深度学习利器:TensorFlow与NLP模型
作者:武维 2017-08-16 10:57:52
人工智能
深度学习 自然语言处理(简称NLP),是研究计算机处理人类语言的一门技术,NLP技术让计算机可以基于一组技术和理论,分析、理解人类的沟通内容。传统的自然语言处理方法涉及到了很多语言学本身的知识,而深度学习,是表征学习(representation learning)的一种方法,在机器翻译、自动问答、文本分类、情感分析、信息抽取、序列标注、语法解析等领域都有广泛的应用。
前言
自然语言处理(简称NLP),是研究计算机处理人类语言的一门技术,NLP技术让计算机可以基于一组技术和理论,分析、理解人类的沟通内容。传统的自然语言处理方法涉及到了很多语言学本身的知识,而深度学习,是表征学习(representation learning)的一种方法,在机器翻译、自动问答、文本分类、情感分析、信息抽取、序列标注、语法解析等领域都有广泛的应用。
2013年末谷歌发布的word2vec工具,将一个词表示为词向量,将文字数字化,有效地应用于文本分析。2016年谷歌开源自动生成文本摘要模型及相关TensorFlow代码。2016/2017年,谷歌发布/升级语言处理框架SyntaxNet,识别率提高25%,为40种语言带来文本分割和词态分析功能。2017年谷歌官方开源tf-seq2seq,一种通用编码器/解码器框架,实现自动翻译。本文主要结合TensorFlow平台,讲解TensorFlow词向量生成模型(Vector Representations of Words);使用RNN、LSTM模型进行语言预测;以及TensorFlow自动翻译模型。
Word2Vec数学原理简介
我们将自然语言交给机器学习来处理,但机器无法直接理解人类语言。那么首先要做的事情就是要将语言数学化,Hinton于1986年提出Distributed Representation方法,通过训练将语言中的每一个词映射成一个固定长度的向量。所有这些向量构成词向量空间,每个向量可视为空间中的一个点,这样就可以根据词之间的距离来判断它们之间的相似性,并且可以把其应用扩展到句子、文档及中文分词。
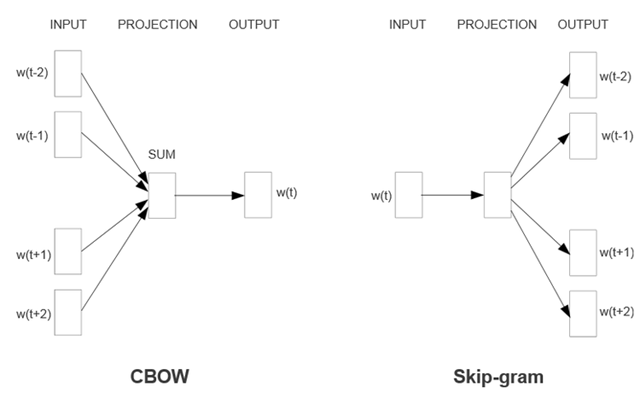
Word2Vec中用到两个模型,CBOW模型(Continuous Bag-of-Words model)和Skip-gram模型(Continuous Skip-gram Model)。模型示例如下,是三层结构的神经网络模型,包括输入层,投影层和输出层。

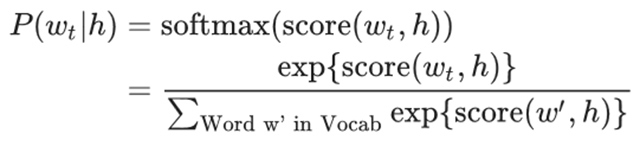
其中score(wt, h),表示在的上下文环境下,预测结果是的概率得分。上述目标函数,可以转换为极大化似然函数,如下所示:
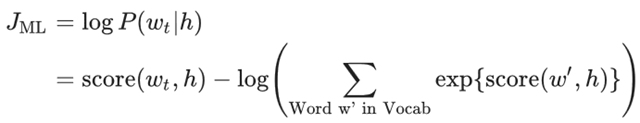
求解上述概率模型的计算成本是非常高昂的,需要在神经网络的每一次训练过程中,计算每个词在他的上下文环境中出现的概率得分,如下所示:
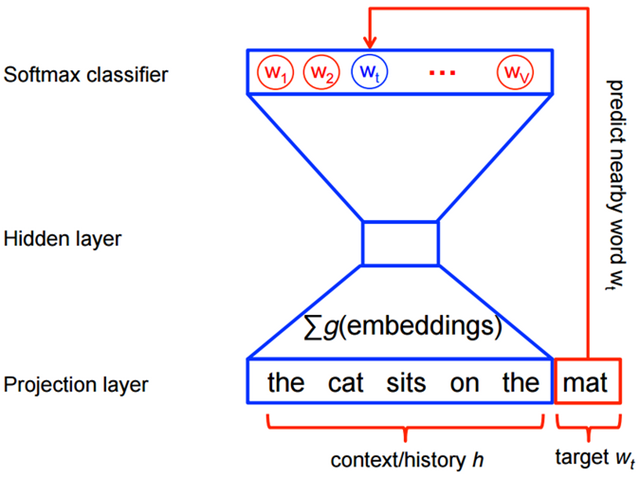
然而在使用word2vec方法进行特性学习的时候,并不需要计算全概率模型。在CBOW模型和skip-gram模型中,使用了逻辑回归(logistic regression)二分类方法进行的预测。如下图CBOW模型所示,为了提高模型的训练速度和改善词向量的质量,通常采用随机负采样(Negative Sampling)的方法,噪音样本w1,w2,w3,wk…为选中的负采样。
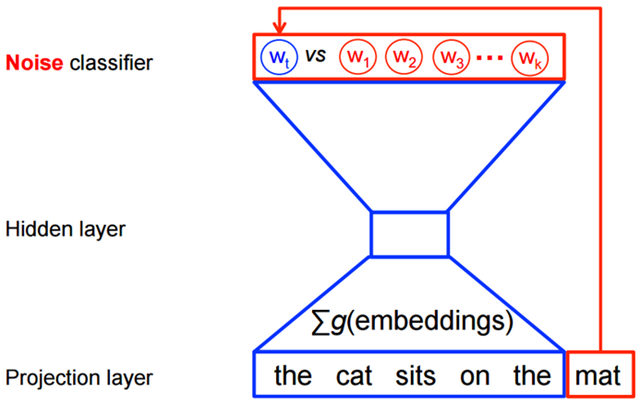
TensorFlow近义词模型
本章讲解使用TensorFlow word2vec模型寻找近义词,输入数据是一大段英文文章,输出是相应词的近义词。比如,通过学习文章可以得到和five意思相近的词有: four, three, seven, eight, six, two, zero, nine。通过对大段英文文章的训练,当神经网络训练到10万次迭代,网络Loss值减小到4.6左右的时候,学习得到的相关近似词,如下图所示:

下面为TensorFlow word2vec API 使用说明:
构建词向量变量,vocabulary_size为字典大小,embedding_size为词向量大小
- embeddings = tf.Variable(tf.random_uniform([vocabulary_size, embedding_size], -1.0, 1.0))
定义负采样中逻辑回归的权重和偏置
- nce_weights = tf.Variable(tf.truncated_normal
- ([vocabulary_size, embedding_size], stddev=1.0 / math.sqrt(embedding_size)))
- nce_biases = tf.Variable(tf.zeros([vocabulary_size]))
定义训练数据的接入
- train_inputs = tf.placeholder(tf.int32, shape=[batch_size])
- train_labels = tf.placeholder(tf.int32, shape=[batch_size, 1])
定义根据训练数据输入,并寻找对应的词向量
- embed = tf.nn.embedding_lookup(embeddings, train_inputs)
基于负采样方法计算Loss值
- loss = tf.reduce_mean( tf.nn.nce_loss
- (weights=nce_weights, biases=nce_biases, labels=train_labels,
- inputs=embed, num_sampled=num_sampled, num_classes=vocabulary_size))
定义使用随机梯度下降法执行优化操作,最小化loss值
- optimizer = tf.train.GradientDescentOptimizer(learning_rate=1.0).minimize(loss)
通过TensorFlow Session Run的方法执行模型训练
- for inputs, labels in generate_batch(...):
- feed_dict = {train_inputs: inputs, train_labels: labels}
- _, cur_loss = session.run([optimizer, loss], feed_dict=feed_dict)
TensorFlow语言预测模型
本章主要回顾RNN、LSTM技术原理,并基于RNN/LSTM技术训练语言模型。也就是给定一个单词序列,预测最有可能出现的下一个单词。例如,给定[had, a, general] 3个单词的LSTM输入序列,预测下一个单词是什么?如下图所示:

RNN技术原理
循环神经网络(Recurrent Neural Network, RNN)是一类用于处理序列数据的神经网络。和卷积神经网络的区别在于,卷积网络是适用于处理网格化数据(如图像数据)的神经网络,而循环神经网络是适用于处理序列化数据的神经网络。例如,你要预测句子的下一个单词是什么,一般需要用到前面的单词,因为一个句子中前后单词并不是独立的。RNN之所以称为循环神经网路,即一个序列当前的输出与前面的输出也有关。具体的表现形式为网络会对前面的信息进行记忆并应用于当前输出的计算中,即隐藏层之间的节点不再无连接而是有连接的,并且隐藏层的输入不仅包括输入层的输出还包括上一时刻隐藏层的输出。如下图所示:
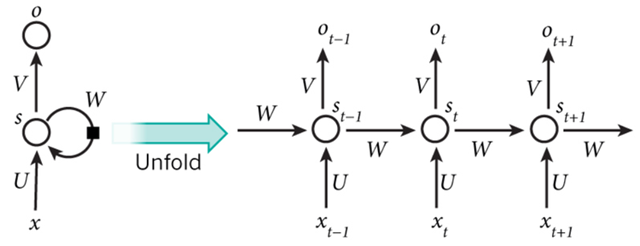

LSTM技术原理
RNN有一问题,反向传播时,梯度也会呈指数倍数的衰减,导致经过许多阶段传播后的梯度倾向于消失,不能处理长期依赖的问题。虽然RNN理论上可以处理任意长度的序列,但实习应用中,RNN很难处理长度超过10的序列。为了解决RNN梯度消失的问题,提出了Long Short-Term Memory模块,通过门的开关实现序列上的记忆功能,当误差从输出层反向传播回来时,可以使用模块的记忆元记下来。所以 LSTM 可以记住比较长时间内的信息。常见的LSTM模块如下图所示:
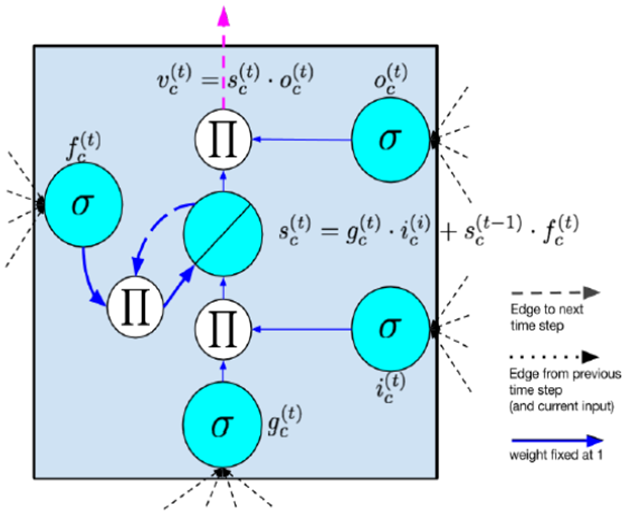

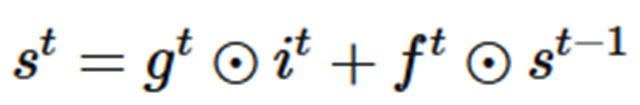
output gate类似于input gate同样会产生一个0-1向量来控制Memory Cell到输出层的输出,如下公式所示:
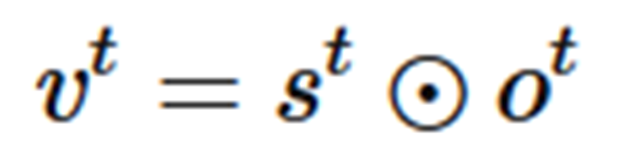
三个门协作使得 LSTM 存储块可以存取长期信息,比如说只要输入门保持关闭,记忆单元的信息就不会被后面时刻的输入所覆盖。
使用TensorFlow构建单词预测模型
首先下载PTB的模型数据,该数据集大概包含10000个不同的单词,并对不常用的单词进行了标注。
首先需要对样本数据集进行预处理,把每个单词用整数标注,即构建词典索引,如下所示:
读取训练数据
- data = _read_words(filename)
- #按照单词出现频率,进行排序
- counter = collections.Counter(data)
- count_pairs = sorted(counter.items(), key=lambda x: (-x1, x[0]))
- #构建词典及词典索引
- words, _ = list(zip(*count_pairs))
- word_to_id = dict(zip(words, range(len(words))))
接着读取训练数据文本,把单词序列转换为单词索引序列,生成训练数据,如下所示:
读取训练数据单词,并转换为单词索引序列
- data = _read_words(filename) data = [word_to_id[word] for word in data if word in word_to_id]
生成训练数据的data和label,其中epoch_size为该epoch的训练迭代次数,num_steps为LSTM的序列长度
- i = tf.train.range_input_producer(epoch_size, shuffle=False).dequeue()
- x = tf.strided_slice(data, [0, i * num_steps], [batch_size, (i + 1) * num_steps])
- x.set_shape([batch_size, num_steps])
- y = tf.strided_slice(data, [0, i * num_steps + 1], [batch_size, (i + 1) * num_steps + 1])
- y.set_shape([batch_size, num_steps])
构建LSTM Cell,其中size为隐藏神经元的数量
- lstm_cell = tf.contrib.rnn.BasicLSTMCell(size,
- forget_bias=0.0, state_is_tuple=True)
如果为训练模式,为保证训练鲁棒性,定义dropout操作
- attn_cell = tf.contrib.rnn.DropoutWrapper(lstm_cell,
- output_keep_prob=config.keep_prob)
根据层数配置,定义多层RNN神经网络
- cell = tf.contrib.rnn.MultiRNNCell( [ attn_cell for _ in range(config.num_layers)],
- state_is_tuple=True)
根据词典大小,定义词向量
- embedding = tf.get_variable("embedding",
- [vocab_size, size], dtype=data_type())
根据单词索引,查找词向量,如下图所示。从单词索引找到对应的One-hot encoding,然后红色的weight就直接对应了输出节点的值,也就是对应的embedding向量。
- inputs = tf.nn.embedding_lookup(embedding, input_.input_data)
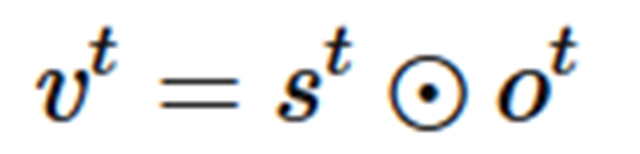
定义RNN网络,其中state为LSTM Cell的状态,cell_output为LSTM Cell的输出
- for time_step in range(num_steps):
- if time_step > 0: tf.get_variable_scope().reuse_variables()
- (cell_output, state) = cell(inputs[:, time_step, :], state)
- outputs.append(cell_output)
定义训练的loss值就,如下公式所示。
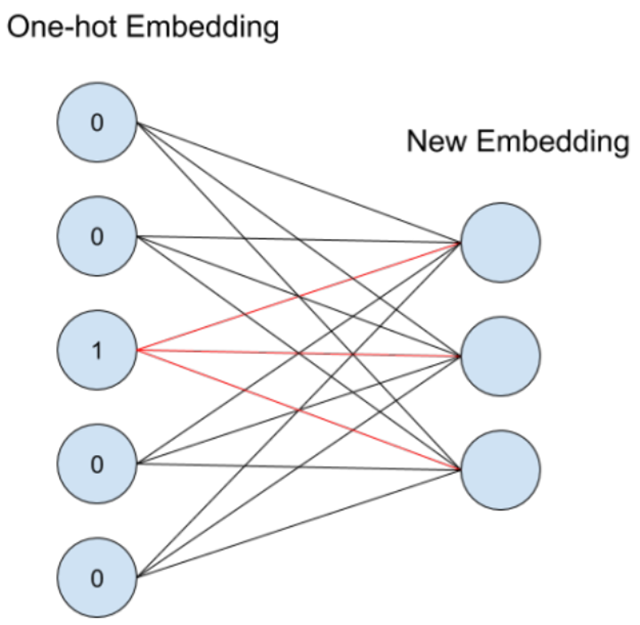
- softmax_w = tf.get_variable("softmax_w", [size, vocab_size], dtype=data_type())
- softmax_b = tf.get_variable("softmax_b", [vocab_size], dtype=data_type())
- logits = tf.matmul(output, softmax_w) + softmax_b
Loss值
- loss = tf.contrib.legacy_seq2seq.sequence_loss_by_example([logits],
- [tf.reshape(input_.targets, [-1])], [tf.ones([batch_size * num_steps], dtype=data_type())])
定义梯度及优化操作
- cost = tf.reduce_sum(loss) / batch_size
- tvars = tf.trainable_variables()
- grads, _ = tf.clip_by_global_norm(tf.gradients(cost, tvars), config.max_grad_norm)
- optimizer = tf.train.GradientDescentOptimizer(self._lr)
单词困惑度eloss
- perplexity = np.exp(costs / iters)
TensorFlow语言翻译模型
本节主要讲解使用TensorFlow实现RNN、LSTM的语言翻译模型。基础的sequence-to-sequence模型主要包含两个RNN网络,一个RNN网络用于编码Sequence的输入,另一个RNN网络用于产生Sequence的输出。基础架构如下图所示
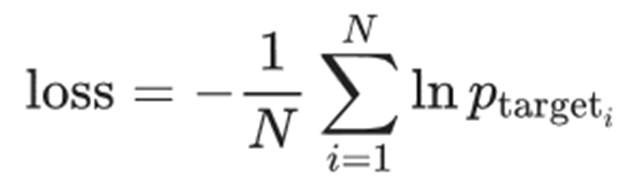
上图中的每个方框表示RNN中的一个Cell。在上图的模型中,每个输入会被编码成固定长度的状态向量,然后传递给解码器。2014年,Bahdanau在论文“Neural Machine Translation by Jointly Learning to Align and Translate”中引入了Attention机制。Attention机制允许解码器在每一步输出时参与到原文的不同部分,让模型根据输入的句子以及已经产生的内容来影响翻译结果。一个加入attention机制的多层LSTM sequence-to-sequence网络结构如下图所示:

针对上述sequence-to-sequence模型,TensorFlow封装成了可以直接调用的函数API,只需要几百行的代码就能实现一个初级的翻译模型。tf.nn.seq2seq文件共实现了5个seq2seq函数:
- basic_rnn_seq2seq:输入和输出都是embedding的形式;encoder和decoder用相同的RNN cell,但不共享权值参数;
- tied_rnn_seq2seq:同basic_rnn_seq2seq,但encoder和decoder共享权值参数;
- embedding_rnn_seq2seq:同basic_rnn_seq2seq,但输入和输出改为id的形式,函数会在内部创建分别用于encoder和decoder的embedding矩阵;
- embedding_tied_rnn_seq2seq:同tied_rnn_seq2seq,但输入和输出改为id形式,函数会在内部创建分别用于encoder和decoder的embedding矩阵;
- embedding_attention_seq2seq:同embedding_rnn_seq2seq,但多了attention机制;
embedding_rnn_seq2seq函数接口使用说明如下:
- encoder_inputs:encoder的输入
- decoder_inputs:decoder的输入
- cell:RNN_Cell的实例
- num_encoder_symbols,num_decoder_symbols:分别是编码和解码的大小
- embedding_size:词向量的维度
- output_projection:decoder的output向量投影到词表空间时,用到的投影矩阵和偏置项
- feed_previous:若为True, 只有第一个decoder的输入符号有用,所有的decoder输入都依赖于上一步的输出;
- outputs, states = embedding_rnn_seq2seq(
- encoder_inputs, decoder_inputs, cell,
- num_encoder_symbols, num_decoder_symbols,
- embedding_size, output_projection=None,
- feed_previous=False)
TensorFlow官方提供了英语到法语的翻译示例,采用的是statmt网站提供的语料数据,主要包含:giga-fren.release2.fixed.en(英文语料,3.6G)和giga-fren.release2.fixed.fr(法文语料,4.3G)。该示例的代码结构如下所示:
- seq2seq_model.py:seq2seq的TensorFlow模型采用了embedding_attention_seq2seq用于创建seq2seq模型。
- data_utils.py:对语料数据进行数据预处理,根据语料数据生成词典库;并基于词典库把要翻译的语句转换成用用词ID表示的训练序列。如下图所示:
(点击放大图像)

translate.py:主函数入口,执行翻译模型的训练
执行模型训练
- python translate.py
- --data_dir [your_data_directory] --train_dir [checkpoints_directory]
- --en_vocab_size=40000 --fr_vocab_size=40000
总结
随着TensorFlow新版本的不断发布以及新模型的不断增加,TensorFlow已成为主流的深度学习平台。本文主要介绍了TensorFlow在自然语言处理领域的相关模型和应用。首先介绍了Word2Vec数学原理,以及如何使用TensorFlow学习词向量;接着回顾了RNN、LSTM的技术原理,讲解了TensorFlow的语言预测模型;最后实例分析了TensorFlow sequence-to-sequence的机器翻译 API及官方示例。
责任编辑:庞桂玉
来源: 36大数据
深度学习
TensorFlow
NLP