除了自然语言处理,你还可以用词嵌入(Word2Vec)做这个
作者:佚名 2017-08-04 10:16:52
移动开发
机器学习
自然语言处理 尽管词嵌入(Word2Vec)技术目前主要用在自然语言处理的应用中,例如机器翻译;但本文指出,该技术还可以用于分类特征处理,把文本数据转换成便于机器学习算法直接使用的实值向量,从而提供了一种看待词嵌入(Word2Vec)应用的新视角。
当使用机器学习方法来解决问题的时候,拥有合适的数据是非常关键的。不幸的是,通常情况下的原始数据是「不干净」的,并且是非结构化的。自然语言处理(NLP)的从业者深谙此道,因为他们所用的数据都是文本的。由于大多数机器学习算法不接受原始的字符串作为输入,所以在输入到学习算法之前要使用词嵌入的方法来对数据进行转换。但这不仅仅存在于文本数据的场景,它也能够以分类特征的形式存在于其他标准的非自然语言处理任务中。事实上,我们很多人都在苦苦研究这种分类特征过程,那么词嵌入方法在这种场景中有什么作用呢?
这篇文章的目标是展示我们如何能够使用一种词嵌入方法,Word2Vec(2013,Mikolov 等),来把一个具有大量模态的分类特征转换为一组较小的易于使用的数字特征。这些特征不仅易于使用,而且能够成功学习到若干个模态之间的关系,这种关系与经典词嵌入处理语言的方式很相似。
Word2Vec
观其伴,知其意。(Firth, J. R. 1957.11)
上述内容准确地描述了 Word2Vec 的目标:它尝试通过分析一个词的邻词(也称作语境)来确定该词的含义。这个方法有两种不同风格的模型:CBOW 模型和 Skip-Gram 模型。在给定语料库的情况下,模型在每个语句的词上循环,要么根据当前单词来预测其邻词(语境),要么根据当前的语境来预测当前的词,前者所描述的方法被称作「Skip-Gram」,后者被称作「连续性词包,continuous bag of words(CBOW)」。每个语境中单词数目的极限是由一个叫做「窗大小,Window Size」的参数来决定的。
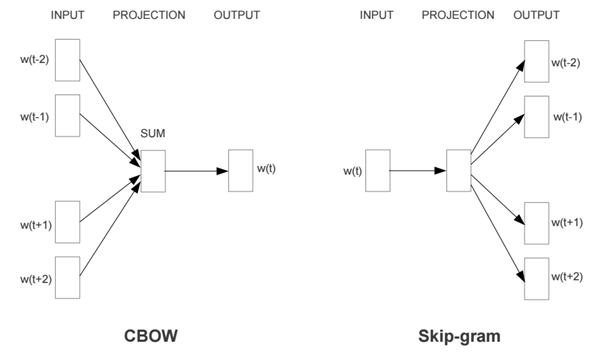
因此,如果你选择了 Skip-Gram 方法,Word2Vec 就会使用一个浅层的神经网络,也就是说,用一个只具有一个隐藏层的神经网络来学习词嵌入。网络首先会随机地初始化它的权重,然后使用单词来预测它的语境,在最小化它所犯错误的训练过程中去迭代调整这些权重。有望在一个比较成功的训练过程之后,能够通过网络权重矩阵和单词的 one-hot 向量的乘积来得到每一个单词的词向量。
注意:除了能够允许将文本数据进行数字表征之外,结果性嵌入还学习到了单词之间的而一些有趣的关系,可以被用来回答类似于下面的这种问题:国王之于王后,正如父亲之于……?
如果你想了解更多的关于 Word2Vec 的细节知识,你可以看一下斯坦福大学的课程(https://www.youtube.com/watch?v=ERibwqs9p38),或者 TensorFlow 的相关教程(https://www.tensorflow.org/tutorials/word2vec)。
应用
我们在 Kwyk 平台上(https://www.kwyk.fr/)上提供在线的数学练习。老师给他们的学生布置作业,每次练习完成的时候都会有一些数据被存储下来。然后,我们利用收集到的数据来评价每个学生的水平,并且给他们量身制作对应的复习来帮助他们进步。对于每一个被解答的练习作业,我们都保存了一系列的标识符来帮助我们区分以下信息:这是什么练习?作答的学生是谁?属于哪一个章节?……. 除此之外,我们还会根据学生是否成功地解答了这个题目来保存一个分数,要么是 0,要么是 1。然后,为了评价学生的分数,我们必须预测这个分数,并且从我们的分类器中得到学生成功的概率。
正如你所看到的,我们的很多特征都是可以分类的。通常情况下,当模态的数目足够小的时候,你可以简单地将 n 模态的分类特征转换为 n-1 维的哑变量,然后用它们去训练。但是当模态是成千上万级别的时候——就像在我们应用中的一些情况一样——依靠哑变量就显得没有效率并且不切实际。
为了解决这个问题,我们通过一个小技巧采用 Word2Vec 把分类特征转换为数量相当少的可用连续特征。为了阐述这个想法,我们以「exercise_id」为例来说明:exercise_id 是一个分类特征,它能够告诉我们被解答过的练习题是哪一个。为了能够使用 Word2Vec,我们提供一个语料库,也就是将要输入到我们的算法中的一系列句子。然而,原始的特征只是一个 ID 的列表而已,它本质上并不是语料库:它的顺序完全是随机的,相近的 ID 也并没有携带着其相邻的 ID 任何信息。我们的技巧包括把某个老师布置的一次作业看做一个「句子」,也就是一连串的 exercise_id。结果就是,所有的 ID 会很自然地以等级、章节等标签被收集在一起,然后 Word2Vec 可以直接在这些句子上面开始学习练习的嵌入(exercise embedding,对应于 Word embedding)。
事实上,正是由于这些人为的句子我们才得以使用 Word2Vec,并得到了很漂亮的结果:
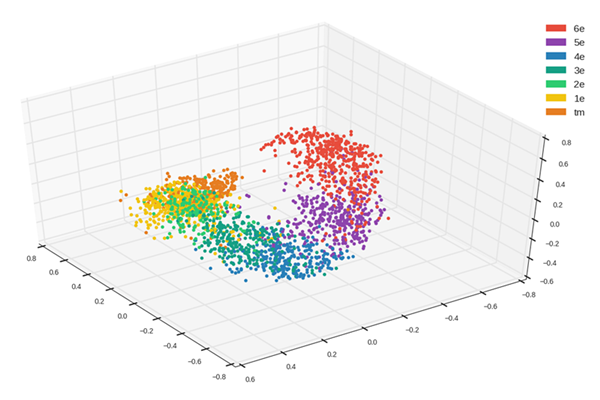
如我们所看到的的,结果性嵌入是有结构的。事实上,练习的 3D 投影云是螺旋形的,高级别的练习紧跟在较低级别的后面。这也意味着嵌入成功地学会了区分不同级别的练习题目,并且把练习题目重新分组,具有相似级别的被放在了一起。但是这还不是全部,使用非线性的降维技术之后,我们可以将整个嵌入降维成一个具有相同特征的实值变量。换句话说,我们得到了一个关于练习复杂度的特征,6 年级(6th)最小,随着练习越来越复杂,这个变量越来越大,直到 12 年级达到该变量的***值。
更有甚者,正如 Mikolov 在英语单词上做到的一样,嵌入还习得了练习之间的关系:
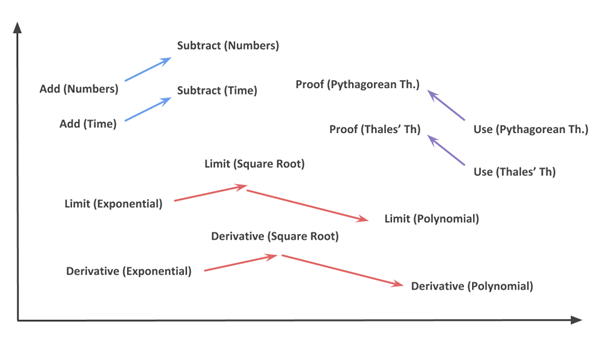
上图展示了我们的嵌入能够学习到的关系的一些实例。所以当我们问「一个数字相加的练习之于一个数字相减的练习,正如一个时间相加的练习之于……?」之后,嵌入给出了如下的答案:「一个时间相减的练习」。具体而言,这意味着如果我们提出这个问题:嵌入 [减(数字)Substract(Numbers)] –嵌入 [加(数字),Add(Numbers)],并把它添加到学生练习的嵌入中,其中学生被要求来做时间的加法(例如,小时、分钟等等),那么与之最接近的一个嵌入就是包含时间减法的练习。
结论
总之,词嵌入技术在将文本数据转换成便于机器学习算法直接使用的实值向量时是有用的,尽管词嵌入技术主要用在自然语言处理的应用中,例如机器翻译,但是我们通过给出特定的用在 Kwyk 中的例子展示了这些技术在分类特征处理中也有用武之地。然而,为了使用诸如 Word2Vec 这样的技术,你必须建立一个语料库——也就是说,一组句子,其中的标签已经被排列好了,所以其语境也是已经隐式创建好了。上述实例中,我们使用在网站上给出的作业来创建练习的「句子」,并且学习练习嵌入。结果就是,我们能够得到新的数字特征,这些特征能够成功地学习练习之间的关系,比它们被打上的那组原始标签更加有用。
向 Christophe Gabar 致谢,他是我们 Kwyk 的开发人员之一,他提出了把 word2vec 用在分类特征上的思想。
原文链接:https://medium.com/towards-data-science/a-non-nlp-application-of-word2vec-c637e35d3668