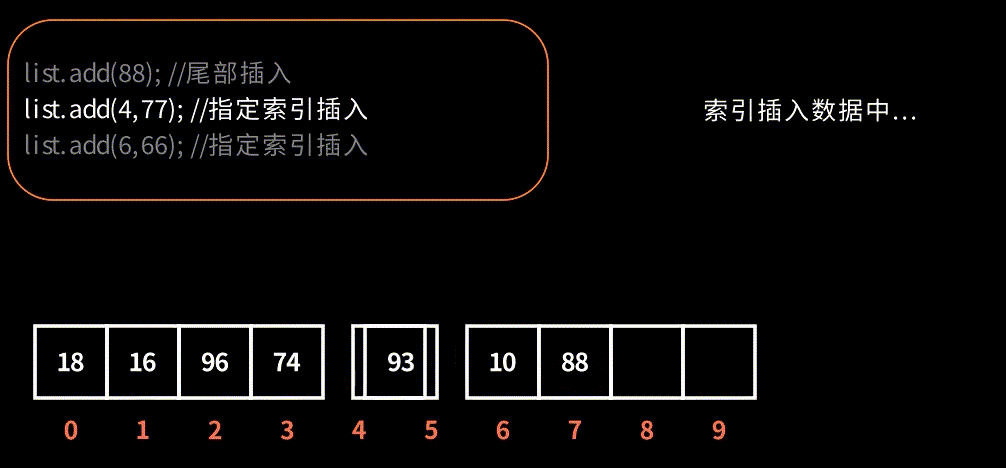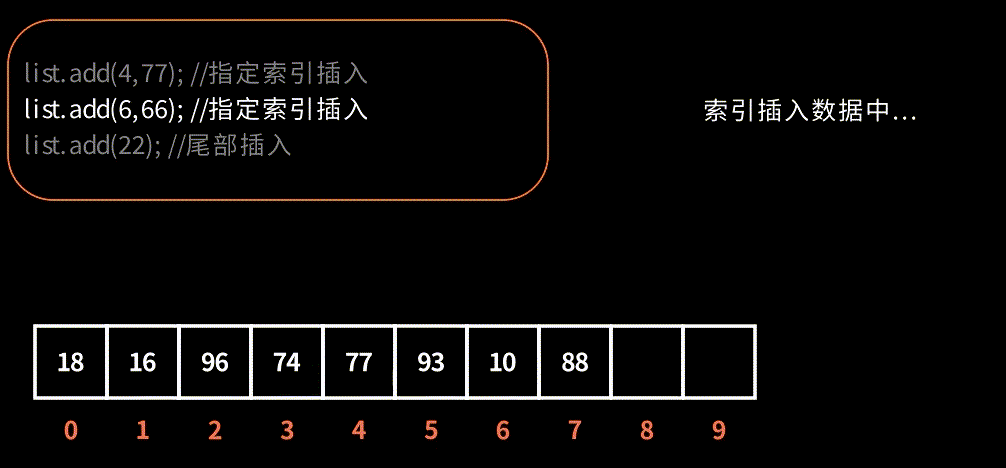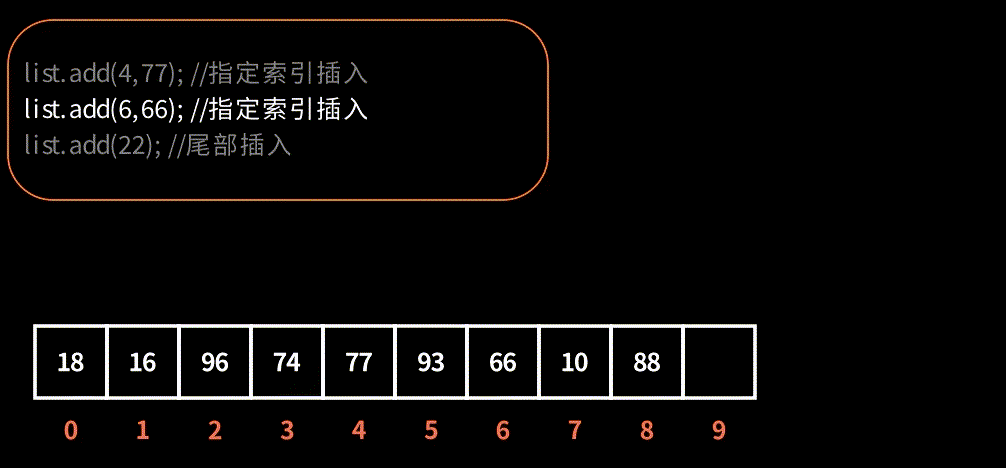
演示在索引下标插入元素,效果如图:
2.3. ensureCapacityInternal 与 grow 扩容流程
为了好查阅源码,简单调整了下,jdk源码基本如下
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
// 延迟初始化:第一次调用 ensureCapacity 时,将容量至少设置为 DEFAULT_CAPACITY(10)
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++; // 用于迭代时快速失败
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// 旧容量
int oldCapacity = elementData.length;
// 新容量 = 旧容量 + 旧容量>>1 (1.5 倍扩容)
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
// 最大容量检查(防止溢出)
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}
-
延迟初始化:无参构造后elementData引用一个长度为 0 的共享常量数组。
-
modCount:每次结构修改(如扩容、增删)都会自增,配合迭代器检查并发修改。
-
扩容策略:oldCapacity + (oldCapacity >> 1),右移一位等于除于2,所以newCapacity为原来的1.5 倍,以权衡空间和拷贝成本。
ArrayList如果不指定大小初始大小为0,首次add才进行首次扩容,扩容大小为10,这个默认的初始容量DEFAULT_CAPACITY在首层插入数据才会使用到。故此,在创建ArrayList时最好指定大小,最佳情况是创建时就知道集合的大小。
详细可见构造方法源码
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
// 指定初始容量大于0时
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
// 无参构造方法
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
扩容可视化过程:插入第11个元素的扩容过程

2.4. 扩容时才对modCount 自增合理吗?
不合理。因为你插入新的数据没有扩容的情况下,集合申请的内存空间不变,但是集合保存元素的大小发生了变化,这和移除元素一样,集合也是发生了变化的,所以在后续的jdk版本中,add操作加入了modCount++;。
以下是jdk11的add源码:首行就对modCount做了自增
public boolean add(E e) {
modCount++;
add(e, elementData, size);
return true;
}
2.5. 允许null和可重复插入?
ArrayList集合内保存的是对象的引用,在Java语言中,引用是可以指向null的,故ArrayList集合可以保存null。在元素插入时并没有对元素进行重复检查,故可以保存重复数据,包括重复的null。
List接口在 javadoc 里就明确说了:
允许所有元素(包括null),允许重复插入;
如果你需要“元素唯一”或“禁止空值”,Java 提供了其他集合类型(如实现了Set接口的HashSet/LinkedHashSet/TreeSet,或者在 Java 9+ 可以用List.of(…)构造的不可空、不可变的列表)
实现简单高效
ArrayList底层用一块连续的Object[]数组存储元素:
-
插入null只不过是往数组里赋一个null,跟存任何其他对象没区别;
-
重复插入只是把同一个引用赋给不同索引,也没有额外开销;
如果强行在add()里做“非空检查”或“去重”,不仅会增加每次插入的开销,还会破坏它作为通用、轻量列表的设计初衷。
3. 修改元素(改)
根据指定索引进行覆盖E set(int index, E element)
public E set(int index, E element) {
rangeCheck(index);
E oldValue = elementData(index);
elementData[index] = element;
return oldValue;
}
这个很简单,检查是否越界,暂存旧值,覆盖数组对应下标的值,返回旧值。
修改索引元素可视化过程:

4. 移除元素(删)
方法分类
ArrayList的remove方法有两个重载版本,对应不同的用法:
-
remove(int index)—— 按索引删除;
-
remove(Object o)—— 按对象值删除。
4.1. 指定索引删除
使用到的方法:remove(int index)
public E remove(int index) {
rangeCheck(index); // 检查索引是否合法
modCount++; // 修改次数+1,支持 fail-fast
E oldValue = elementData(index); // 获取旧值
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index + 1, elementData, index, numMoved);
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}
分析:
-
使用System.arraycopy()将后面所有元素向前移动一位;
-
最坏情况是删除索引 0,移动 n-1 个元素;
-
修改 size,清除最后一个元素引用。
删除索引元素的可视化过程:

4.2. 按照对象值删除
使用到的方法:remove(Object o)
public boolean remove(Object o) {
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
fastRemove(index);
return true;
}
} else {
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
}
配套的fastRemove(int index)实现如下:
private void fastRemove(int index) {
modCount++;
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index + 1, elementData, index, numMoved);
elementData[--size] = null;
}
分析:
-
先线性查找目标元素,最多比较n次;
-
然后移除元素,最多移动n-1个;
-
所以总操作是一次“线性查找 + 线性移动”。
避免在大列表中频繁删除中间元素(尤其在循环中删除),否则容易退化为 O(n²)。
对比按照索引删除,多了一步元素查找对比,其它基本一致。
按照对象值删除元素的可视化过程:

5. 获取和检索元素(查)
5.1. 获取元素
根据索引获取元素:get(int index)
public E get(int index) {
rangeCheck(index);
return elementData(index);
}
检查是否越界,然后根据下标索引获取元素。
5.2. 检索元素
在ArrayList中,检索某个元素(不是通过索引,而是查找某个值是否存在,或其位置)主要通过以下两个方法完成:
1) 判断是否包含某个元素
根据对象值判断集合中是否存在:contains(Object o)
public boolean contains(Object o) {
return indexOf(o) >= 0;
}
这个方法内部调用了indexOf方法。它返回一个布尔值,表示某个元素是否存在于列表中。
2) 返回元素首次出现的索引
根据对象值检索首次出现的位置:indexOf(Object o)
跟按照对象值删除的检索过程一致,可查看上面的可视化过程动图。
public int indexOf(Object o) {
if (o == null) {
for (int i = 0; i < size; i++)
if (elementData[i] == null)
return i;
} else {
for (int i = 0; i < size; i++)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
如果查找的是null,就用==比较;如果是非null对象,则用equals()方法逐个比较。从头遍历,找到第一个匹配项的索引。
3) 返回元素最后一次出现的索引
根据对象值检索最后出现的位置:lastIndexOf(Object o)
public int lastIndexOf(Object o) {
if (o == null) {
for (int i = size - 1; i >= 0; i--)
if (elementData[i] == null)
return i;
} else {
for (int i = size - 1; i >= 0; i--)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
与indexOf类似,但从尾部开始向前查找。
6. ArrayList 的迭代器(Iterator)
6.1. 什么是迭代器?
迭代器(Iterator)是 Java 集合框架中用于遍历集合元素的工具。
ArrayList提供了两种主要的迭代方式:
-
Iterator<E>:基础的迭代器接口(只支持单向遍历)
-
ListIterator<E>:是Iterator的子接口,支持双向遍历、修改元素、获取索引等高级功能
6.2. iterator迭代器
源码(位于ArrayList.java):
public Iterator<E> iterator() {
return new Itr();
}
这会返回一个内部类Itr的实例。
1) Itr 内部类的核心源码(简化版):
private class Itr implements Iterator<E> {
int cursor = 0; // 下一个要返回的元素索引
int lastRet = -1; // 上一个返回的元素索引,若没有则为 -1
int expectedModCount = modCount; // 用于检测并发修改
public boolean hasNext() {
return cursor != size;
}
public E next() {
checkForComodification();
int i = cursor;
if (i >= size)
throw new NoSuchElementException();
cursor = i + 1;
return (E) elementData[lastRet = i];
}
public void remove() {
if (lastRet < 0)
throw new IllegalStateException();
checkForComodification();
ArrayList.this.remove(lastRet);
cursor = lastRet;
lastRet = -1;
expectedModCount = modCount;
}
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}
2)modCount与并发修改检查(fail-fast)
-
modCount是ArrayList中用于记录结构性修改(如添加、删除元素)次数的字段。
-
迭代器创建时保存了当前的modCount到expectedModCount。
-
如果在迭代期间集合发生结构性修改,modCount != expectedModCount,就会抛出ConcurrentModificationException。
这就是所谓的 fail-fast机制。
3) 示例代码
List<String> list = new ArrayList<>();
list.add("A");
list.add("B");
list.add("C");
Iterator<String> it = list.iterator();
while (it.hasNext()) {
String s = it.next();
System.out.println(s);
}
6.3. ListIterator更强大的双向迭代器
1) 增强版迭代器简述
通过list.listIterator()或者listIterator(int index)来获取,本质都是返回new ListItr(index)对象。ListItr是Itr的子类)private class ListItr extends Itr implements ListIterator<E>,是增强版迭代器。
ListIterator<String> it = list.listIterator();
while (it.hasNext()) {
System.out.println(it.next());
}
while (it.hasPrevious()) {
System.out.println(it.previous());
}
额外支持:
-
hasPrevious(),previous()
-
add(E e),remove(),set(E e)
-
nextIndex(),previousIndex()
2) 示例代码
反序遍历案例
import java.util.ArrayList;
import java.util.List;
import java.util.ListIterator;
public class ListIteratorReverseDemo {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("Dog");
list.add("Cat");
list.add("Bird");
list.add("Fish");
System.out.println("原始列表: " + list);
ListIterator<String> iterator = list.listIterator(list.size()); // 从末尾开始
while (iterator.hasPrevious()) {
String animal = iterator.previous();
// 替换元素
if (animal.equals("Cat")) {
iterator.set("Tiger"); // 将 Cat 替换为 Tiger
}
// 删除元素
if (animal.equals("Bird")) {
iterator.remove(); // 删除 Bird
}
// 在 Fish 前插入一个元素
if (animal.equals("Fish")) {
iterator.add("Whale"); // 插入 Whale(在 Fish 之前)
}
}
System.out.println("修改后的列表: " + list);
}
}
6.4. 时间复杂度
-
每个迭代器的next()、hasNext()操作时间复杂度都是 O(1)。
-
但是若在remove()中触发ArrayList的remove(index),那是 O(n),因为后面的元素要移动。
6.5. 注意事项
-
在使用for-each或iterator遍历时,不要直接修改原始集合(如调用add()、remove()),否则会抛出ConcurrentModificationException。
-
如果需要在遍历中安全地修改集合,可以使用 ListIterator的remove()或add()方法,它是支持修改的。
7. 线程安全问题
ArrayList是线程不安全的。
举个例子
List<Integer> list = new ArrayList<>();
Runnable task = () -> {
for (int i = 0; i < 1000; i++) {
list.add(i); // 非线程安全
}
};
Thread t1 = new Thread(task);
Thread t2 = new Thread(task);
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println("最终大小: " + list.size()); // 不一定是 2000
不过只有ArrayList作为共享变量时,才需要考虑线程安全问题,当ArrayList集合作为方法内的局部变量时,无需考虑线程安全的问题。
解决安全问题的一些方法
类注释中推荐我们使用Collections#synchronizedList来保证线程安全,SynchronizedList 是通过在每个方法上面加上锁来实现,虽然实现了线程安全,但是性能大大降低。
使用方式
List<Integer> syncList = Collections.synchronizedList(new ArrayList<>());
// 遍历时手动加锁
synchronized(syncList) {
for (Integer i : syncList) {
// 安全遍历
}
}
也可以使用这个集合:CopyOnWriteArrayList(推荐用于读多写少)
List<String> cowList = new CopyOnWriteArrayList<>();
特性:
-
所有写操作(add/remove/set)都会复制一份数组再修改;
-
不会抛出ConcurrentModificationException;
-
非常适合读多写少的场景。
缺点:
- 写操作开销大,性能比ArrayList差很多。
8. 时间复杂度汇总
| 操作 | 时间复杂度 | 备注 |
|---|---|---|
| 插入元素 | O(1),扩容单次为 O(n) | add(E) |
| 随机插入 | O(n),元素拷贝 | add(index,E) |
| 指定索引删除 | O(n),指定索引删除 | remove(index) |
| 指定对象值删除 | O(n),查找 + 移动 | remove(Object) |
| 指定索引修改 | O(1) | set(index,E) |
| 获取元素 | O(1) | get(index) |
| 检索元素 | 都为O(n) | indexOf(Object)/ lastIndexOf(Object) |
9. 总结
在使用ArrayList集合时,需要关注以下特性:随机获取/修改快、插入/删除慢、扩容性能问题、并发线程安全问题。
关于元素插入、检索、修改、删除、扩容过程等操作过程,完整的视频链接:https://www.bilibili.com/video/BV1KET2zGEm4/

查看往期设计模式文章的:设计模式
觉得还不错的,三连支持:点赞、分享、推荐↓