问题背景
目前推荐系统中, 在特征维度上低频特征和高频特征的维度是通过遍历mask特征获得到的auc衰减衡量特征对模型的重要度来决定的. 如果想提升模型效果, 在field层面上需要减少进行基于经验的特征维度调参, 在feasign层面上对作用不大的feasign对应的mf进行缩维, 裁剪掉冗余维度, 将对作用较大的feasign进行自动扩维.
调研方案
方案1: 启发式方法
通常基于预定义的人工规则为每个特征分配维数。根据特征出现频率来分配embedding维数。优点是实现比较简单,但其所基于的幂律分布并不能保证总是满足,因此限制了其在复杂任务中的推广
扩维主要是2种方法, 一种是线性变换(每个维度的向量经过FC后进行batch_norm), 一种是直接填0, 降维应该只能用线性变换.
我们预先设置1/4/8/16/32/64等阈值, 根据跑的全量特征重要度任务总的参数数量 计算阈值比例, 然后按降序分别分配到对应顺序的slot上.
这个阈值是个超参..同时起多组任务不断调整超参拿到最佳的那一组结果.尝试会很麻烦而且手动效率不高
方案2: Pruning方法
Auto-EDS看作嵌入剪枝问题,通过不同的剪枝策略对整个嵌入矩阵进行嵌入剪枝,从而自动获得混合维度嵌入矩阵。因此,这类方法的关键思想是通过识别并去除嵌入矩阵中的冗余参数,建立内存高效的模型,并尽可能保持准确性。虽然剪枝方法可以通过选择性地减少embedding中的参数实现维度搜索,但这些方法通常需要进行迭代优化,耗时较长(原因是因为需要加入新的mask layer用于删除和验证冗余参数. 另外还有新的参数删除阈值需要训练)
目前看到的调研成功可能性最高的论文是Single-shot Embedding Dimension Search
Single-shot Embedding Dimension Search
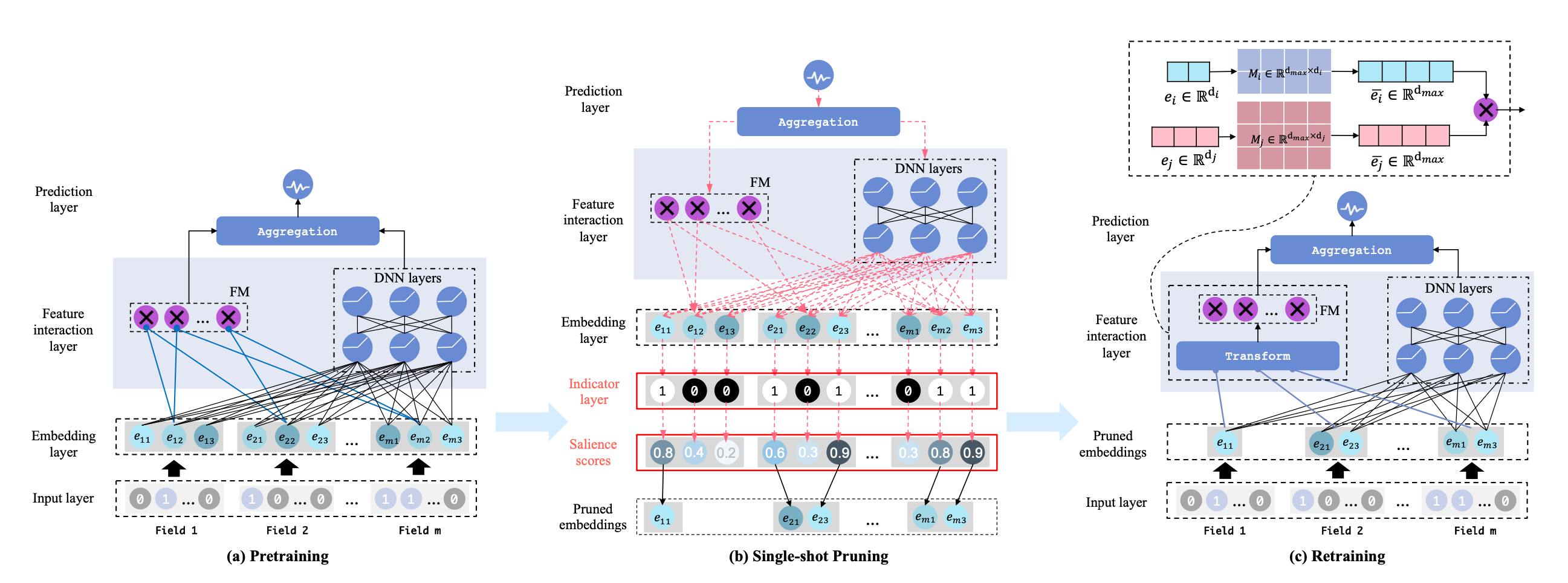
这篇文章介绍的方法主要分成3步, 用一种高效的方式在一次fp/bp内, 把所有的mf维度的重要度跑出来

第一步pretraining,把所有特征的embedding设置成等长而且一定包含冗余参数的长度, 比如都变成64维
第二步single-shot pruning, 计算每一维对离线指标的影响,降序排列, 把达到参数阈值之后的参数删除 (论文核心)
我们传统计算方法是
\(\Delta \mathcal{L}_{i, j}=\mathcal{L}(\hat{\mathbf{V}} \odot 1, \hat{\Theta} ; \mathcal{D})-\mathcal{L}\left(\hat{\mathbf{V}} \odot\left(1-\boldsymbol{\epsilon}_{i, j}\right), \hat{\Theta} ; \mathcal{D}\right)\) 即遍历所有的维度, 评估这个维度mask后对应的loss变化情况
这里做了一个优化
\(\begin{aligned} \Delta \mathcal{L}_{i, j} & \approx g_{i, j}\left(\hat{\mathbf{V}}, \hat{\Theta} ; \mathcal{D}_b\right)=\left.\frac{\partial \mathcal{L}\left(\mathbf{V} \odot \boldsymbol{\alpha}, \Theta ; \mathcal{D}_b\right)}{\partial \boldsymbol{\alpha}_{i, j}}\right|_{\boldsymbol{\alpha}=1} \\ & =\left.\lim _{\delta \rightarrow 0} \frac{\mathcal{L}\left(\hat{\mathbf{V}} \odot \boldsymbol{\alpha}, \hat{\Theta} ; \mathcal{D}_b\right)-\mathcal{L}\left(\hat{\mathbf{V}} \odot\left(\boldsymbol{\alpha}-\delta \boldsymbol{\epsilon}_{i, j}\right), \hat{\Theta} ; \mathcal{D}_b\right)}{\delta}\right|_{\boldsymbol{\alpha}=\mathbf{1}} \end{aligned}\)
, 把他约等于了这个维度的梯度, 这个在bp的时候已经算好了
最后根据梯度来算维度得分:
\(\mathbf{s}_{i, j}=\frac{\left|g_{i, j}\left(\hat{\mathbf{V}}, \hat{\Theta} ; \mathcal{D}_b\right)\right|}{\sum_{i=0}^m \sum_{j=0}^d\left|g_{i, j}\left(\hat{\mathbf{V}}, \hat{\Theta} ; \mathcal{D}_b\right)\right|}\)
把维度得分算出来后根据设定的参数量阈值就能把alpha向量算出来
\(\begin{gathered} \boldsymbol{\alpha}_{i, j}=\mathbb{I}\left(\mathbf{s}_{i, j}-\tilde{s} \geq 0\right), \forall i \in\{1, \ldots, m\}, j \in\{1, \ldots, d\} \\ \text { s.t. }\|\boldsymbol{\alpha}\|_0<\kappa\|\mathbf{V}\|_0 \end{gathered}\)
第三步retraining, 把裁剪后的重新transform后输入fm, 原因是fm需要定长输入
他这里还提到了一个重要的问题:
为啥是基于slot维度做的裁剪, 而不是feasign维度的裁剪: 原因是要求验证集必须包括所有的feasign, 但是这个基本不可能实现. 所以长尾feasign没法处理.
最后把冗余的model裁剪完成后,热启重训练, 冷启第一层dense
整体算法的流程如下:

方案3: 超参数优化(HPO)
(HPO)受神经结构搜索(NAS)在深度神经网络体系结构自动搜索方面的启发,将嵌入维度搜索视为超参数优化(HPO)问题,从预定义的候选维度集搜索嵌入维度。缺点:generally requires a well-designed search space for candidate embedding dimensions and expensive optimization processes to train the candidates
实现成本较高, 暂不考虑.