【详细内容首发于微信公众号(Hobbes View)】
什么是Embedding?
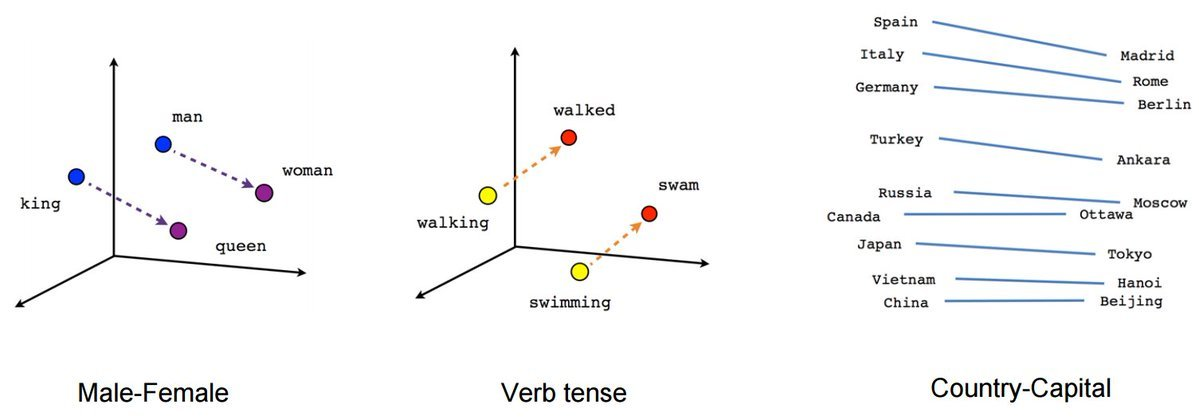
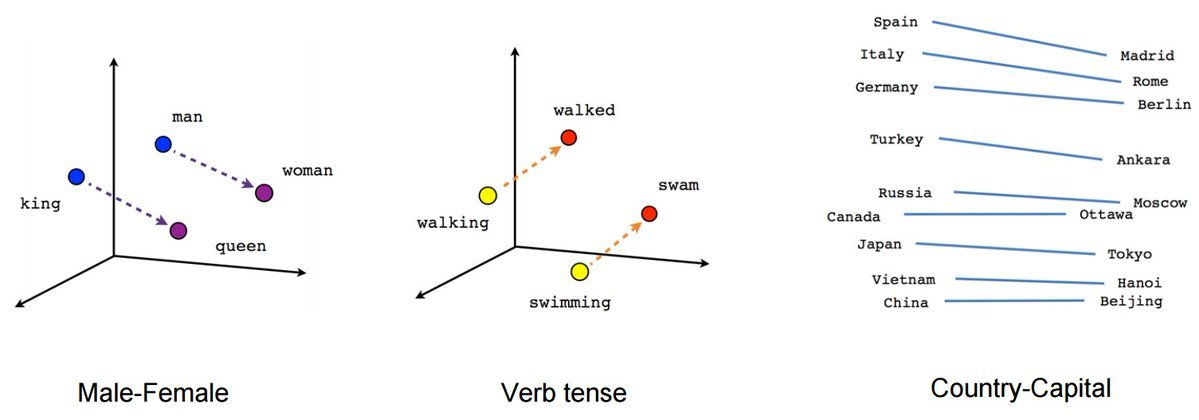
Embedding是一种多维向量数组,由一系列数字组成,可以代表任何事物,如文本、音乐、视频等。在这里我们将重点关注文本部分。Embedding之所以重要,是因为它让我们可以进行语义搜索,也就是通过文本的含义进行相似性检索。
为什么Embedding在AI中如此重要?
Embedding在AI中的重要性在于,它可以帮助我们解决LLM的tokens长度限制问题。通过使用Embedding,我们可以在与LLM交互时,仅在上下文窗口中包含相关的文本内容,从而不会超过tokens的长度限制。
如何将Embedding与LLM结合?
我们可以利用Embedding,在和LLM交互时,仅包含相关的文本内容。具体操作方法是,首先将文本内容分块并转换为向量数组,然后将其存储在向量数据库中。在回答问题时,我们可以使用相似性搜索将问题向量与文档向量进行比较,找到最相关的文本块,然后将这些文本块与问题一起输入到LLM中,得到准确的回答。
举例来说
我们可以利用Embedding,在和LLM交互时,仅包含相关的文本内容。以一个巨大的书籍PDF文件为例,假设这是一本讲述人类历史的书籍。我们希望从中提取关于某个重要历史人物的信息,但不想阅读整个文件。
具体操作方法是:
- 将PDF文件的文本内容分块。
- 使用Embedding模型将每个文本块转换为向量数组。
- 将这些向量数组存储在向量数据库中,同时保存向量数组与文本块之间的关系。
当我们需要回答关于该PDF文件的问题时,例如:“作者对xxx人物的看法是什么?”我们可以:
- 使用Embedding模型将问题转换为向量数组。
- 使用相似性搜索(如,chatGPT推荐的余弦相似度)将问题向量与PDF文件的向量进行比较,找到最相关的文本块。
- 将找到的最相关文本块与问题一起输入到LLM(如GPT-3)中,得到准确的回答。
通过这种方法,我们可以将Embedding与LLM结合,实现高效的文本搜索和问答功能。目前比较火的类chatPDF、以及文档问答产品都采用类似的技术。
产品案例
开源fireBase解决方案SupBase二月份时就推出了一款基于chatGPT API的,支持问答的文档系统(https://supabase.com/blog/chatgpt-supabase-docs)
其中就对这个文档系统的技术路径进行了相应的描述:

一些值得参考的资料
- https://openai.com/blog/introducing-text-and-code-embeddings (主要是关于基于embedding的文本与代码搜索的)
- https://github.com/openai/openai-cookbook/blob/main/examples/Question_answering_using_embeddings.ipynb (openAI提供的jupyter基于embedding的QA代码示例)
- https://supabase.com/blog/chatgpt-supabase-docs